
Жизненный срок видеокарт семейства Pascal оказался довольно долгим. Старшие модели продержались на рынке более двух лет и еще будут присутствовать некоторое время в продаже. В течение этого периода мы увидели новые решения на архитектуре Volta, которые остались уделом специализированных ускорителей вычислений. Единственным игровым продуктом семейства Volta стал TITAN V, выпущенный небольшим тиражом при чрезвычайно высокой цене. Но теперь настал момент старта нового поколения, которое должно изменить все. Новые видеокарты на архитектуре Turing не просто привносят очередное повышение производительности, они несут в себе ряд технологических инноваций и являются первыми игровыми решениями, которые поддерживают трассировку лучей в реальном времени. Поэтому даже привычное название GeForce GTX было изменено на GeForce RTX. В данном обзоре мы поговорим об особенностях архитектуры Turing и технических параметрах новых GPU. Практическому знакомству с видеокартами, включая тестирование и сравнение со старыми моделями NVIDIA, будут посвящены следующие обзоры.

Видеокарты GeForce RTX
В семействе Turing можно выделить несколько ключевых изменений. Это абсолютно новая архитектура GPU, появление новых вычислительных блоков — тензорных и RT ядер, ускоренная обработка шейдеров.

На данный момент представлено три видеокарты — GeForce RTX 2080 Ti, GeForce RTX 2080 и GeForce RTX 2070. Все они базируются на разных GPU Turing. Топовая модель получила самый мощный процессор TU102, кристалл которого изображен ниже на слайде.

Вначале приведем блок-схему каждого нового GPU, опишем общие характеристики видеокарт, а потом детально рассмотрим архитектурные изменения. Все процессоры производятся по технологии 12-нм FinFET. Они сохраняют кластерную структуру, когда GPU состоит из нескольких GPC, и, меняя количество таких кластеров, масштабируется производительность каждого конкретного чипа.
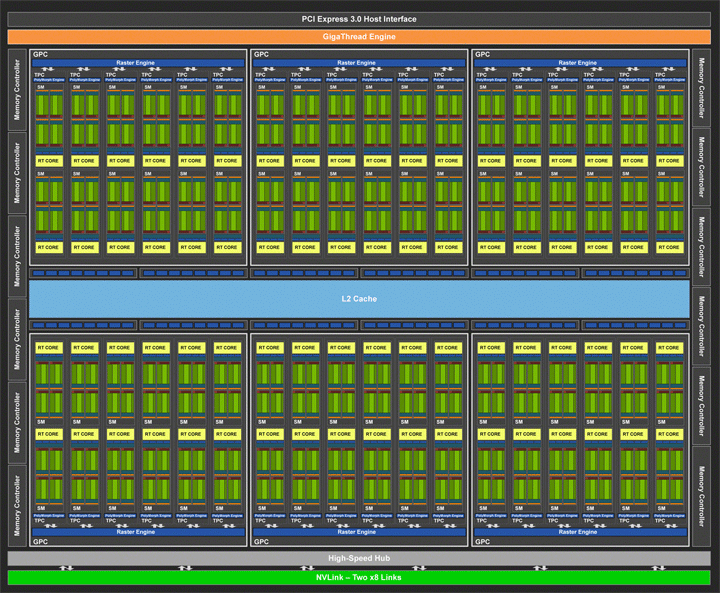
TU102 (GeForce RTX 2080 Ti)
Старший графический процессор TU102 состоит из 18,6 миллиардов транзисторов при площади кристалла 754 кв.мм. Если сравнить его с GP102 (GeForce GTX 1080 Ti), то площадь нового чипа и количество транзисторов выросло на 55–60%. У TU102 всего шесть кластеров GPC, каждый содержит по шесть текстурно-процессорных кластеров TPC, объединяющих мультипроцессорные блоки SM. Последние заметно реорганизованы и включают новые блоки, о чем подробнее будет сказано ниже. Каждый SM-блок насчитывает 64 основных вычислительных блока (CUDA-cores). При 72 SM всего получается 4608 потоковых процессоров. Однако GPU GeForce RTX 2080 Ti (как в свое время и у GeForce GTX 1080 Ti) немного урезан. У топовой видеокарты отключены два SM, в итоге общее количество потоковых процессоров равно 4352. Также у данного решения имеется 544 новых тензорных ядра и 68 RT-ядер, 272 текстурных блока и 88 блоков растеризации ROP.
Для сравнения можно напомнить, что GeForce GTX 1080 Ti на базе GP102 оперировал только 3584 ядрами CUDA при 224 текстурных блоках. Так что наращивание потенциала у нового TU102 весьма значительное. Шина памяти осталась 352-битной, но используются новые микросхемы памяти GDDR6 с эффективной частотой обмена данными, эквивалентной значению 14 ГГц. Объем памяти 11 ГБ на уровне старого флагмана, и это вполне достаточно для современных игр в высоких разрешениях.
Судя по блок-схеме у процессора TU102 всего 12 контроллеров памяти разрядностью 32 бита. Поэтому чип может работать с 384-битным интерфейсом. Возможно, мы увидим такую шину вместе с 4608 потоковыми процессорами в новых Titan. Кэш L2 у GeForce RTX 2080 Ti достигает 5632 КБ. Очевидно, что полный объем L2 равен 6 МБ, но он немного порезан вместе с шиной.
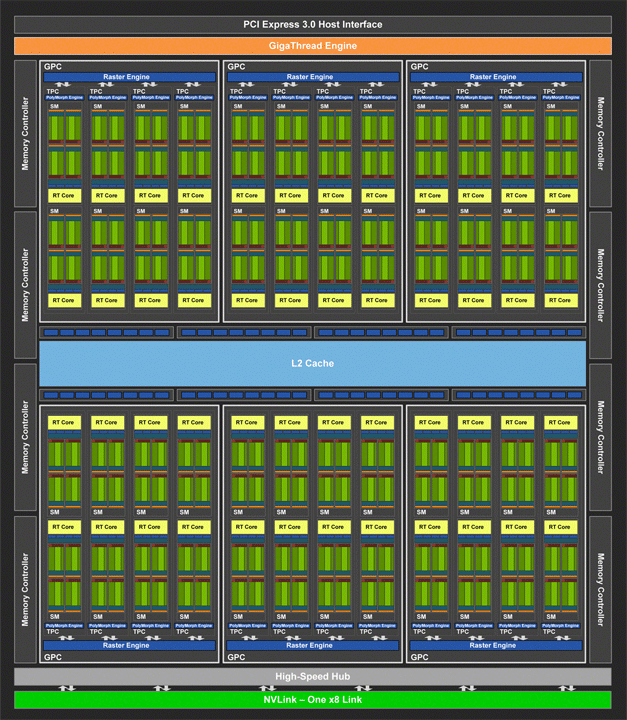
TU104 (GeForce RTX 2080)
Следующий в иерархии процессор TU104 имеет конфигурацию из шести кластеров GPC по четыре TPC. В прошлом поколении Pascal сохранялась идентичность внутренней структуры кластеров для решений среднего и топового уровня, лишь в бюджетных GPU уменьшалось количество TPC. Вероятно, такая конфигурация TU104 является оптимальной для сохранения некоего баланса производительности и гибкого управления ресурсами — число кластеров на уровне топового GPU, но они слабее. При этом задействовано 46 SM-блоков из 48, что дает 2944 активных вычислительных ядер CUDA, 368 тензорных ядер, 46 ядер RT и 184 текстурных блока. Объем кэш-памяти L2 равен 4 МБ, что вдвое выше объема L2 у GP102 (GeForce GTX 1080).
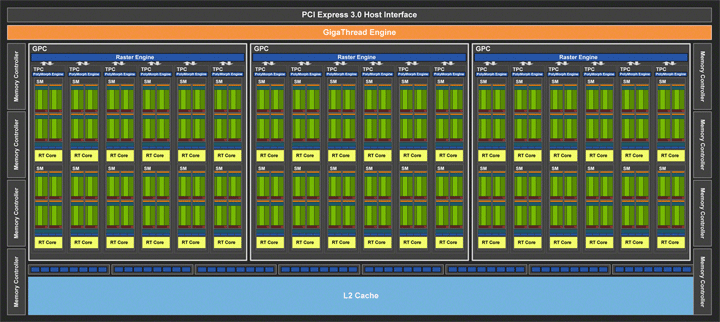
TU106 (GeForce RTX 2070)
Неожиданностью стала премьера третьего чипа для GeForce RTX 2070. По аналогии с прошлыми поколениями можно было ожидать простого урезания блоков на процессоре старшей видеокарты. Но основой GeForce RTX 2070 стал GPU TU106 с тремя стандартными кластерами по шесть TPC. Общее количество потоковых процессоров 2034, тензорных блоков 288, блоков RT 36, текстурных блоков 144. При прямом сравнении GeForce RTX 2070 с GeForce RTX 2080 получается разница 28% по вычислительным блокам. Кэш-память L2 осталась на уровне 4 МБ.
TU104 и TU106 обладают 256-битной шиной памяти (8 контроллеров разрядностью 32 бит). При этом видеокарты используют память GDDR6 с эффективной частотой 14 ГГц, что обеспечивает рост пропускной способности памяти относительно прошлого поколения.
Как видим, общая конфигурация вычислительных блоков даже у младшего GPU достаточно мощная, не говоря уже о топовом TU102. А ведь в них еще появились и новые функциональные блоки. Поэтому чипы Turing являются сложными и довольно крупными кристаллами. TU102 состоит из 18,6 млрд. транзисторов, TU104 из 13,6 млрд., а TU106 насчитывает 10,8 млрд. транзисторов. В итоге даже при переходе на 12-нм техпроцесс мы не видим роста рабочих частот. Если говорить, о GeForce RTX 2080 Ti, то тут вообще заявлено базовое значение в 1350 МГц при Boost Clock до 1635 МГц. Для младших GPU рабочие частоты выше, но они примерно на уровне моделей Pascal.
С частотами связан один интересный момент. Впервые NVIDIA вводит разные Boost-частоты при одинаковых базовых значениях. В официальных спецификациям мы видим более высокие значения Boost для моделей Founders Edition производства самой NVIDIA. При этом остальные карты тоже обозначены как Reference, что вводит в заблуждение, поскольку именно референсные версии мы привыкли ассоциировать с Founders Edition. У нас была возможность быстро сравнить видеокарту от NVIDIA с моделью другого производителя, и в реальности разница по частотам минимальная. Так что не стоит бояться разных характеристик. При наличии хорошего охлаждения производительность всех GeForce RTX одной серии будет схожей. Хуже остальных могут оказаться те редкие модели с кулером турбинного типа, которые анонсировали некоторые партнеры.
| Видеоадаптер | GeForce RTX 2080 Ti | GeForce RTX 2080 | GeForce RTX 2070 |
|---|---|---|---|
| Ядро | TU102 | TU104 | TU106 |
| Количество транзисторов, млн. шт | 18600 | 13600 | 10800 |
| Техпроцесс, нм | 12 | 12 | 12 |
| Площадь ядра, кв. мм | 754 | 545 | 445 |
| Количество потоковых процессоров CUDA | 4352 | 2944 | 2304 |
| Количество тензорных ядер | 544 | 368 | 288 |
| Количество ядер RT | 68 | 46 | 36 |
| Количество текстурных блоков | 272 | 184 | 144 |
| Количество блоков рендеринга | 88 | 64 | 64 |
| Частота ядра Base, МГц | 1350 | 1515 | 1410 |
| Частота ядра Boost, МГц (Reference) | 1545 | 1710 | 1620 |
| Частота ядра Boost, МГц (Founders Edition) | 1635 | 1800 | 1710 |
| Шина памяти, бит | 352 | 256 | 256 |
| Тип памяти | GDDR6 | GDDR6 | GDDR6 |
| Частота памяти, МГц | 14000 | 14000 | 14000 |
| Объём памяти, ГБ | 11 | 8 | 8 |
| Поддерживаемая версия DirectX | 12 | 12 | 12 |
| Интерфейс | PCI-E 3.0 | PCI-E 3.0 | PCI-E 3.0 |
| Мощность, Вт | 250/260 | 215/225 | 175/185 |
| Официальная стоимость | MSRP $999 Founders $1199 |
MSRP $699 Founders $799 |
MSRP $499 Founders $599 |
TDP новых видеокарт остался примерно на старом уровне. Так, для GeForce RTX 2080 Ti Founders Edition заявлено 260 Вт и 250 Вт для партнерских версий. Для GeForce RTX 2080 это 225 и 215 Вт, что выше TDP серии GeForce GTX 1080, но в целом приемлемо для топовых продуктов.
После общего обзора новых GPU поговорим непосредственно об инновациях архитектуры Turing.
Особенности архитектуры Turing
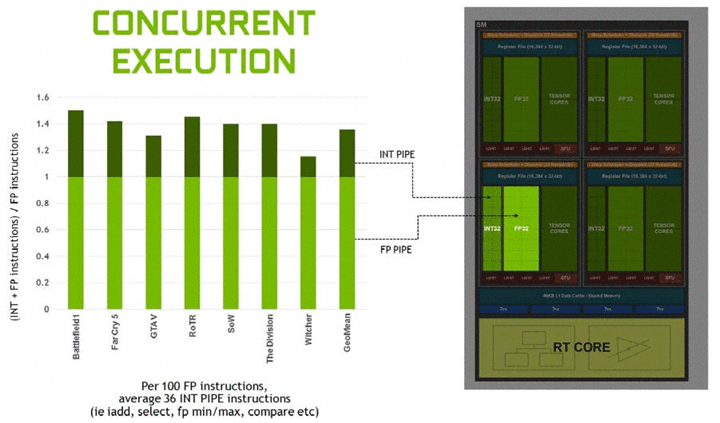
Важные изменения произошли на уровне мультипроцессорных блоков SM, которые имеют стандартную структуру во всех вариантах GPU Turing. Новая архитектура наследует возможности вычислительной архитектуры Volta и игровой архитектуры Pascal. Все вычислительные блоки внутри SM сгруппированы в четыре массива обработки данных со своей управляющей логикой (данные регистров, планировщик). В одном SM насчитывается 64 потоковых процессора. И эти вычислительные блоки теперь умеют одновременно выполнять целочисленные операции (INT32) и операции с плавающей запятой (FP32). Кстати, на схеме SM они обозначены, как разные функциональные блоки. Интересно, что у Pascal было по 128 ядер CUDA в SM, но расчеты формата INT и FP производились в последовательном порядке.
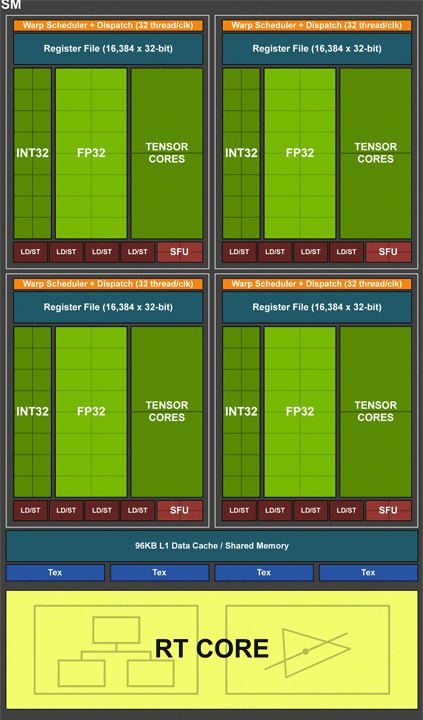
Согласно данным NVIDIA в современных приложениях при выполнении игровых шейдеров целочисленные вычисления занимают до 36%. И выполнение операций двух типов в один поток значительно ускорит общие вычисления. Тут заодно можно сказать о некоем дисбалансе, поскольку полное дублирование INT32 и FP32 не нужно. Но такая структура может быть актуальной для неигровых вычислений и задач.
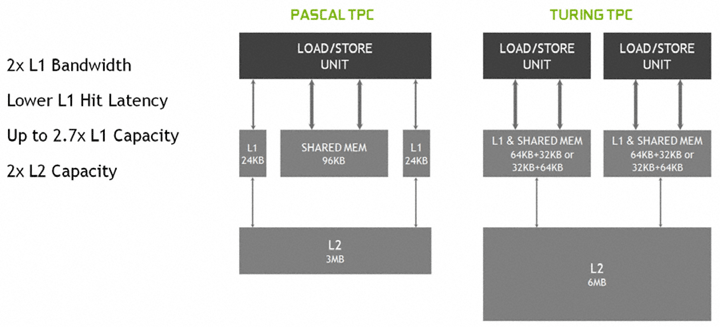
Обновленная унифицированная структура кэша L1 позволяет конвейеру TPC эффективнее работать с ним. При сохранении общего объема кэша L1 на уровне 96 КБ меньше латентность, а общая пропускная способность может вырасти до двух раз. Также во всех процессорах увеличен объем общего кэша L2. К примеру, в GPU TU102 это 6 МБ вместо 3 МБ у старого GP102.
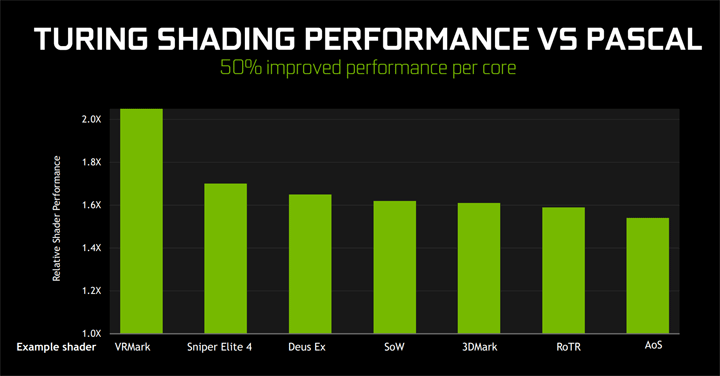
Появились и абсолютно новые блоки. Это восемь тензорных ядер для математических операций машинного обучения и один блок RT (Ray-tracing) для расчетов трассировки лучей. Но даже без учета новых блоков и новых возможностей рендеринга NVIDIA говорит о среднем росте шейдерной производительности около 50%, что звучит весьма внушительно. В виртуальной реальности VR этот прирост двукратный и даже выше. Это выглядит очень оптимистично, и походу статьи мы раскроем много нюансов, которые дают такой комплексный эффект.
В очередной раз улучшены алгоритмы сжатия данных в буфере кадра, что уменьшает количество обращений к внешней памяти. В сочетании с чипами GDDR6, которые работают при 14 Гбит/с, утверждается о росте эффективной пропускной способности до 50%. Отдельных пользователей насторожило, что GeForce RTX 2080 Ti сохранил объем в 11 ГБ, а GeForce RTX 2080/2070 получили по 8 ГБ памяти, ведь это на уровне существующих моделей Pascal. Однако такого объема сейчас хватает для высоких разрешений, а Turing в теории еще более эффективно работает с памятью.
Чипы Turing получили поддержку новых feature level из Direct 12. Улучшены асинхронные вычисления. Также новая архитектура имеет ряд улучшений для ускоренной обработки шейдеров.
Mesh Shading предлагает новый единый конвейер геометрии, заменяя вершинные, геометрические шейдеры и тесселяцию. Это более гибкий в управлении конвейер с новым типов шейдеров Task Shaders и Mesh Shaders, который позволяет одновременно работать с геометрией группы объектов, уменьшая общее количество draw calls.

Mesh Shading будет эффективен в сценах со множеством объектов и сложной геометрией, позволяя более гибко управлять LOD. На уровне DirectX 12 его можно реализовать через NVAPI. Также поддержку Mesh Shading добавят в OpenGL и Vulkan.

Перспективно выглядит технология Variable Rate Shading (VRS). Этот метод позволяет регулировать качество шейдинга в семплах 4x4 пикселя. Это дает возможности для гибкой оптимизации. Например, на периферии изображение может быть размыто эффектами Motion Blur и высокая точность проработки семплов тут не имеет значения. Это весьма актуально для гоночных игр, где дорога и окружение на периферии кадра часто смазываются.

Три алгоритма используют VRS:
- Content Adaptive Shading — уменьшает скорость шейдинга для зон со слабо изменяющимся цветом;
- Motion Adaptive Shading — вариативное качество для движущихся объектов;
- Foveated Rendering — снижение качества для областей вне зоны фокусировки.

Все это требует внедрения со стороны разработчиков. Однако VRS может реально улучшить производительность. Также это один из факторов, снижающих нагрузку на видеопамять.
Turing поддерживает новую модель Texture Space Shading (TSS). Значения шейдерных данных хранятся в памяти в специальном текстурном пространстве, откуда потом могут повторно вызываться. TSS позволяет использовать такие тексели для временного рендеринга и разных систем координат.
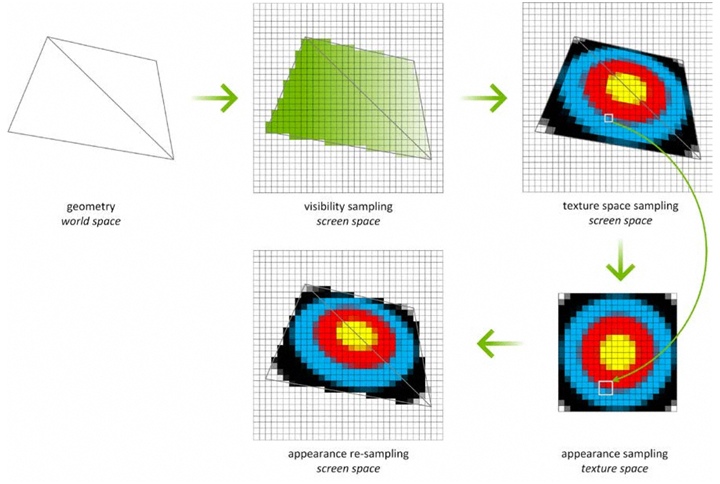
TSS является одним из элементов ускорения обработки VR. Каждый глаз видит похожее изображение. При визуализации кадра правого глаза используются данные из кадра левого глаза, а заново обработаны будут только те текстели, где нет подходящих образцов.

Тензорные ядра Turing являются улучшенными ядрами Volta. Они нужны для выполнения задач с применением искусственного интеллекта. Эти блоки поддерживают расчеты в режимах INT8, INT4 и FP16 при работе с массивами матричных данных для глубокого обучения в реальном времени. Каждое тензорное ядро выполняет до 64 операций с плавающей запятой, используя входные данные формата FP16. То есть один SM с восемью ядрами обрабатывает 512 операций FP16 за такт. Вычисления INT8 проходят на удвоенной скорости 1024 операций, а для INT4 выполняется 2048 операций за такт. И топовый GPU TU102 способен обеспечить пиковую тензорную производительность до 130,5 TFLOPS (Quadro RTX 6000).

Компания NVIDIA давно работает в области искусственного интеллекта. Однако до недавнего времени все технологии на базе обучаемых нейросетей казались уделом каких-то узкоспециализированных областей и больших дата-центров. С появлением Turing ситуация меняется, ведь мы получаем не только аппаратную платформу, но и новые программные возможности. Для интеграции возможностей искусственного интеллекта используется NVIDIA NGX (Neural Graphics Acceleration), позволяя задействовать возможности глубокого обучения для улучшения графики и визуального отображения.

На базе NGX уже реализована технология повышения разрешения изображения AI Super Rez, технология InPainting для восстановления фрагментов фотографий и некоторые другие интересные функции.

Но самым важным является сглаживание Deep Learning Super-Sampling (DLSS). Это развитие Temporal AntiAliasing (TAA) с использованием новых интеллектуальных возможностей Turing. Сейчас TAA является самым распространенным методом сглаживания, который дается с мизерными потерями производительности в несколько процентов. TAA использует данные прошлого кадра для семплов нового. При хорошем результате сглаживания краев этот метод дает определенное смазывание и дрожание картинки, особенно в динамике. DLSS использует специально обученную нейронную сеть для более быстрой и качественной выборки. Новый метод дает четкую картинку при еще меньших затратах производительности.


Сглаживание DLSS выглядит очень перспективно, причем оно легко интегрируется в игры, что упростит его популяризацию. Интересно, что на графиках NVIDIA показан весьма значительный рост fps при активации DLSS. Причина в том, что при DLSS возможны разные методы выборки, и в некоторых режимах речь, по сути, идет о реконструкции финального изображения из меньшего. То есть это действительно может ускорять рендеринг. Также надо понимать, что многие игры сейчас используют технологии адаптивного разрешения со сглаживанием через TAA. Не каждый пользователь в курсе таких тонких настроек. И если ему при автоматической настройке будет выставлен режим DLSS, то он получит заметное улучшение качества картинки при реальном росте быстродействия.
На данный момент известно об интеграции DLSS в движки Unreal Engine и Unity. А список игр, в которые добавят это сглаживание, постоянно растет.
