
Прошло довольно много времени с первого анонса на «анонс анонса». Нас дразнили процессорами AMD следующего поколения уже более года. Новый чиплетный дизайн был провозглашен не побоюсь этого слова — прорывом в производительности и масштабируемости процессоростроения, особенно в связи с тем, что с каждым поколением, с каждой архитектурой становится все труднее создавать большой чип с высокими частотами на меньших технологических нормах.

Ожидается, что этот смелый шаг повлияет на отрасль в целом. Сегодня я постараюсь для вас выкатить долгожданный очередной гайд-обзор, в котором будет и сравнение всех архитектур Zen, и гайд по разгону разных поколений процессоров и, конечно же, что нам даст разгон ОЗУ в поколении Zen 2. Хочу предупредить сразу, что обзора «содержимого коробок» вы в этой статье не найдете.
Поехали.
Архитектура
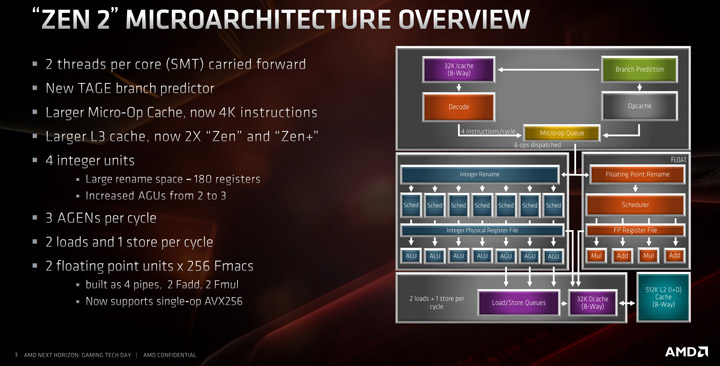
Начнем с того, что Zen 2 — это член семейства Zen, а не полноценно новая архитектура или новая парадигма обработки инструкций x86, и на верхнем уровне ядро выглядит примерно так же как и Zen/Zen+. Основные ключевые особенности архитектуры Zen 2 включают в себя новый предиктор ветвей L2 (известный как предиктор TAGE), удвоение микрооперационного кэша, удвоение кэша L3, увеличение целочисленных ресурсов, увеличение ресурсов загрузки/хранения и поддержку для одиночной операции AVX-256 (или AVX2) плюс отсутствие штрафов для AVX2.
CCD и CCX
Выше я уже упоминал о том, что компания AMD совершила прорыв в процессоростроении, применив многочиплетный дизайн. Тем не менее CCX-комплексы Zen 2 состоят из ядер аналогично предыдущим поколениям. В один блок CCX объединяется 4 ядра и 16 Мбайт общей кэш-памяти третьего уровня.
Пара CCX располагается на одном 7-нм кристалле и формирует процессорный чиплет, получивший аббревиатуру CCD (Core Complex Die). Помимо ядер и кэша, в CCD-чиплет входит также контроллер шины Infinity Fabric, посредством которого должно обеспечиваться соединение CCD с обязательным для любого Ryzen 3000 чиплетом ввода-вывода (IO), основанным на 12-нм кристалле, который мы могли пощупать ранее в Zen+.
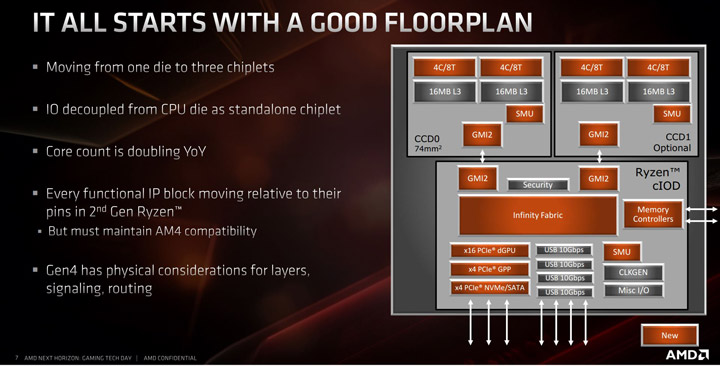
В чиплете ввода-вывода (I/O) процессоров поколения Zen 2 располагаются так называемые внеядерные компоненты, а также элементы северного моста и SOC. В нём, помимо всего прочего, находятся контроллер памяти и контроллер шины PCI Express 4.0. Также в I/O-чиплете реализованы и две шины Infinity Fabric, необходимые для соединения с CCD-чиплетами.
В зависимости от того, о каком процессоре семейства Ryzen 3000 идёт речь, он может состоять либо из двух, либо из трёх чиплетов.
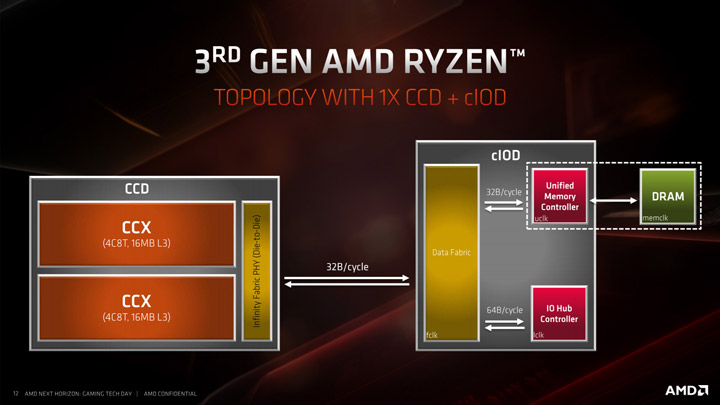
В процессорах с числом ядер восемь (потоков) и менее применяется только один CCD-чиплет и один I/O-чиплет.
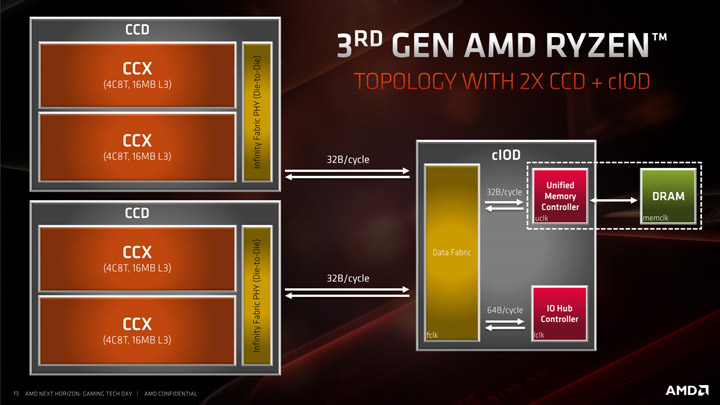
В процессорах с числом ядер более восьми CCD-чиплетов становится уже два. Однако нужно понимать, что процессор при этом всё равно остаётся единым целым. За счёт того, что в любых Ryzen 3000 контроллер памяти находится в I/O-чиплете и он всего один, любое из ядер может обращаться к любым её областям, никаких NUMA-конфигураций тут нет.
Безусловно чиплетная конструкция порождает определённые трудности для взаимодействия различных компонентов CPU и требует грамотной реализации специализированной шины, которой является Infinity Fabric. Впрочем, c этой задачей компании AMD удалось успешно справиться, и мы имеем возможность это пощупать на практике.
Без интересных особенностей, которые не попали на слайды, не обошлось, к примеру, шина Infinity Fabric на запись работает в режиме 16 байт за такт, а не 32 как нарисовано на слайдах. Увидеть просадку записи в ОЗУ можно в тестах AIDA и подобных. Расстраиваться в данном случае не имеет смысла, потому что скорость записи на самом деле не важна в большинстве задач. В любом случае, X86 имеет соотношение чтения / записи 2:1, и многие новые инструкции имеют даже соотношение 3:1 (a = a + b + c).
Zen 2 также имеет другой AGU, предназначенный для записи, который помогает быстрее найти правильный адрес для обратной записи, и теперь каждое ядро может записывать быстрее, чем раньше, несмотря на то, что общая пропускная способность записи между чиплетом и памятью уменьшается вдвое. Это также хорошо для игр, которые в некоторых случаях заполняют и генерируют больше записей, чем чтения.
Infinity Fabric
С переходом на Zen 2 мы также переходим ко второму поколению Infinity Fabric. Одним из основных обновлений IF2 является увеличение ширины шины с 256 до 512 бит, что означает двукратное увеличение пропускной способности и возможность пересылки по 32 байта за такт в каждом направлении. AMD пошла в первую очередь на это из-за появления в Ryzen 3000 поддержки PCI Express 4.0, а во вторых, чтоб увеличить производительность систем в ряде сценариев при условии недостаточной пропускной способности шины вызванной низкой тактовой частотой оперативной памяти (например пользователь купил дешевую память).

По данным AMD, общая эффективность IF2 увеличилась на 27%, что привело к снижению мощности на бит. В будущем нас ждут много чиплетные HEDT, которым, безусловно, новый интерфейс крайне необходим, но об этом мы уже с вами поговорим осенью.
Одной из особенностей IF2 является то, что контроллер памяти получил еще один режим, в котором его частота составляет половину от реальной частоты DRAM, то есть UCLK = 1/2 MEMCLK. Это было сделано для того, чтобы удовлетворить потребности энтузиастов в экстремальном разгоне и чтобы в случае неудачного кристалла IO пользователь все же смог разогнать ОЗУ без упора в IF2 и контроллер памяти. Тем не менее, на практике даже самый плохой экземпляр способен отлично работать на частотах UCLK 1800 МГц, а режим 2:1 остается эксклюзивом для энтзуиастов и оверклокеров.
Для Zen 2 синхронизации тактового сигнала доступны в вариантах 1:1 или 2:1, для поколений Zen 1 и Zen+ только 1:1.
Также я заметил, что на Reddit довольно много вопрос связанных с FCLK (это новая опция в UEFI), в частности как его настроить, чтоб система имела максимальную производительность. Идеальным вариантом для Zen 2 остается режим, когда FCLK = UCLK = MEMCLK, в этом случае отсутствуют «штрафы» синхронизации этих трех доменов.
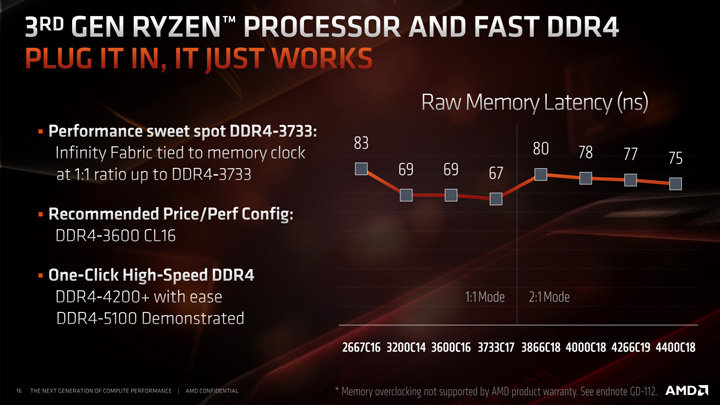
Касательно рекомендаций AMD все довольно просто, если нет желания заморачиваться с тюнингом таймингов, мы должны выбрать режим 1:1 (его, кстати, и выбирать не нужно, он включен по умолчанию), то есть как было и раньше, но если вы энтузиаст и знакомы с моим гайдом по разгону и тюнингу ОЗУ — вам ничего не мешает выжать максимум с любого режима.
Кэш
Серьезные изменения получила система кэша, самым заметным изменением является кэш команд L1, который был уменьшен с 64 до 32 КБ, но ассоциативность увеличилась с 4 до 8.
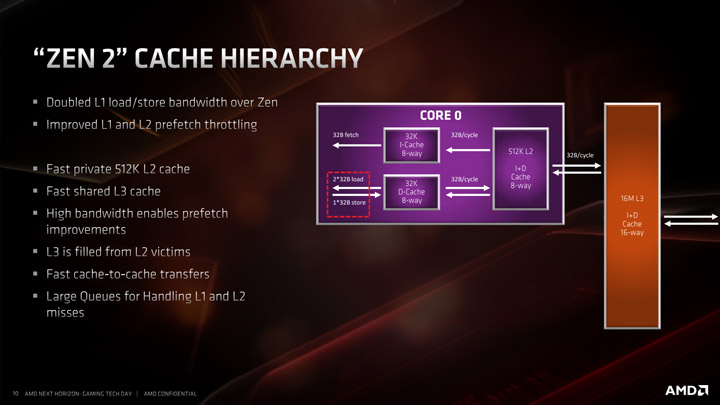
Это изменение позволило AMD увеличить размер микрооперационного кэша с 2 до 4 Кбайт и иметь более высокое использование L1-I. По мнению AMD это дало лучший баланс энергоэффективности и производительности в современных приложениях, которые не «блещут» оптимизацией и являются доминирующими на рынке ПО.
Кэш-память L1-D по-прежнему имеет 32 КБ с 8-канальной ассоциативностью, а кэш-память второго уровня 512 КБ с 8-канальной ассоциативностью. Кэш L3 теперь удвоился в размере на ядро комплекса (CCX) и составляет целых 16 MB, то есть один чиплет (CCD) в своем распоряжении имеет целых 32 MB L3. Латентность кэш-памяти для первых двух уровней не изменилась и составляет 4 такта для L1 и 12 тактов для L2, а вот L3 ожидает небольшой сюрприз, задержка увеличилась с 35 тактов до 40, что характерно для больших кэшей и не является чем-то ужасным.
Также AMD сообщила, что увеличила размер очередей, обрабатывающих пропуски L1 и L2, но не уточнила, насколько они велики.
Из «фишек» — теперь кэш-память может обслуживать по две 256-битных операции чтения и по одной 256-битной операции записи за такт на уровне L1, а также по одной 256-битной операции чтения и записи за такт на уровне L2, что вносит огромный вклад в скорость выполнения AVX.
Вычисления с двойной точностью
Основное улучшение производительности с плавающей запятой — полноценная поддержка AVX2. AMD увеличила ширину исполнительного блока со 128- до 256-битного, что позволяет выполнять расчеты AVX2 за один такт, а не разбивать вычисления на две инструкции и два цикла, следовательно, от Zen 2 можно ожидать двукратного увеличения скорости работы с AVX2-кодом.
Исполнительные устройства в FPU при этом остались нетронутыми. К тому же в Zen 2 AMD смогла добиться того, что обработка AVX2-инструкций может проводиться без какого-либо снижения тактовой частоты, как это происходит в процессорах Intel, при этом не стоит забывать, что частота может быть уменьшена в зависимости от требований к стоковым лимитам (температуры и напряжения), но это происходит автоматически и независимо от используемых инструкций. Должен сделать оговорку, что пользователь лимиты может изменить по желанию или вовсе отключить, тем самым переложив ответственность всю на систему охлаждения и свои плечи.

В модуле с плавающей запятой очереди принимают до четырех микроопераций за такт от модуля диспетчеризации, которые подают в файл физических регистров с 160 записями. Это перемещается в четыре исполнительных блока, которые могут быть снабжены 256-битными данными в механизме загрузки и хранения.
Были внесены другие изменения в модули FMA, помимо удвоения размера — AMD заявляет, что инженеры увеличили сырую производительность в распределении памяти, для физических симуляций (вычислений) и некоторых методов обработки звука.
Еще одним ключевым обновлением является уменьшение задержки умножения FP с 4 до 3 циклов. Это довольно значительное улучшение. Больше деталей об этом AMD обещала поведать на Hot Chips, которая состоится в августе.
Fetch/Prefetch
Основным заявленным улучшением является использование предиктора TAGE, хотя он используется только для выборок не из L1. AMD по-прежнему использует хешированный механизм предварительной выборки персептрона для выборок L1, который будет состоять из максимально возможного числа выборок, но предиктор ветвей TAGE L2 использует дополнительные теги, чтобы включить более длинную историю ветвей для лучшего прогнозирования. Это становится более важным для предварительных выборок L2 и выше, поскольку хешированный персептрон предпочтителен для коротких предварительных выборок в L1 на основе мощности.
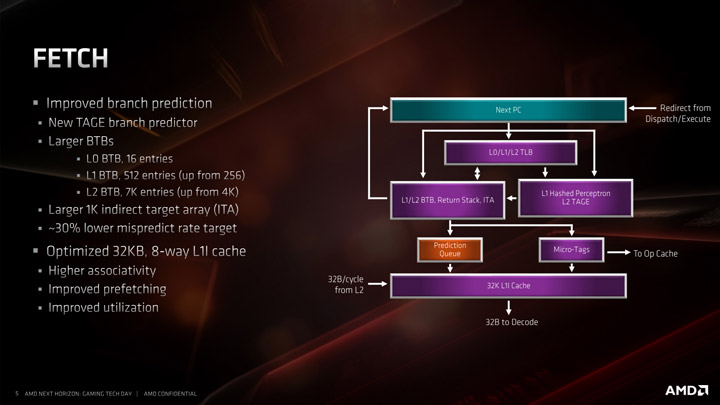
Во внешнем интерфейсе мы также получаем более крупные BTB, чтобы отслеживать ветви команд и запросы кэша. Размер L1 BTB увеличился в два раза с 256 до 512 записей, а L2 почти удвоился с 4K до 7K. BTB L0 остается на 16 записей, но косвенный целевой массив идет до 1K записей. В целом, эти изменения, по мнению AMD, позволяют на 30% снизить вероятность ошибочного прогнозирования, тем самым экономя электроэнергию.
Декодирование
Для этапа декодирования основным преимуществом является микрооперационный кэш. Удвоив размер с 2K записи до 4K записи, он будет содержать больше декодированных операций, чем раньше, что означает, что он должен многократно использоваться. Чтобы упростить это использование, AMD увеличила скорость отправки из кэша микроопераций в буферы до 8 объединенных инструкций.
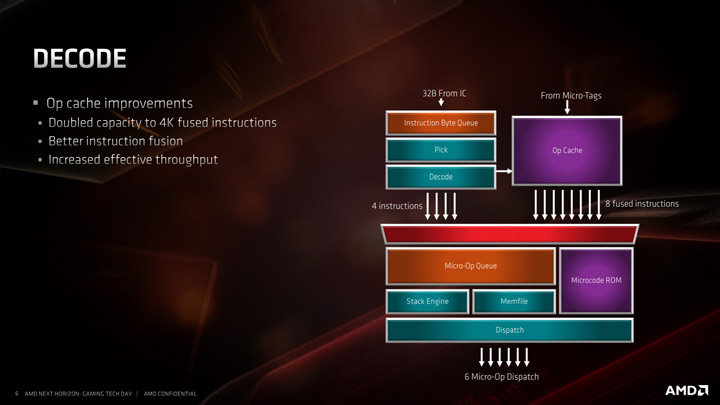
Декодеры в Zen 2 остаются прежними, у нас все еще есть доступ к четырем сложным декодерам, а декодированные инструкции кэшируются в кэш микроопераций и также отправляются в очередь микроопераций.
Выходя за пределы декодеров, очередь микроопераций и диспетчеризация могут вводить в планировщики шесть микроопераций за такт. Однако это немного несбалансированно, поскольку AMD имеет независимые планировщики целых чисел и операций с плавающей запятой: целочисленный планировщик может принимать шесть микроопераций за такт, тогда как планировщик с плавающей запятой может принимать только четыре. Однако отправка микрооперации может осуществляться обоим одновременно.
Исполнения инструкций
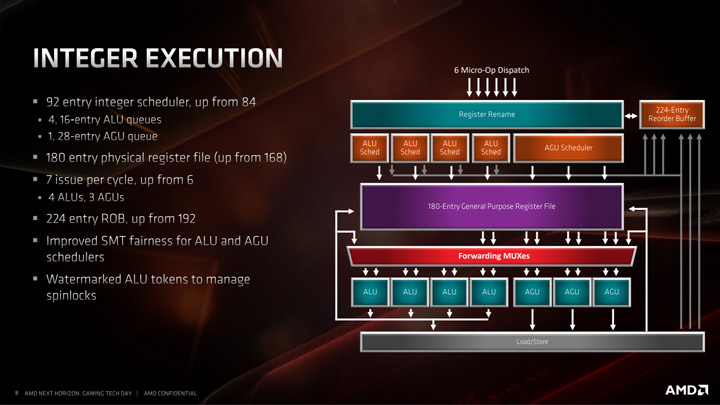
Планировщики целочисленных единиц могут принимать до шести микроопераций за такт, которые подаются в буфер переупорядочения с 224 записями (по сравнению с 192). Технически модуль Integer имеет семь исполнительных портов, состоящих из четырех ALU (арифметико-логических модулей) и трех AGU (блоков генерации адресов).
Планировщики состоят из четырех очередей ALU с 16 входами и тремя AGU с 28 входами. Блок AGU может подавать 3 микрооперации за такт в файл регистра. Также размер очереди AGU увеличился в результате моделирования распределений инструкций AMD в обычном программном обеспечении. Эти очереди поступают в регистровый файл общего назначения на 180 записей (вместо 168), но также отслеживают конкретные операции ALU для предотвращения возможных операций остановки.
Три AGU подают в модуль загрузки/хранения, который может поддерживать два 256-битных чтения и одну 256-битную запись за такт. Не все три AGU равны, AGU2 может управлять только хранилищами, тогда как AGU0 и AGU1 могут выполнять как загрузку, так и хранилища.
Загрузка и хранение
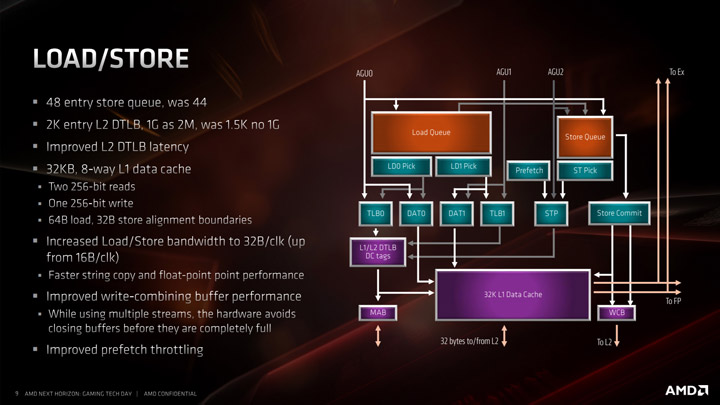
В Zen 2 была улучшена работа L2 TLB (буфера трансляции адресов). В первом поколении процессоров Zen размер этой таблицы составлял 1,5К, теперь же она увеличилась до 2К. L2 TLB теперь поддерживает страницы объёмом 1 Гбайт, чего в прошлых версиях микроархитектуры реализовано не было.
Еще одним ключевым показателем здесь является пропускная способность загрузки/хранения, поскольку ядро теперь может поддерживать 32 байта за такт, а не 16.
Также попутно была увеличена очередь хранения с 44 до 48 записей.
Контроль QoS пропускной способности кэша и памяти

В большинстве новых микроархитектур x86, существует гонка, чтобы повысить производительность с помощью новых инструкций, а также стремление к паритету между различными поставщиками в отношении того, какие инструкции поддерживаются. Касательно Zen 2, AMD не спешит «удовлетворять» Intel, добавляя в свое детище некоторые экзотические наборы инструкций. Компания добавляет новые, собственные инструкции в трех различных областях.
CLWB была замечена ранее в процессорах Intel в отношении энергонезависимой памяти. Эта инструкция позволяет программе помещать данные обратно в энергонезависимую память на тот случай, если система получит команду остановки и данные могут быть потеряны. Существуют и другие инструкции, связанные с защитой данных в энергонезависимых системах памяти, но AMD это не стала раскрывать. Возможно, компания стремится улучшить поддержку оборудования и структур энергонезависимой памяти в будущих разработках, особенно в своих процессорах EPYC и не хочет демонстрировать козыря раньше времени.
Вторая инструкция кэширования WBNOINVD относительно новая, она основывается на других подобных командах, таких как WBINVD и является экслюзивом для AMD-платформы. Эта команда предназначена для прогнозирования, когда в будущем могут понадобиться определенные части кэша, и очищает их, готовые для ускорения будущих вычислений. В случае, если необходимая строка кэша не готова, команда сброса будет обработана заблаговременно до необходимой операции, что увеличит задержку — запустив строку очистки кэша заранее, в то время как критическая для задержки инструкция все еще поступает, конвейер помогает ускорить его окончательное исполнение.
Третий набор инструкций QoS, фактически относится к тому, как назначаются приоритеты кэша и памяти.
Когда облачный ЦП разделяется на разные контейнеры или виртуальные машины для разных клиентов, уровень производительности не всегда одинаков, поскольку производительность может быть ограничена в зависимости от того, что другая виртуальная машина делает в системе. Это известно как проблема «шумного соседа»: если кто-то еще потребляет всю пропускную способность ядра к памяти или кэш-память L3, другой виртуальной машине в системе может быть очень трудно получить доступ к тому, что ей нужно. В результате этого шумного соседа другая виртуальная машина будет иметь очень переменную задержку при обработке своей рабочей нагрузки. В качестве альтернативы, если критически важная виртуальная машина находится в системе, а другая виртуальная машина продолжает запрашивать ресурсы, критическая виртуальная машина может в конечном итоге пропустить свои цели, поскольку у нее нет всех ресурсов, к которым ей требуется доступ.
Трудно иметь дело с шумными соседями, помимо обеспечения полного доступа к оборудованию в лице одного пользователя. Большинство облачных провайдеров даже не скажут вам, есть ли у вас соседи, и в случае миграции виртуальных машин в режиме реального времени эти соседи могут меняться очень часто, поэтому в любой момент гарантии стабильной производительности нет.
Как и в случае с реализацией Intel, когда серия виртуальных машин размещается в системе поверх гипервизора, гипервизор может контролировать объем пропускной способности памяти и кэш-памяти, к которым имеет доступ каждая виртуальная машина.
Корпорация Intel включает эту функцию только на своих масштабируемых процессорах Xeon, однако AMD включит и расширит линейку процессоров семейства Zen 2 для потребителей и корпоративных пользователей.
Безопасность
Другим аспектом Zen 2 является подход AMD к повышенным требованиям безопасности современных процессоров. Как уже сообщалось, значительное число недавних эксплойтов с побочными каналами не влияют на процессоры AMD, в первую очередь из-за того, как AMD управляет своими буферами TLB, которые всегда требовали дополнительных проверок безопасности, прежде чем большая часть этого стала проблемой. Тем не менее, для проблем, к которым уязвима AMD, она внедрила для них полную аппаратную платформу безопасности.

Изменение здесь коснулись для Speculative Store Bypass, известного как Spectre v4, — теперь новые процессоры имеют хардварную заплатку, которая будет работать в сочетании с ОС или диспетчерами виртуальной памяти, такими как гипервизоры. Компания не ожидает каких-либо изменений производительности от этих обновлений. Новые проблемы, такие как Foreshadow и Zombieload, не влияют на процессоры AMD.
Энергоэффективность и разгон
Безусловно, переход на новый 7-нм техпроцесс первого поколения родил в головах пользователей мысль, что новые процессоры просто обязаны брать 5 ГГц, на которых не только можно будет работать а и, обмазавшись, пойти на форум вести баталии с оппонентами.

На слайде с презентации AMD на E3 мы можем увидеть значение 4600 МГц. К сожалению это не то о чем мечтали, но и не так уж и плохо. Давайте разбираться что, как и почему.
Первое самое важно, что обязан вам сказать — частота не главное. Львиная доля успеха Mattise заключается в архитектуре, и только небольшая часть — это техпроцесс.
Уменьшение размеров технологической нормы создает ряд проблем в самом кристалле и за его пределами. Даже если не учитывать TDP и частоту, сама по себе возможность помещать структуры в кремний и затем интегрировать этот кремний в подложку является крайне сложной и дорогостоящей разработкой.
В большинстве случаев подобные кардинальные изменения, которые получил Matisse, тянут на новый сокет. В нашем случае компания AMD преподнесла пользователям подарок — процессорный разъем остался неизменным.
Тем не менее, в бочке меда при желании можно найти ложку дегтя. В данном случае произошло пять важных вещей, которые повлияли на разгон в силу физических закономерностей:
1) Подключение чиплетов к кремневой подложке отразилось на расположении сигнальных линий, которые далеко не все имеют оптимальную длину или местоположение, дабы обеспечить требуемые соотношения полезного сигнала к шуму. Это не есть плохо, но, конечно, немного хуже, нежели если б это был сокет АМ5. Безусловно, глобальная переработка коснулась и линий питания.
Кроме того, процессоры с двумя CCD (Ryzen 9 3900X и 3950X) должны быть более требовательны к FCLK из-за всегда присутствующего расхождения в сигнализации CCD. При этом обычно один из CCD предпочитает более низкое напряжение, чем другой, и так далее.
2) Техпроцесс, туннелирование элекронов и обратный ток.
Отдельные транзисторы на чипе формируются методом фотолитографии. В этом случае на кремниевую подложку наносят тонкую фоточувствительную полимерную пленку, называемую фоторезистом. Затем этот фотослой обрабатывают светом (производят так называемое экспонирование) через фотошаблон с необходимым рисунком. Проэкспонированные участки смываются в проявителе, а затем производится вытравливание кристаллов.
Компании уменьшают техпроцессы, чтобы увеличить количество продукции из одной заготовки и снизить энергопотребление финального чипа. Производитель получает возможность увеличить быстродействие микросхемы, оставив её размеры на прежнем уровне.
Долгое время эта тенденция (на уменьшение техпроцессов) оставалась справедливой. Но сейчас ИТ-компании начали откладывать или вообще прекращать разработку новых техпроцессов. Отчасти это связано с удорожанием оборудования и высоким уровнем брака. Пример 10 нм от Intel.
Возвращаясь к нашему случаю, в преимуществах мы получили удвоение плотности размещения транзисторов при в два раза меньшем энергопотреблении.

Туннелирование электронов — когда затвор становится слишком тонким, и электроны могут проходить через него, тогда заряд, накопленный на затворе транзистора, может быть потерян, что требует от пользователя его возобновления. В результате получается транзистор, который потребляет больше тока, что, в свою очередь, приводит к большему рассеиванию тепла. Отдельные транзисторы имеют почти неизмеримые величины потерь тока и повышение температуры, но когда несколько миллиардов транзисторов размещаются на одном куске кремния, эффект накапливается и становится серьезной проблемой. Также ток не просто вытекает из затвора, ток может туннелировать от источника к стоку, если они находятся в непосредственной близости, что может препятствовать способности транзисторов контролировать ток.
Также при повышении напряжения ток утечки возрастает по линейному закону или еще более круто. Влияние же температуры на ток утечки выражено сравнительно слабо. Образование тока утечки, как правило, связано с несовершенством технологии изготовления, потому не удивляйтесь, когда читаете новость, что ваш любимый процессор получил новый степпинг. Этот процесс усовершенствования является по сути бесконечным.
Еще одним интересным нюансом является канальный ток. Канальный ток является основной составляющей для кремниевых р-n переходов, выполненных по планарной технологии. Не вдаваясь здесь в особенности планарной технологии, отмечу, что при ее использовании поверхность кремниевых р-n переходов покрывается защитной пленкой SiO2. Это покрытие, с одной стороны, практически устраняет ток поверхностной утечки, но, с другой стороны, порождает канальный ток. Канальный ток возникает за счет образования канала (очень тонкого слоя) n-типа в приповерхностной области р-типа, покрытой пленкой SiO2. К счастью канальный ток очень маленький — десятые доли или единицы наноампер, потому его не рассматриваем как фактор (как и не рассматриваем тепловой ток и ток термогенерации), который повлияет на тепловыделение и разгон наших «камней».
3) Фазы. Переход на более тонкий техпроцесс повлиял на рабочее напряжение, что соответственно означает низкий КПД VRM из-за более высоких токов и очень низкого рабочего цикла преобразователя. Решается зачастую это путем увеличения кол-ва фаз и в большинстве случаев это даблеры. Вам это может показаться смешным или даже маркетинговым ходом жадных производителей материнских плат, но отнюдь это не так. Я напомню, совсем недавно, когда была рождена линейка Intel X299, были те самые многочисленные проблемы с VRM, так как серия процессоров HEDT работала на низком рабочем напряжении. Именно поэтому, дабы не совершать ошибок конкурента, компания AMD подготовила чипсет X570. Большинство плат на своем борту имеют от 12 до 16 фаз, топологию Daysi chain нового поколения и, конечно же, PCI Express Gen 4.
Возможно, вас количество фаз напугает, постараюсь успокоить. Во-первых, сейчас престижно иметь под своим крылом продукты, которые на бумаге и в живую производят впечатление, и не важно, есть ли востребованность или нет. Во-вторых, мы получаем продукт для настоящих энтузиастов, а кто вы — выбирать вам и вашему бюджету.
Превратились ли в тыкву текущие серии плат? — отчасти. В основном за бортом частично остались серии A320 и B350 ввиду своих слабых VRM и собственного ценового класса, который из-за себестоимости проектировки и бюджетной элементной базы не может предложить новой архитектуре/чипсету полноценную «совместимость» на приемлемом уровне. В качестве примера я покажу картинку от своих партнеров в лице TechPowerUP.

На картинке материнская плата ASUS Prime B350 c 3900Х на борту во время стресс теста. Как видите температуры VRM достаточно, чтобы жарить барбекю. Потому я Вам советую отнестись серьезно к проблеме нехватки мощностей при покупке Ryzen 9 3900Х или 3950Х.
4) Площадь и температура. В пункте номер 2 я писал о туннелировании и проблемах отводах тепла от маленьких кристаллов. Дабы решить проблему отвода тепла, компания AMD убила сразу двух зайцев: удвоенный кэш L3 не только увеличивает производительность в приложениях, а и служит своего рода «радиатором», ведь он теперь занимает половину площади кристалла.

Если говорить о числах, то ключевой показатель размеров одного CCX (комплекса) Zen+ равен 60 квадратных миллиметров, из которых 44 мм2 это ядра, а 16 мм2 — 8 МБ L3 на CCX. Если собрать все блоки в кучу мы получим 213 мм2.
Для Zen 2 один чиплет имеет размер 74 мм2, из которых 31,3 мм2 представляют собой кремневый кусок с 16 МБ L3, что в свою очередь приближается к 50% от всей площади одного CCD (чиплета).
К чему я это пишу? Самым большим ограничением является интенсивность тепла на площадь. Считаем приблизительные значения:
- Ryzen 7 2700Х с площадью кристалла 213мм2 и TDP 145 Вт мы получаем 0,68 Вт/мм2;
- Ryzen 7 3700Х с площадью ССD в 74мм2 и TDP 95 Вт мы получаем 1,28 Вт/мм2;
- Для Core i9-9900К при площади в 174мм2 и ТDP 200 Вт мы получаем всего 0,87 Вт/мм2.
Итого, наш разгон очень существенно ограничен площадью для передачи тепла, в частности импульсов тепла. Безусловно, припой под крышкой все же лучше темопасты, но глядя на предварительные обзоры с ручным разгоном, все выглядит довольно печально.
5) SIDD и Ti-состояния. Многие из вас наверно догадываются, что производители процессоров всегда делают сортировку чипов в своих продуктах, на техническом сленге это именуется биннингом.
Процессоры можно разделить условно на два лагеря: с высокими токами утечки (high SIDD) и с низкими токами утечки (low SIDD). Как всегда, существуют различия между образцами в пределах одного и того же уровня утечки, что означает наличие хороших и плохих образцов в категориях как с низкой, так и с высокой утечкой.
Образцы с более низкими характеристиками утечки потребуются напряжения, превышающие пределы спецификации или технологического процесса, а образцы с малой утечкой потребляет значительно меньше тока, чем часть с большой утечкой, но обычно требуется более высокий уровень напряжения для достижения той же частоты.
Образцы со сверхвысокими токами утечки встречаются гораздо чаще, и поэтому серия процессоров «X» основана на кремнии с высокими токами утечки.
Дабы вы лучше поняли меня, начнем с небольшого экскурса в историю и рассмотрим Ryzen 7 1700 и 1800Х на субмаксимальных частотах для домашнего пользования в 3900 МГц.

Процессор Ryzen 7 1700 имеет VID 1,35 В для ручной частоты P0 в 3900 МГц. Это указывает на то, что образец ЦП имеет низкий SIDD (статическая утечка).
Процессор Ryzen 7 1800X имеет VID 1.275, что соответственно награждает этот процессор титулом high SIDD.
Образец с высоким SIDD с запасом P0 VID, безусловно, сможет достичь частоты X при гораздо более низком напряжении, чем образец с низким SIDD .Однако это не делает экземпляры с высокой утечкой лучше.
Экземпляры с высокой утечкой требуют значительно меньшего напряжения, чем модели с малой утечкой, но в то же время они потребляют больший ток и нагреваются гораздо быстрее, чем экземпляры с малой утечкой. Также их напряжение пробоя ниже. Образец с высокой утечкой может выгореть при 1,55 В, в то время как образец с низкой утечкой имеет шанс умереть только на 1,65 В.
Более высокие токи вызывают большие потери проводимости, которые сами по себе уже повышают температуру в процессоре. Что собственно мы видим на картинке, на идентичной частоте разница в температуре составляет не менее 7 градусов. Более высокие токи утечки также значительно увеличивают нагрузку на VRM материнской платы.
Идем дальше, процессоры Ryzen 5 2600/2600X и Ryzen 7 2700/2700X.
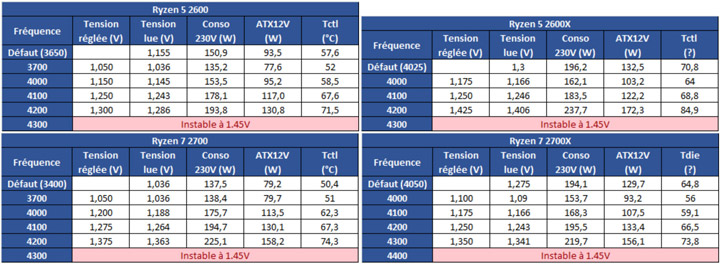
В этом случае мы видим результаты, которые не соответствуют вышеописанной теории. Объяснение крайне простое: каждый техпроцесс совершенствуется, производство становится более опытным и количество брака со временем становится меньше. В случае Zen+ мы видим, что «камни» с суффиксом Х и без находятся на примерно одинаковом уровне SIDD и бининг выполняется в рамках идентичного SIDD.
Существует еще один нюанс, о котором мало кто знает. Высокий SIDD все же лучше из-за электронной баллистики и Ti-состояний (XFR/PBO). На определенной температуре транзистор может быть больше «разогнан» для заданного напряжения.
Ключ в том, чтобы уравновесить увеличение мощности утечки при более высоких температурах с динамическим снижением мощности в Ti-состояниях, где Ti-состояния: управление питанием процессора в области температурной инверсии.
В свою очередь инверсия температуры — это эффект на уровне транзистора, который может улучшить производительность при достижении определенной. Звучит бредово? Разбираемся.
Лет 6 назад это в значительной степени игнорировалось, потому что это не происходит в типичной рабочей области процессора, но инверсия температуры становится все более важной в современных и будущих технологиях. Существует сатья «Ti-states: Processor power management in the temperature inversion region», опубликованная на ieeexplore.ieee.org, в которой изучается влияние инверсии температуры на проектирование архитектуры и управление питанием и производительностью. В ней предоставили первый общедоступный комплексный анализ на основе результатов измерений влияния температурной инверсии на реальный процессор с использованием AMD A10-8700P в качестве образца.
Результаты демонстрируют, что дополнительный интервал синхронизации, введенный инверсией температуры, может обеспечить более чем 5% преимущества снижения Vdd, и это улучшение увеличивается до более чем 8% при работе в околопороговой области низкого напряжения. Чтобы использовать эту возможность, авторы представили Ti-состояния — это метод управления питанием, который устанавливает напряжение процессора на основе температуры кремния в реальном времени для повышения энергоэффективности.
Ti-состояния приводят к измеренной экономии энергии от 6% до 12% в диапазоне различных температур по сравнению с фиксированным запасом. По мере того, как технология масштабируется до FD-SOI и FinFET, демонстрируется, что существует идеальная рабочая температура для различных рабочих нагрузок, чтобы максимизировать преимущества инверсии температуры. Ключ состоит в том, чтобы уравновесить увеличение мощности утечки при более высоких температурах с динамическим уменьшением мощности Ti-состояниями. Прогнозируемая оптимальная температура обычно составляет около 60 °C и обеспечивает экономию энергии от 8% до 9%. Оптимальная высокая температура может быть использована для снижения затрат на проектирование и эксплуатационной мощности в режиме общего охлаждения.
Теория теорией, но как же практика? Пару дней назад мне попалось на глаза видео от gamersnexus, в которой ребята охлаждали процессор Ryzen 9 3900Х и смотрели на показатели буста в зависимости от температуры. На удивление там так же фигурирует число в 60 градусов, которое позволяет процессору бустить лучше, нежели на температурах более 60 градусов.
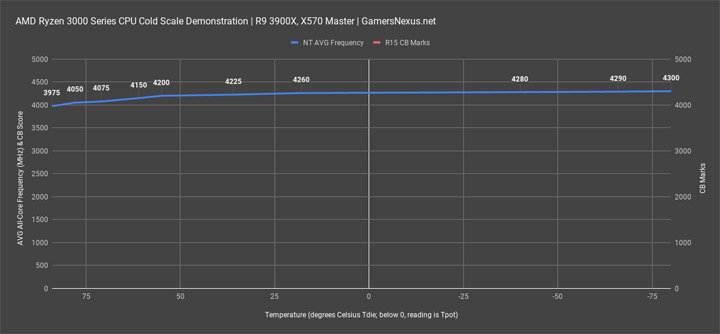
Совпадение? Не думаю. Идем дальше.
Следующее, что может броситься в глаза, так это Clock Ramping.

Функция, которая позволяет процессору более свободно переключаться между различными P-состояниями, а также переходить из режима ожидания в режим быстрой загрузки с определенным интервалом. Это было сделано путем передачи управления P-состояния от операционной системы к процессору, который реагирует, основываясь на пропускную способность команд и запросов.
Техническое название это CPPC2 или Collaborative Power Performance Control. Метрики AMD утверждают, что это может увеличить пакетные рабочие нагрузки, а также загрузку приложений. Суб-тест запуска приложений PCMark 10 показал увеличение производительности на 6% во время запуска приложений.
Еще одна интересная деталь любого Zen — это огромные количества датчиков, которые отслеживают состояние каждого ядра, каждого модуля.
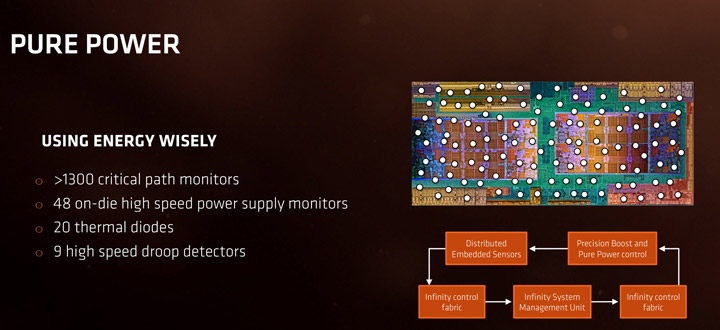
Стоит отметить, что число управляемых цепей питания в ядре Ryzen превышает 1300 штук (для первого поколения), а число встроенных датчиков температуры и токов достигает нескольких десятков тысяч.
Также не стоит забывать новое управление напряжением в архитектурах Zen, своего рода попытка организовать значительно более тонкую настройку мощности на уровне ядра на основе сбора информации, которая имеется у этого ядра и всего чипа.
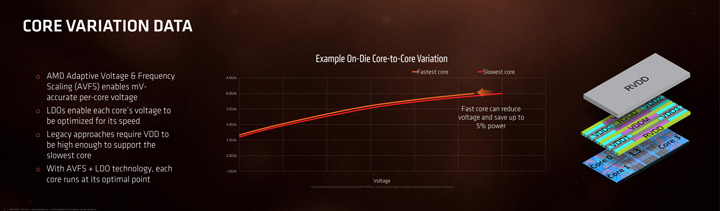
В Zen , напряжение, поступающее с модуля регулятора напряжения (VRM), подается на RVDD, плоскость металлического корпуса, которая распределяет самый высокий запрос VID из всех ядер. В Zen (любом) каждое ядро имеет цифровой регулятор LDO (низкий уровень выпадения) и цифровой синтезатор частоты (DFS) для изменения частоты и напряжения между состояниями питания на основе отдельных ядер. LDO регулирует RVDD для каждой области питания и создает оптимальный VDD на ядро, используя систему датчиков, встроенную во весь чип. Это в дополнение к другим свойствам является контрмерой против «обвисания».
Говоря на простом языке, высокое напряжение, которое вы могли видеть во время однопоточной нагрузке при использовании Pinnacle Ridge, или видите сейчас в Matisse, не является проблемой. Во всех случаях вы видите максимальное напряжение, которое получил RVDD и распределил на несколько успешных ядер, при этом остальные ядра получили куда меньшее напряжение, дабы уменьшить энергопотребление и тем самым снизить тепловыделение.
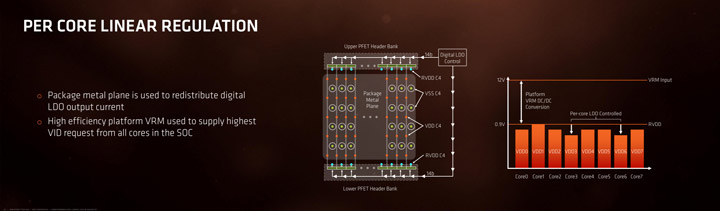
В дополнение к схеме LDO интегрированной для каждого ядра, имеется детектор снижения энергопотребления с малой задержкой, который может запускать цифровые LDO для включения большего количества драйверов для противодействия сбоям.
Большее количество датчиков по всей матрице используется для измерения многих состояний процессора, включая частоту, напряжение, мощность и температуру. Эти данные, в свою очередь, используются для характеристики рабочей нагрузки, адаптивного напряжения, настройки частоты и динамического тактирования. Адаптивное масштабирование напряжения и частоты (AVFS) является встроенной замкнутой системой, которая регулирует напряжение в режиме реального времени после измерений на основе собранных сенсорных данных. Это часть технологии AMD Precision Boost Override, обеспечивающей высокую степень гранулярности с тактовыми частотами вплоть до 25 МГц.
Энергоэффективность
Оценка энергоэффективности всегда была важной характеристикой для любого кремневого продукта. Методика тестирования довольно простая и заключалась в следующем: замер минимального напряжения и потребления для каждой частоты в тестовом пакете Linx 0.7.0. Гранулярность шага 50 МГц в диапазоне 3600–4400 МГц. Нагрузку в данном тесте создавал всем известный LinX 0.7.0. Частота оперативной памяти при этом была зафиксирована на частотах 3600 и 3733 МГц для Ryzen 7 2700X и для Ryzen 7 3700Х соответственно.
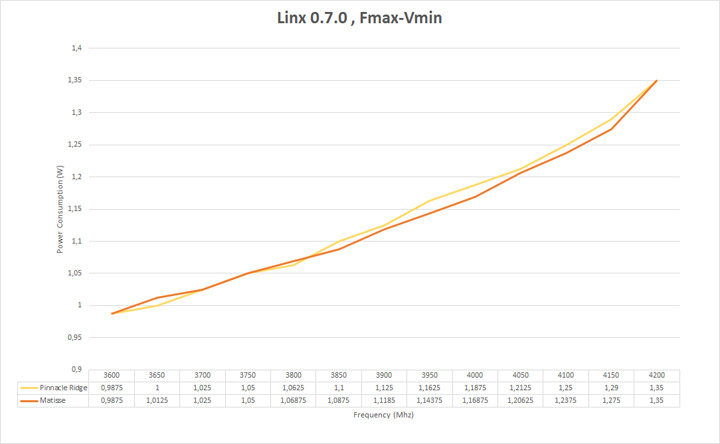
Как и в случае с Pinnacle Ridge, запас для разгона высокопроизводительных Matisse чрезвычайно мал. Критические точки для Pinnacle Ridge присутствуют на частотах 3850 и 4050 МГц, для Mattise на 3900 и 4100 МГц.
Под критическими точками я подразумеваю переломные моменты, при которых идет значительный рост потребности в напряжении.
Максимально энергоэффективной частотой для Zen+ является диапазон 3600–3800 МГц в зависимости от экземпляра. Для Zen 2 это 3700–3800 МГц. Разумные переделы масштабируемости присутствуют до 4050 МГц в случае Zen+ и до 4150 МГц в случае Zen 2.
Что касается результата CPU Package Power (SMU) тут все довольно просто — все ограничивается вашей системой охлаждения. Самым главным фактором является качество теплообменника, поскольку мы имеем возросшее тепловыделение относительно площади кристалла. Не стоит забывать и про возможности VRM вашей материнской платы.
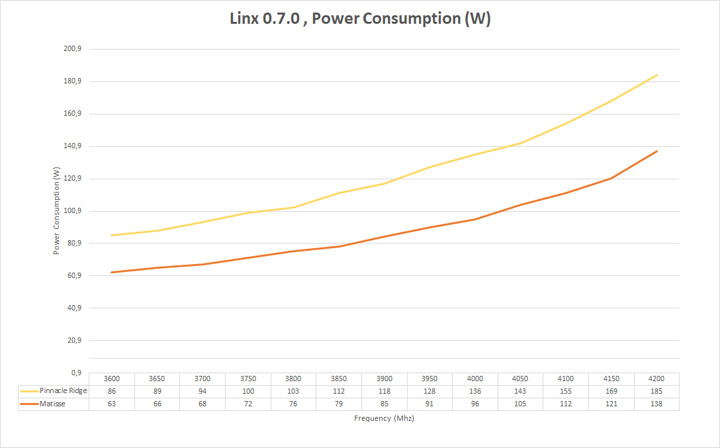
Глядя на эти результаты можно сказать, что мы имеет прекрасное энергоэффективное решение, которое в значительной мере обходит свое старого собрата. Также хочу обратить ваше внимание на математическую производительность относительно энергопотребления для частоты 4200 МГц (к примеру). Для Ryzen 7 2700Х результат в Linx составляет 240 GFlops, а для Ryzen 7 3700Х все 480 GFlops.
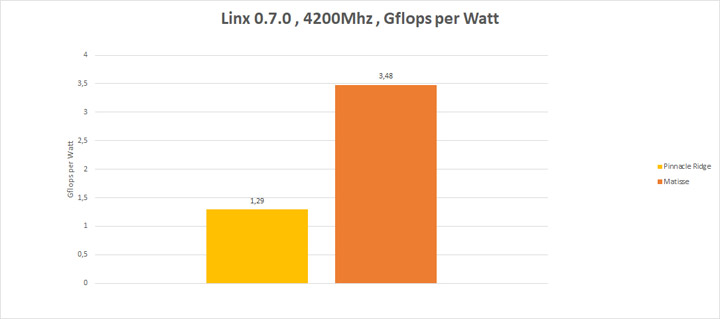
Что касается разгона в виде фиксирования частоты множителем, то я вам посоветую забыть о нем в принципе, поскольку разгон в большинстве случаев приведет к снижению производительности в однопоточном режиме. И что же делать?
У меня для вас предложение — модификация уже существующего буста с помощью настройки питания процессора через оффсет-режим, плюс изменение BCLK в случае Ryzen 7 3700Х. Для процессоров поколения Zen+ — модификация уже существующего буста с помощью настройки питания процессора через оффсет-режим с изменением BCLK и Scalar, плюс отключение лимитов PBO. Методичка как это все делать будет позже, а сейчас нам нужно понять, имеют ли ядра запас прочности.
Начнем с архитектуры и теории. Каждый CCX состоит из четырех процессорных ядер, в каждом чиплете находится два CCX.
Чиплетов же может быть один, а может быть и несколько (Threadripper). Каждое ядро при этом имеет собственные вольт-частотные характеристики. Компания AMD даже отметила удачные ядра звездочками и кружечками в собственном ПО RyzenMaster для наглядности и упрощения понимания пользователями кривой PBO.
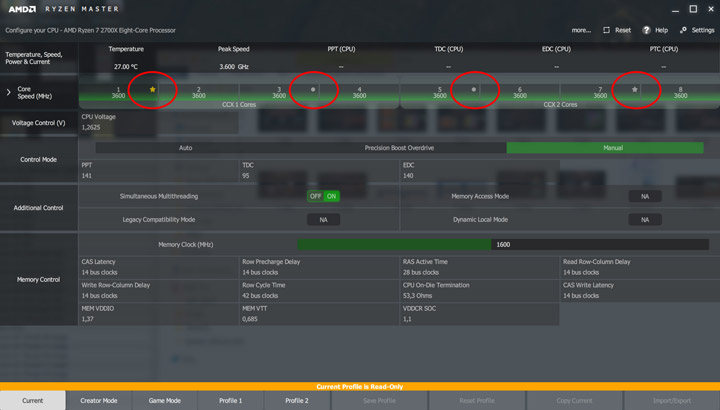
На данном моменте, я думаю, стоит напомнить вам, как работает Precision Boost.
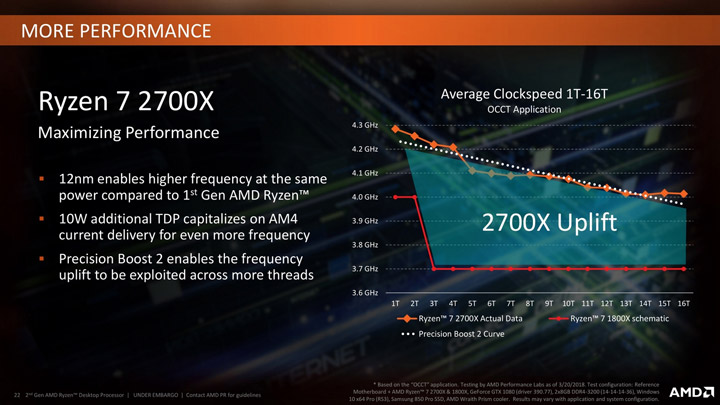
На слайде от AMD представлена эта функция: смысл ее заключается в динамическом изменении частот и количества активных ядер в зависимости от сценария нагрузки, не выходя за рамки ограничивающих факторов, таких как PPT, TDC и EDC.
На просто языке эти факторы могут выглядеть вот так:
- Общая пиковая мощность чипа.
- Индивидуальное напряжение / частотный отклик.
- Тепловые взаимодействия между соседними ядрами.
- Ограничения мощности для отдельных ядер / групп ядер.
- Общие тепловые характеристики.
Возвращаясь к теме о качестве ядер в CCX и для дальнейшей демонстрации вышеизложенной теории, я провел исследование. Поочередно проверил каждое ядро для Ryzen 7 2700Х и трех частот, и аналогично для Ryzen 7 3700Х, при этом остальные ядра отключались полностью (не через диспетчер задач и не через маскировку).
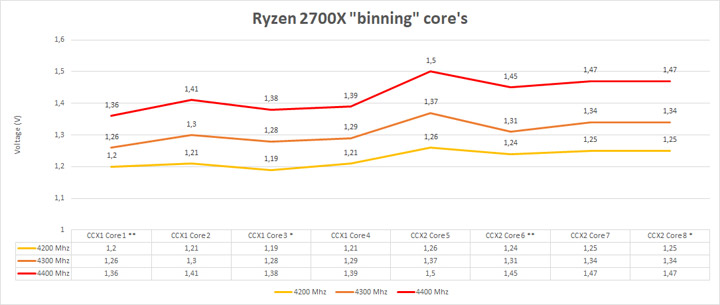
В случае с Ryzen 7 2700Х была найдена зарытая собака. Статус ядер отмеченными звездочками и кружками не соответствовали действительности. В случае моего экземпляра Ryzen 7 2700Х ядро 5 было самым неудачным, притом, что было промаркировано как удачное. Именно из-за него и ряда других кремневых соседей «неудачников» ручной разгон с помощью фиксации множителя требовало значительное повышение напряжения, что в свою очередь приводило к чрезмерному росту TDP. Ошибка маркировки не коснулась заявленной производительности с коробки, но маневр с использованием потенциала перестал иметь место быть. При правильной же маркировке 4500 МГц не были б проблемой для среднестатистического серийного образца. Так же отсутствие ручного перераспределения маркировки ядер делает нецелесообразным дальнейший тюнинг BCLK для моего экземпляра.
Для 3700Х ситуация выглядит немного иначе.
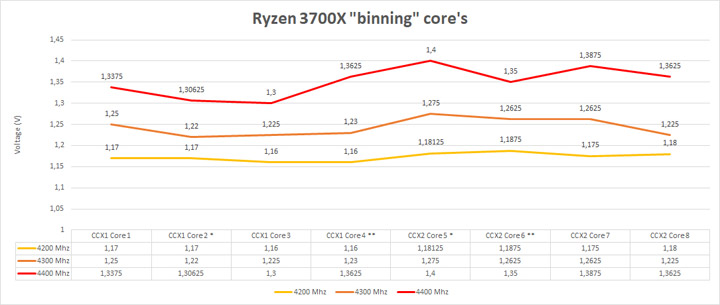
Ядра до 4300 МГц включительно имеют очень схожие вольт-частотные характеристики, что безусловно является маркером совершенства 7-нм техпроцесса и делает возможным ручной разгон через множитель. Между 4300 и 4400 МГц существует небольшая пропасть, которая говорит о том, что для этого экземпляра значение 4400 МГц являются предельными, и как такового запаса для дальнейшего адекватного разгона нет. Протестировать 4500 МГц мне не удалось, так как система отказывалась стартовать при любом напряжении, скорее всего это связано с сыростью прошивки материнской платы. Маркировка ядер частично совпадает. Безусловно, использование правильной маркировки позволило б при тех же напряжениях достигать процессору больших частот в нагрузке 1–4 ядер. Аналогично картинке с результатами анализов Ryzen 7 2700Х можно заметить, что в обоих случаях CCX2 требует немного большее напряжение для всех своих ядер. Мне сложно дать объяснение данному феномену ибо запитка ядер довольно дифференцированная и производится с обоих концов CCD.
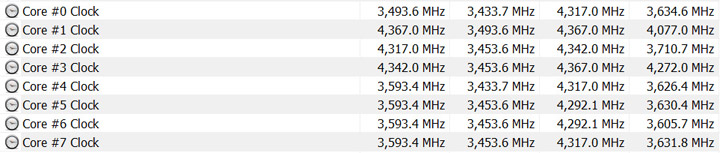
Буст в однопотоке примерно выглядит следующим образом: 4367 МГц с максимальным временем на четвертое ядро, далее идет второе ядро. То есть ядра, которые были промаркерованы заводом.
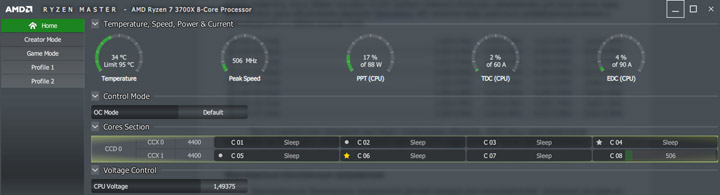
Принудительное включение CPPC в биосе не изменило ситуацию и система все так же продолжала выбирать неоптимальные ядра для максимального буста.
Максимально-безопасные напряжения
Максимальное безопасное напряжение вечная загадка для пользователей, поскольку ни один из двух производителей не публикует эту информацию для общественного обозрения. Кто-то просто указывает смешные 95Вт для процессора, работающего на частоте 5 ГГц, или забывает установить ограничение пакетной мощности. В документах, которые находятся не под NDA, обычно указывается неопределенный предел, который в большинстве случаев относится к точке, в которой катастрофические сбои становятся более распространенными. Указания напряжений, которые безопасно использовать 24/7, не причиняя никакого вреда процессору, остаются за ширмой.
Такой предел довольно сложно определить, поскольку этот предел будет варьироваться между различными образцами ЦП (кремниевая дисперсия, SIDD), ядрами в CCX и рабочими сценариями (пиковый ток для определенного кол-ва ядер, температура и так далее).
Чтобы получить наиболее точный ответ на вопрос о пределе, мне пришлось самому замерять его у процессоров, основанных на архитектуре Zen+ и Zen 2.
Начнем с терминов, которые будут встречаться в этой статье чаще всего.
PPT — отслеживание мощности пакета.
TDC — расчетный электрический ток.
EDC — тепловая защита.
FIT — это функция для мониторинга/отслеживания работоспособности кремния и корректировки рабочих параметров для поддержания заданной и ожидаемой надежности. Многие производители полупроводников используют эту функцию, чтобы добиться максимальной производительности в ряде задач.
Представьте себе запуск ракеты в космос. В первые милисекунды взлета блок управления дает задачу двигателю развить максимальную проектную мощность, дабы произвести отрыв от земли. За дальнейшие секунды полета уже отвечают команды, которые являются анализ-ответом на опрос датчиков. В предыдущей главе мы уже выяснили, что суммарное количество датчиков исчисляется несколькими тысячами. Это дает представление, что мы имеем дело с аналогичной ракетой, которая является процессором.
Чтобы увидеть, какое значение фактического максимального напряжения FIT позволяет ЦП использовать в различных сценариях, достаточно отключить все ограничения, а если быть точным, перейти в режим Precision Boost Override = Manual и ввести значения 1000 1000 1000 для PPT, TDC и EDC. При отключении любого ограничителя FIT становится единственным ограничением, который спасает процессор от смерти. Команда напряжения, которую процессор посылает в регулятор VRM через интерфейс SVI2, является фактически тем самым эффективным значением напряжения, которое получает процессор.
В дефолте мой Ryzen 7 2700Х продемонстрировал максимальное эффективное напряжение во время нагрузки, разрешенное FIT, 1,330 В. В одноядерной нагрузке устойчивый максимум составлял 1,425 В.
Когда параметр FIT был изменен с помощью настройки Scalar со значения по умолчанию 1x до максимально допустимого значения 10x, максимальное напряжение для всех ядер составило 1,380 В, а максимальное напряжение для одного ядра возросло до 1,480 В.
Данные результаты говорят о том, что полноценная надежность для Ryzen 7 2700Х и 12-нм тепроцесса находится на уровне 1,33 В с максимальным током и 1,425 В с минимальным током в нагрузках на одно ядро.
Что касается более высоких напряжений, то FIT допускает вариант 1,380/1,480 В, но это возможно приводит к сокращению срока службы процессора или деградации.
Это позволяет подвести черту и сделать вывод о топовых настольных процессорах семейства Zen+. На этом бы я эксперимент закончил, если б не моя привычка проверять результаты. Поясню. Данные результаты были получены на инженерной прошивке, в которой не было ничего заблокировано и не было пределов. И не блокируется это для воспроизведения экстремальных ситуаций и дальнейшего интерполирования результатов чтоб создать симуляции поведения того или иного продукта в будущем. В итоге была проверена линейка UEFI за весь 2018 год, которые получают конечные пользователи. Как оказалось, в них настройка Scalar превратилась в пустышку, и она всегда находилась в режиме 2x. То есть, результаты поздних симуляций вынудили AMD изменить пределы для лучшей безопасности ваших «камней». Пределом для Ryzen 7 2700Х является 1,367/1,45 В.
Для процессоров Matisse с одним CCD это выглядело таким образом: для нагрузки на все ядра с максимальным током 1,325 В, а для одного ядра – 1,419 В. Имейте ввиду что эти цифры безусловно будут отличаться между различными образцами процессоров (из-за SIDD и биннинга), в частности между серией с двумя чиплетами и одним.
Также хочу обратить ваше внимание на то, что приведенные здесь цифры относятся к фактическому эффективному напряжению, а не к напряжению, запрашиваемому ЦП (VID). Процессор знает только о фактическом эффективном напряжении, поэтому такие вещи, как LLC, соответственно изменят запрос напряжения процессора от контроллера VRM. Наиболее точный метод измерения эффективного напряжения на платформе AM4 — это мониторинг напряжения «CPU SVI2 TFN», которое доступно всем в HWInfo. Данное значение является наиболее точным из всех доступных для конечных пользователей, но, безусловно, будет иметь отличия от хардварного мониторинга. В качестве примечания, хочу отметить один момент — никогда не следует слепо доверять показаниям тока и мощности, которые мониторятся, поскольку каждая модель материнской платы нуждается в отдельной калибровке.
Предисловие
Любой ручной разгон это отказ пользователя от гарантии на продукт и все действия совершаются на собственный страх и риск.
Одним из самых главных условий стабильности системы в разгоне, это правильно настроенные фазы и режим компенсации во время нагрузки. К счастью большинство материнских плат для процессоров Ryzen не обделены в настройках и позволяют пользователю достаточно гибко настроить систему.
Главными ингридентами этого салата являются :
CPU VRM switching frequency — включение автоматического или ручного режима управления частотой VRM модуля питания процессора. Задает рабочую частоту для преобразователя напряжения питания процессора. Чем она выше, тем более стабильным является напряжение питания на выходе. Однако увеличение частоты переключения транзисторов ведет к дополнительному нагреву компонентов модуля VRM. В большинстве случаев будет достаточно 400 кГц для мидл-сегмента и 600–800 кГц для сегмента топ-плат.
CPU Power Duty Control — модуль контроля компонентов каждой фазы питания процессора (VRM). На платах ASUS имеет два положения:
- T.Probe — модуль ориентируется на оптимальный температурный режим компонентов VRM.
- Extreme — поддерживает оптимальный баланс VRM фаз.
В первом случае количество работающих фаз будет обусловлено нагрузкой на процессор и в большинстве случаев все фазы одновременно будут редко задействованы. Во втором же режиме мы принудительно задействуем все фазы для любой нагрузки. По моему мнению именно второй режим будет оптимален.
На платах MSI и других вендоров названия могут варьироваться, но суть останется та же. К примеру, на MSI доступны режимы Thermal Balance и Current Balance.
CPU Current Capability — обеспечивает широкий диапазон суммарной мощности и одновременно расширяет диапазон частот разгона. В платах ASUS мое предпочтение это 120–130%.
Load line calibration (LLC) — управление надбавочным напряжением процессора во время нагрузки. Существует, чтобы обеспечить большую стабильность при разгоне и компенсировать колебания высокого и низкого напряжения (поддерживать линию напряжения на CPU больше стабильной).
Ничто не разрушает компонент ПК быстрее, чем нестабильность. Когда ваша система работает на холостом ходу, она отлично выдерживает напряжение, установленное в UEFI. Однако при тяжелой нагрузке напряжение вашего процессора падает и повышается во время бездействия. Своего рода качели, которые имеют Vdroop.
В разгоне Vdroop может вызвать проблемы со стабильностью, поскольку процессор потребует определенного уровня напряжения для поддержания заданной/требуемой частоты. Установка правильных калибровочных значений нагрузки может исправить это.
Ключевой особенность LLC является обеспечение дополнительного напряжение при увеличении нагрузки и только при необходимости, сохраняя при этом максимальное значение Vcore, которое вы установили. Это гарантирует, что вы только компенсируете «потерянное» напряжение и не вызовет «перевольтаж».
Четкой рекомендации, какой уровень выставить, я дать не могу, потому что каждая материнская плата у каждого вендора является индивидуальностью, но подсказку дам.
Читаем обзор вашей материнской платы и смотрим на результаты тестирования режимов LLC. Нас будет интересовать режим, который делает Vdroop самым маленьким (отрицательным), но, ни в коем случае не положительным, ибо это повлияет на срок службы процессора и VRM материнской платы.
CPU Over Voltage Protection, CPU Under Voltage Protection и CPU VRM Over Temperature Protection мы оставляем в автоматическом режиме, это защита компонентов от «выгорания».
Ручная установка множителя
Оптимальный режим для процессоров без суффикса «Х» поколения Zen и Zen+. И наверно это самый банальный способ разогнать процессор, который в большинстве случаев не потребует углубленных знаний.
Устанавливаем CPU Core Ratio, он же множитель. Для процессоров поколения Zen рекомендуемые значения находятся в диапазоне 38–40.
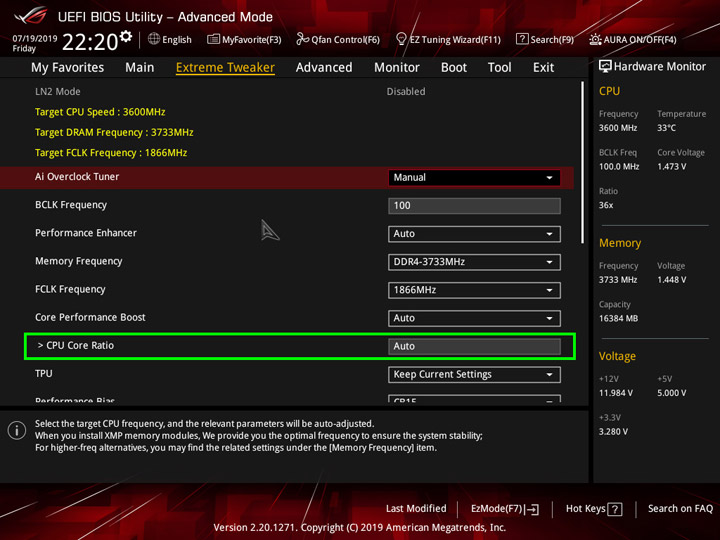
И задаем напряжение для процессора именуемое CPU Core voltage. Точных значений ввиду того что каждый экземпляр имеет разные вольт-частотные характеристики нет. Подскажу диапазон 1,3–1,4 В. Дальше сохраняемся и идем в Windows тестировать. Я предпочитаю LinX, прогонов 5–10, объем памяти 6–8 Гбайт. Наблюдаем за температурами (Tdie) и напряжением CPU Core Voltage (SVI2 TFN) с помощью HWInfo. Максимально безопасные температуры находятся в диапазоне 70–80 градусов.
Если гаснет экран или компьютер перезагружается — недостаток напряжения, как и в случае, если LinX пишет об ошибке или есть невязки со знаком «+».
Precision boost overdrive + BCLK + Offset voltage ( процессоры Zen+ и Zen 2 с суфиксом «Х»)
Хочу сделать важную оговорку. В большинстве последних прошивок исчезло большинство настроек, которые нам потребуются для данного вида разгона. По моим наблюдениям рекомендуемые UEFI основаны на AGESA Pinnacle PI 1.0.0.0a–1.0.0.2c. Если нашли сейчас — отлично, пробуем.
- Ищем Precision Boost Overdrive у себя в UEFI, зачастую он лежит в AMD CBS.
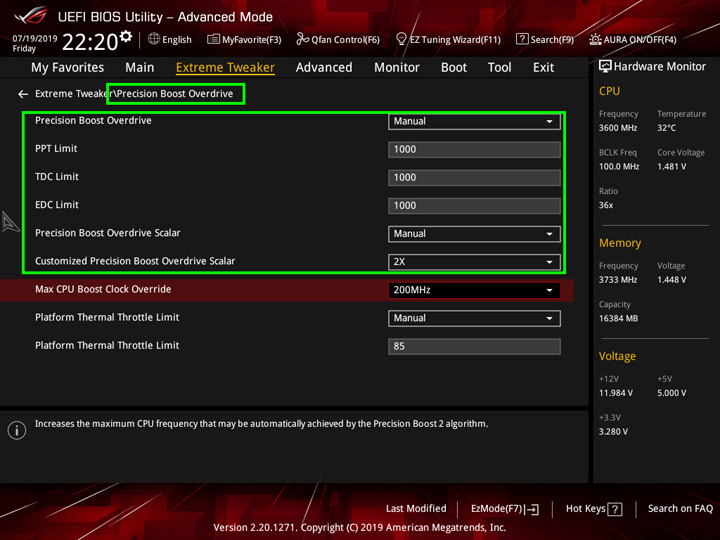
- Задаем для PPT, TDC и EDC значения по 1000. То есть снимаем ограничение.
- Задаем Customized Precision Boost Overdrive Scalar в диапазоне 2x–6x. От этого значения будет зависеть минимальная частота на все ядра, и чем скаляр выше, тем выше частота.
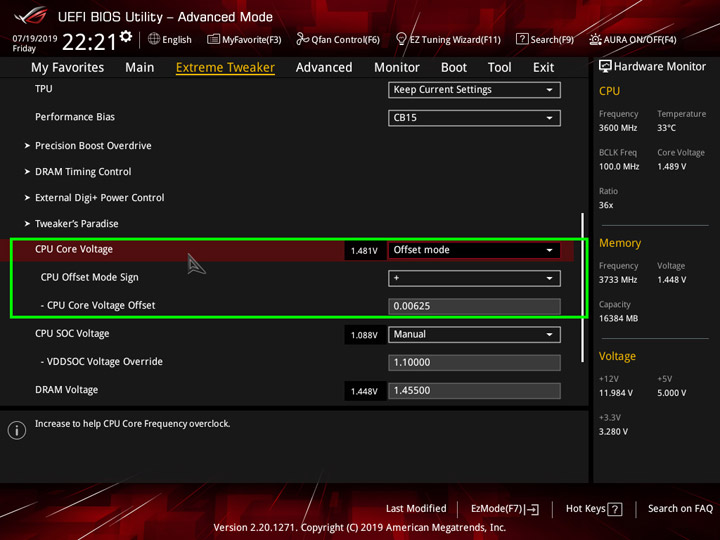
- Задаем CPU Core Voltage с помощью режима CPU Offset Mode + с самым минимальным значением. Сохраняемся и идем в Windows тестировать.
Пакет Linx или же игра, если вас не интересуют нагрузки связанные с AVX. Мониторим частоты, напряжение и температуры. Если система зависла или нестабильна, идем в UEFI и увеличиваем наш оффсет с пункта 4 на шажок. Повторяем процедуру пока не получаем удовлетворительный результат либо снижаем Scalar и снова подбираем подходящее напряжение.
Если напряжение в HWInfo во время нагрузки больше 1,47 В, вам стоит вернуться в UEFI и перейти в режим CPU Offset Mode. Так же начинаем с самого минимального напряжения, ходим в Windows, чтобы проверить стабильность или результат и в случае чего возращаемся чтоб скорректировать оффсет.
Если вы с этим всем разобрались, то можете попробовать еще больше увеличить буст с помощью BCLK (если он, конечно, есть в меню UEFI). Диапазон значений 100–103 МГц.
Имейте ввиду, что изменение BCLK потребует и изменения рабочего напряжения.
В идеале с помощью данного метода реально добиться частот в однопотоке 4470 МГц, без каких либо угроз для жизни процессора.
Для обладателей ASUS ROG Crosshair VI, VII и VIII существуют пресеты, которые не требуют настройки первых трех пунктов. Эти пресеты именуются как Perfomance Enchancer. Вам нужно выбрать LVL 2 или 3, плюс задать напряжение процессору через оффсет. И собственно все.
Precision boost 2 + Offset voltage (Zen 2)
Очень интересная технология, которая не имеет пакетных ограничений, присутствующие в PBO. Единственное ограничение — температура процессора. Соответственно, чем холоднее процессор — тем больший буст будет и на одно ядро и на все ядра. Большой акцент в данном случае должен быть уделен вашей материнской плате (VRM), охлаждению и разумеется хорошо продуваемому корпусу:
- Ищем Precision Boost Overdrive у себя в UEFI и жмем в нем Disable.
- Задаем MAX CPU Boost Clock Override, диапазон 0–200 МГц. Это та частота, которая будет добавлена к максимальному бусту с коробки.
- Задаем CPU Core Voltage с помощью режима CPU Offset Mode + с самым минимальным значением. Сохраняемся и идем в Windows тестировать.
Нюанс. Недостаток напряжения запускает в этом случае технологию Clock Stretcher, которая постоянно мониторит состояние напряжений относительно нагрузки и если замечена сильная просадка напряжения (Vdd drops) — технология спускает частоту, чтобы уберечь систему от сбоя.
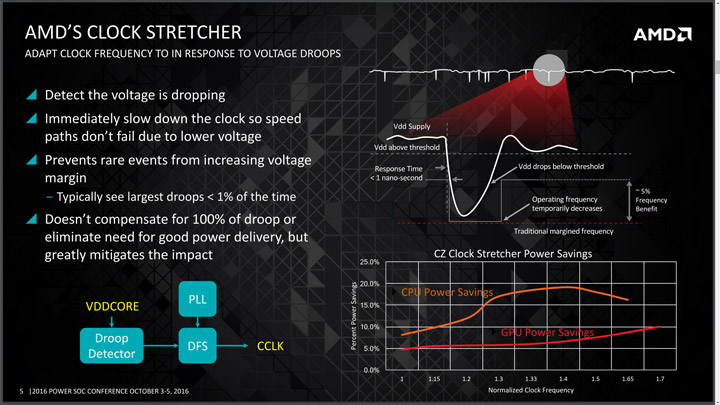
Потому вам следует найти такое напряжение, которое позволит процессору выходить в максимальный буст, при этом напряжение не будет выше 1,45–1,47 В.
Undervoolt (Zen+ и Zen2)
Понижение напряжения («даунвольтинг» или «андервольтинг») — процесс, который позволяет уменьшить энергопотребление и тепловыделение, не влияя на производительность системы. То есть мы получаем маржу (запас) между текущими показаниями и заводскими лимитами. Этот запас мы можем сразу же использовать в виде возросших частот.
К счастью делается андервольт проще, чем предыдущие четыре строчки. Задаем CPU Core Voltage с помощью режима CPU Offset Mode + с самым минимальным значением. Сохраняемся и идем в Windows тестировать наш результат. Возможно, самое минимальное значение напряжение может оказаться недостаточным для получения частот, которые мы имели в стоковом состоянии процессора. Для этого мы пошагово добавляем оффсет и смотрим на наш результат.
Хочу обратить ваше внимание на один момент — оффсет у всех процессоров будет разный ввиду уникальности каждой модели процессора, как в плане характеристик кремния, так и в плане базовой точки напряжения от которой действует оффсет. То есть все процессоры уровнять не получится и дабы не ждать часами ответа на форуме с вопросом «от какого напряжения будет двигаться офсет?», мы выставляем самое минимальное значение оффсета и идем смотреть результат в HWInfo. Для наглядности я вам предоставлю формулу как выглядит результирующее напряжение. CPU Core Voltage (SVI2 TFN) = Base Core Voltage + Offset voltage в случае если вы выбрали оффсет положительный и CPU Core Voltage (SVI2 TFN) = Base Core Voltage – Offset voltage если вы выбрали отрицательный оффсет. Вот собственно и все.
И последнее, результат (функциональность) того или иного метода разгона будет зависеть от прошивки, а если быть точнее, от лени производителя материнских плат. Вам может быть дана функция оффсета, но она может не работать, будьте готовы и к такому повороту события. Безусловно, в этом случае форум будет самым главным вашим помощником.
Разгон ОЗУ
Ввиду того, что на данный момент присутствуют некоторые сложности с UEFI (баги и спорные моменты, которые в ближайшее время будут откалиброваны) я затрону только ключевой вопрос, который так волнует пользователей, а именно масштабируемость производительности при разгоне оперативной памяти.
Интересной информацией, которая не попала в Сеть, является измененный рабочий procODT (на любой материнской плате), теперь оптимальный диапазон находится в переделах 28–36,9 Ом для одноранговой памяти и 48-60 Ом для двуранговой. Рабочие RTT остались теми же что и были.
Также Matisse представил новую настройку напряжения, которая называется CLDO_VDDG. VDDG — это напряжение IF, как могли догадаться, отвечает за целостность данных IF. Существует для стабилизации высоких частот FCLK. CLDO в названии означает, что в напряжении используется стабилизатор выпадения (LDO = низкий уровень выпадения).
Так как CLDO_VDDG и CLDO_VDDP регулируются из плоскости VDDCR_SoC, существует правило установки VDDG. Напряжение SoC должно быть выше, чем запрошенный VDDG. По умолчанию оно составляет 0,950 В, однако некоторые материнские платы могут превышать уровень по умолчанию даже при стандартных настройках.
Моя рекомендация использовать ручное VDDG со значением 0,95 В (хватает для разгона FCLK до 1800 МГц включительно) или же держать интервал 0,05 В между ним и SoC, в противном случае система не будет использовать пользовательские настройки VDDG. Безопасный предел для VDDG до 1,1 В включительно.
CLDO_VDDP советую вообще не трогать, 0,9 вольт замечательное число, которое позволяет тренировать память на частотах 2133–4333 МГц. «Memory Holes» на моих экземплярах обнаружено не было.
Сниженного аппетита к напряжению DRAM я не заметил. Тайминги зажимаются аналогично, без каких-либо сюрпризов, потому вы можете использовать с легкостью конфигурации с прошлого Ryzen.
Насчет режимов 2:1 и 1:1. Переключение между ними автоматическое, после того как память достигла 3600 МГц идет автоматический переход в режим 2:1, но так как присутствует запас по частоте UCLK/FCLK 1900 МГц режим 1:1 можно вернуть, выставив в FCLK значение, равное половине от эффективной частоты оперативной памяти. Из особенностей это колдбут при переходе в режим 2:1 или 1:1, он будет всегда, так как режимы задействуют либо один тактовый генератор процессора, либо тактовый генератор процессора и материнской платы сразу (не у всех материнских плат стоит внешний тактовый генератор BCLK, не стоит скидывать со счетов и это). Второй нюанс — POST-код на материнской плате «07» означает, что лимит FCLK достигнут по той или иной причине и зачастую наваливание напряжения на VDDG просто не даст никакого результата.
И самое главное, не используйте для регулировки какого либо параметра Ryzen Master, он еще крайне сырой. Я использовал его только для мониторинга, хотя он не всегда говорил правду.
В качестве доказательств я продемонстрирую тест стабильности пресетов, которые использовались в этом гайде-обзоре.
Тестовые конфигурации
Тестовый стенд №1:
- процессор: AMD Ryzen 7 2700X;
- система охлаждения: NZXT Kraken X62;
- материнская плата: MSI X470 GAMING M7 AC (V1.94 , AGESA 1.0.0.1);
- память №1: G.Skill Sniper X 3400C16 (2x8GB, Samsung B-die 20 nm, Single Rank);
- память №2: G.Skill Trident Z 3000C14 (2x16GB, Samsung B-die 20 nm, Dual Rank);
- видеокарта: MSI GeForce GTX 2080 Ti GAMING X TRIO;
- накопитель: Samsung 970 Pro 512GB;
- блок питания: Corsair HX750i;
- операционная система: Windows 10 64-bit 1903;
- драйвер чипсета: 1.07.0725;
- драйвер видеокарты: NVIDIA GeForce 431.36 WHQL.
Тестовый стенд №2:
- процессор: AMD Ryzen 7 3700X;
- система охлаждения: NZXT Kraken X62;
- материнская плата: ROG Crosshair VIII Hero (WI-FI) (0702, AGESA 1.0.0.3AB);
- память №1: G.Skill Trident Z Royal 3600C16 (2x8GB, Samsung B-die 20 nm, Single Rank);
- память №2: G.Skill Trident Z 3000C14 (2x16GB, Samsung B-die 20 nm, Dual Rank);
- видеокарта: MSI GeForce GTX 2080 Ti GAMING X TRIO;
- накопитель: Samsung 970 Pro 512GB;
- блок питания: Corsair HX750i;
- операционная система: Windows 10 64-bit 1903;
- драйвер чипсета: 1.07.0725;
- драйвер видеокарты: NVIDIA GeForce 431.36 WHQL.
Результаты тестирования
AIDA64
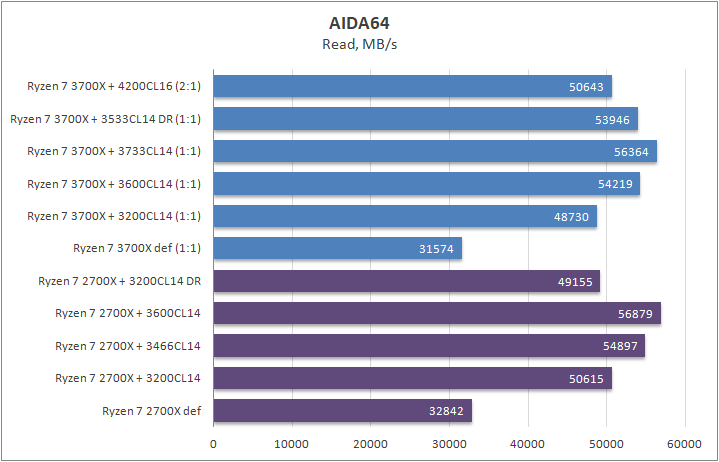
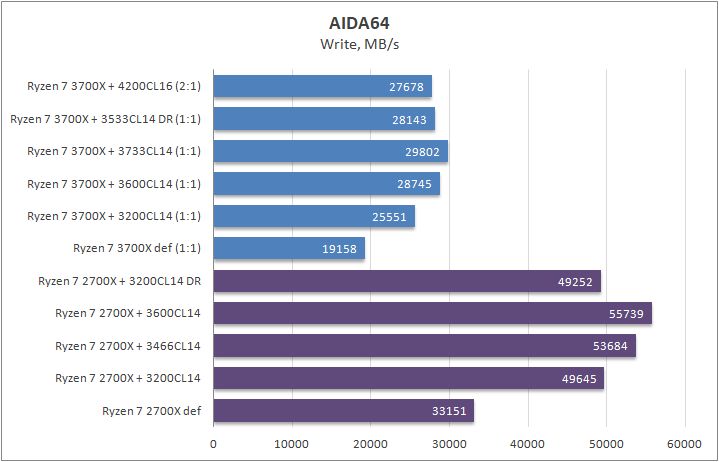
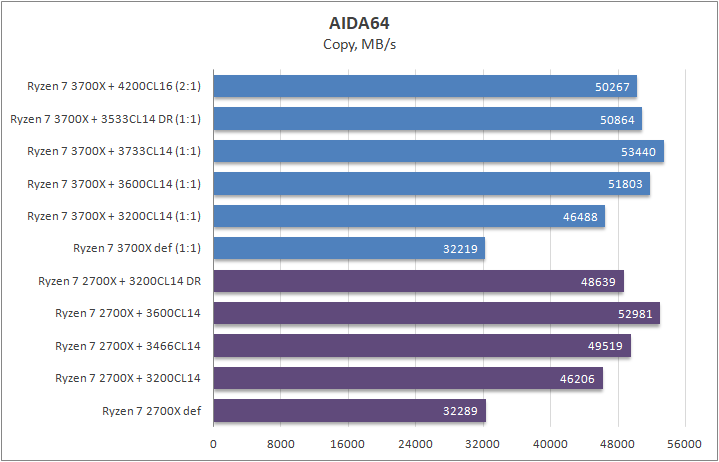
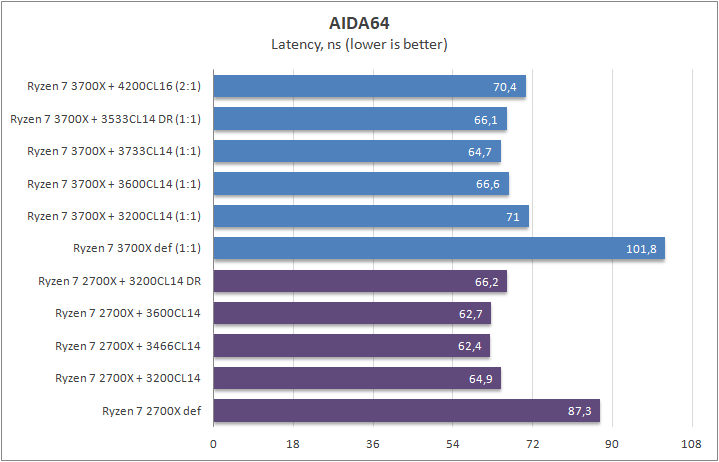
Результаты довольно предсказуемые, запись у одночиплетного процессора просела, тем не менее, в играх проблем этот «недостаток» не вызвал. Те, кто только что к нам присоединились, советую прочесть теоретическую часть, в которой я объяснил, почему это не является какой либо потерей.
Латентность новое поколение продемонстрировало немного худшую, нежели предшественники. Причина проста — контроллер памяти теперь соединен через шину и не находится вблизи комплекса ядер. Насколько критично? Смотрим дальше.
MEMbench
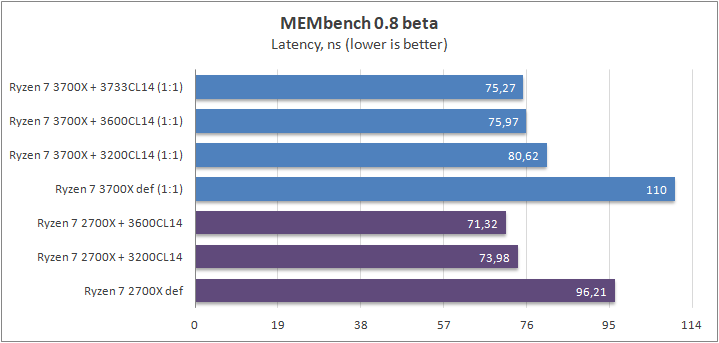
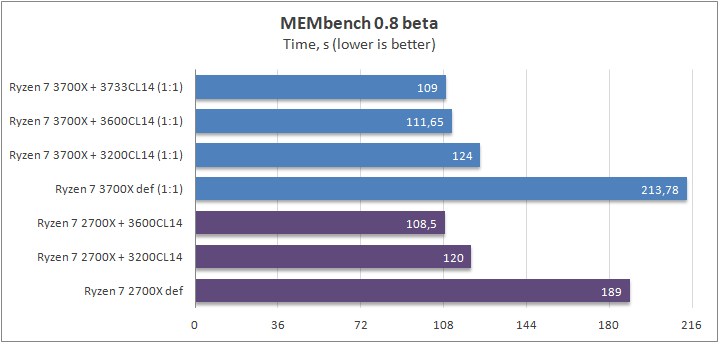
Новобранец на поле боя бенчмарков. Ближе к концу месяца новая версия будет доступна для всех пользователей. Первый тест — это замер латентности. Основная идея заключается в доступе к памяти, который процессор не может предугадать (если вкратце, то чтение элементов массива относительно смещения).
Второй тест — выполнение определенных задач с блоками на скорость. Может предсказать разницу по больнице в играх, поэтому я на него делаю достаточно большую ставку.
Sisoftware Sandra
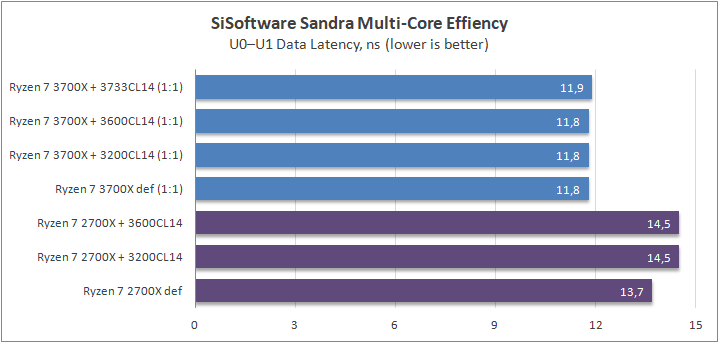
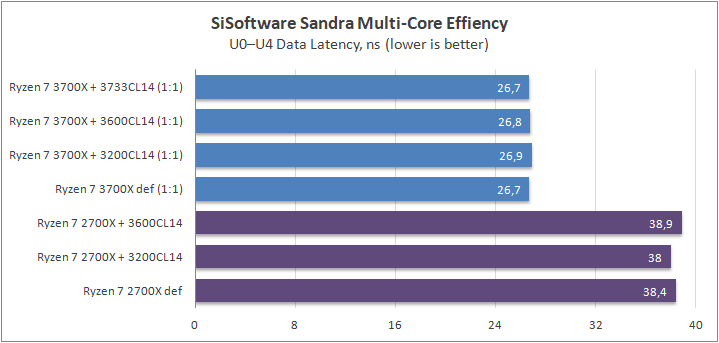
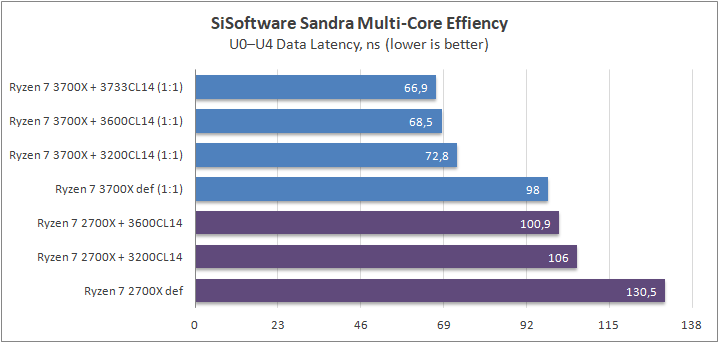
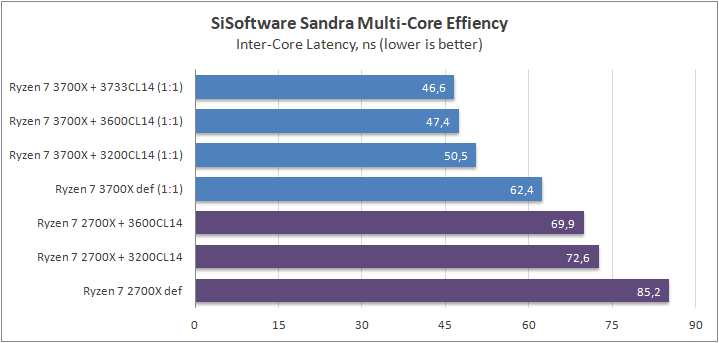
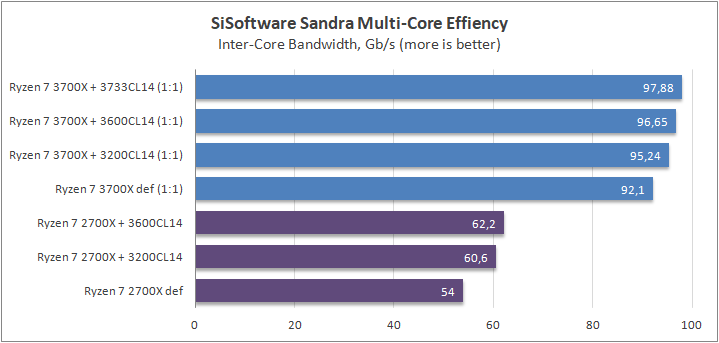
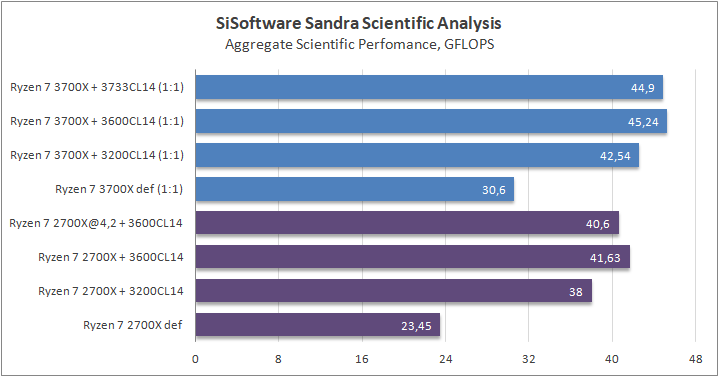
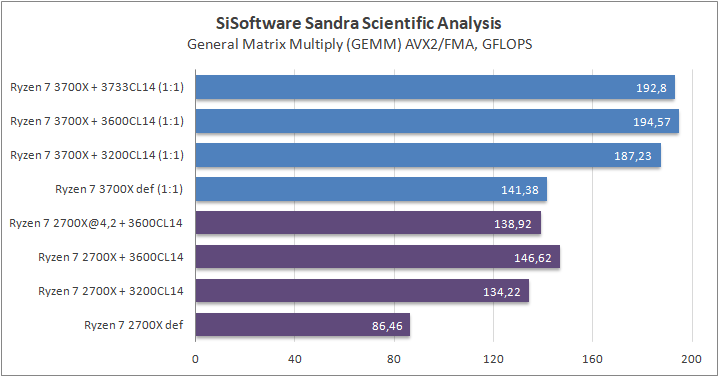
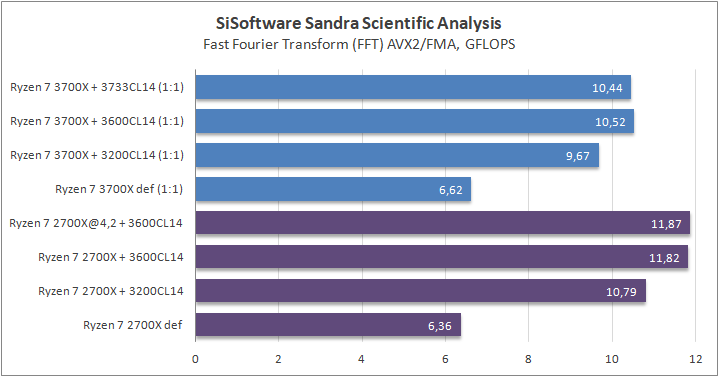
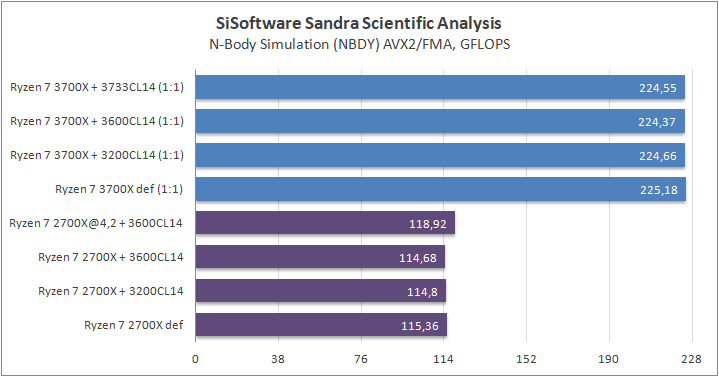
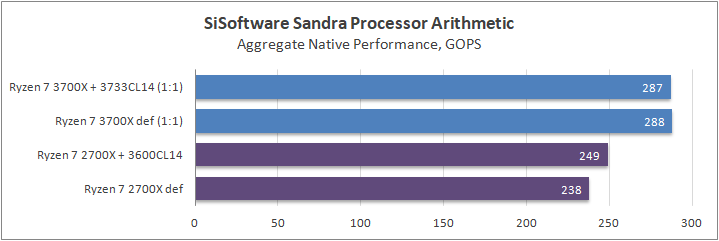
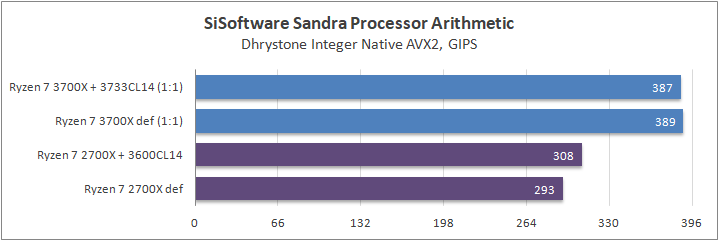
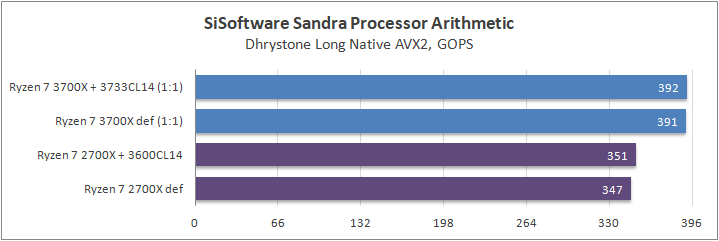
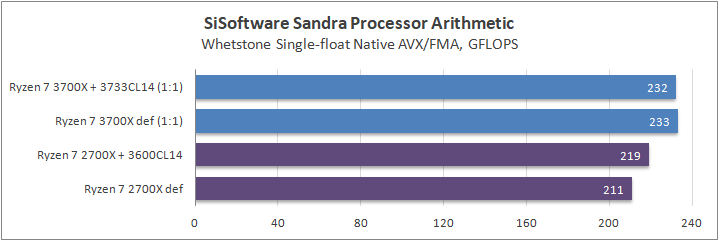
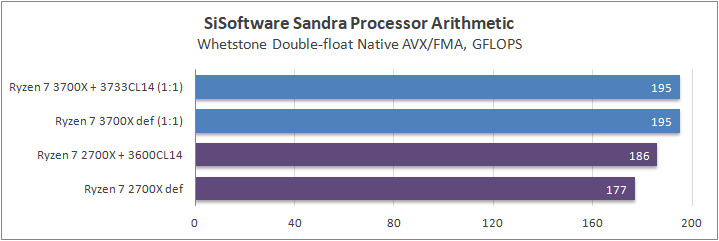
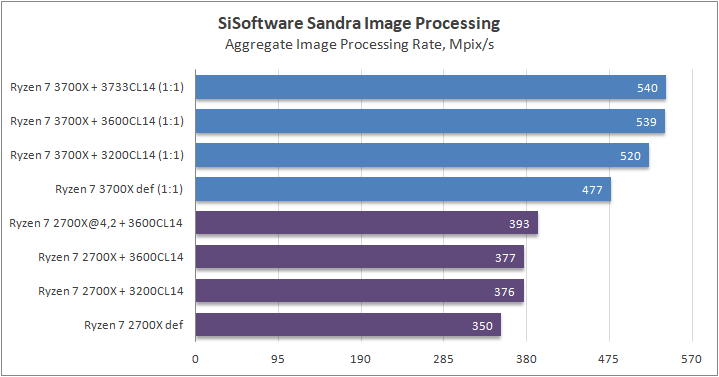
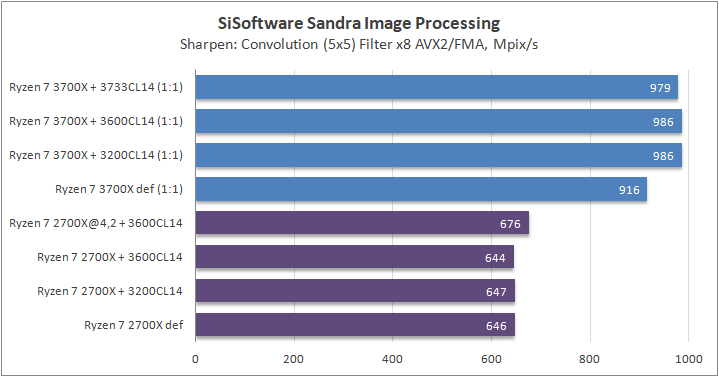
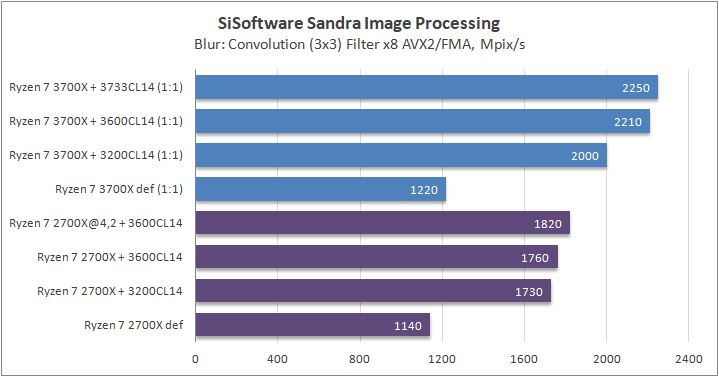
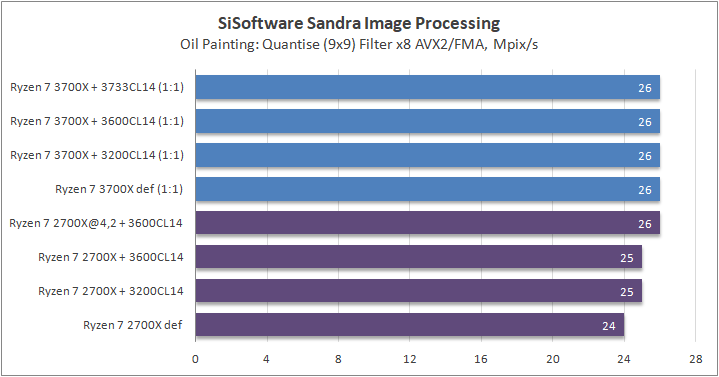
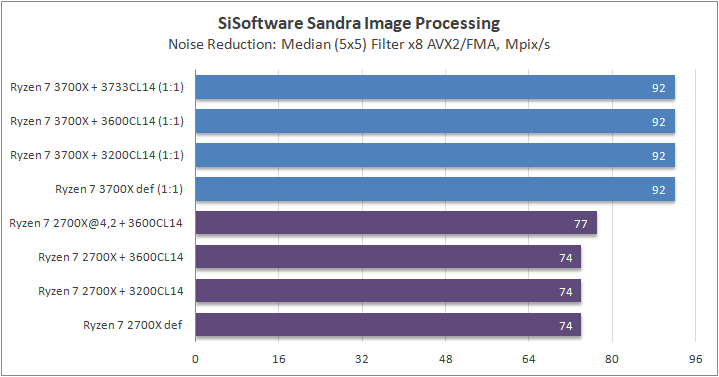
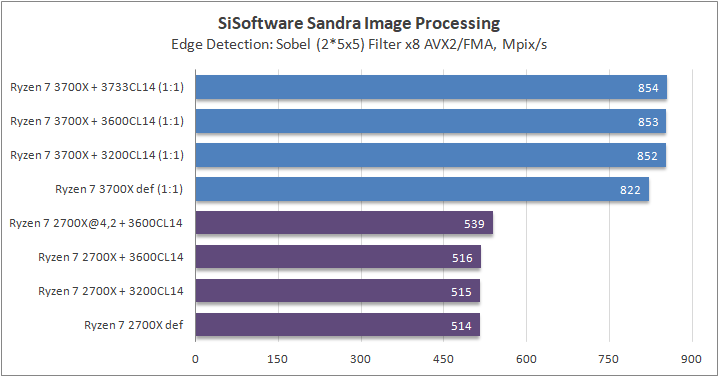
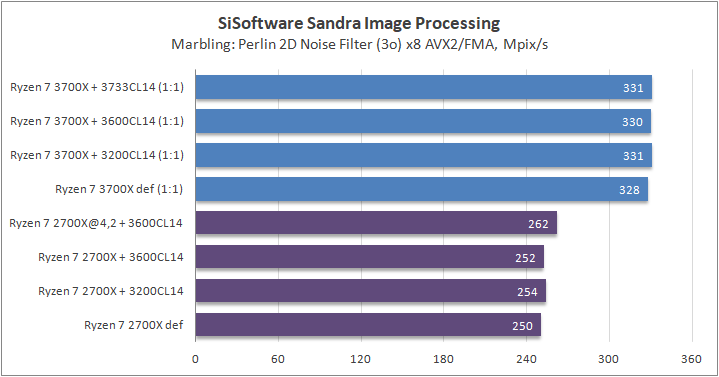
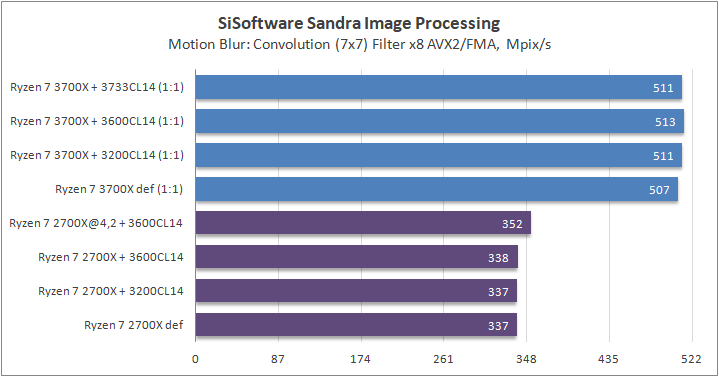
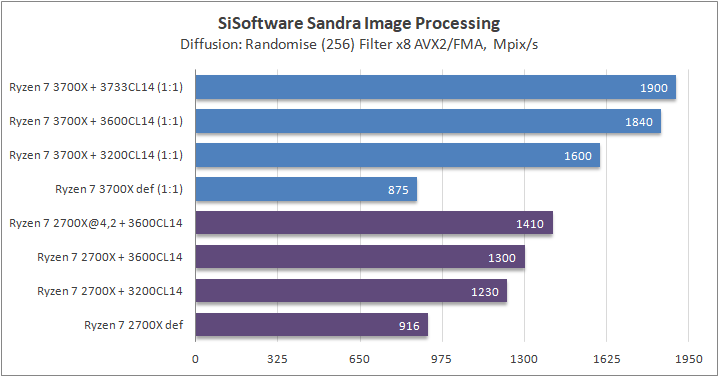
Данный пакет мне нравится тем, что, во-первых, он уже достаточно давно на рынке, во-вторых — ребята следят за обновлениями и, в-третьих, — огромное число тестов, альтернатив которым, по сути, нет.
К примеру, тот же тест эффективности взаимодействия ядер и комплексов между собой. Multi-Core Effiency отлично продемонстрировал изменения, которые были сделаны в архитектуре. Межъядерные задержки в самом лучшем сценарии (U0-U10) имеют разницу в 34% при использовании разгона ОЗУ. Рост пропускной способности между ядрами достиг величины в 96 гигабайт в секунду (!) против 64 Гбайт/с в прошлом поколении. Не могу не упомянуть рост в 2,7 раза математической производительности в пересчете на ватт, что, несомненно, понравится любителям работать с графическими пакетами, которые требуют огромных вычислительных ресурсов.
В качестве примеров я сделал для вас большое сравнительное тестирование в разных задачах, начиная от математического моделирования и заканчивая обработкой фотографий.
y_cruncher
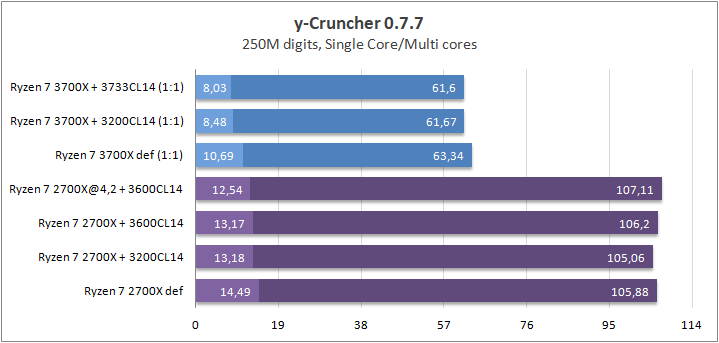
y-cruncher — это программа, которая может вычислять Pi и другие константы в триллионы цифр. Это первый в своем роде многопоточный и прекрасно масштабируемый тест для многоядерных систем. С момента своего запуска в 2009 году он стал одним из главных приложений для бенчмаркинга и стресс-тестирования для оверклокеров и энтузиастов.
Еще одной интересной особенностью этого теста является реакция на разгон Infinity Fabric (FCLK). Из-за снижения задержек между ядрами и комплексами растет многоядерная утилизация, от чего меняется и время вычисления числа Pi (ну или любой другой константы). Удивительно, но для процессоров поколения Matisse я получил на 33% меньшее время вычисления константы, используя разгон ОЗУ. В случае прошлого поколения максимальная разница составляла всего лишь 15%. Подводя итог данного теста, хочу отметить, что разгон ОЗУ может очень сильно повлиять на скорость выполнения оптимизированного многопоточного кода.
AIDA64 Encryption

Данные тесты это скорость процессора при выполнении шифрования по алгоритмам SHA3 и AES. Существенной разницы разгон оперативной памяти не сделал, а если быть точнее ее вовсе не оказалось, даже между разными поколениями.
CB15 / CB20
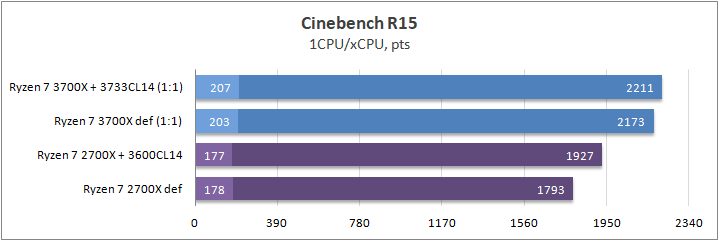
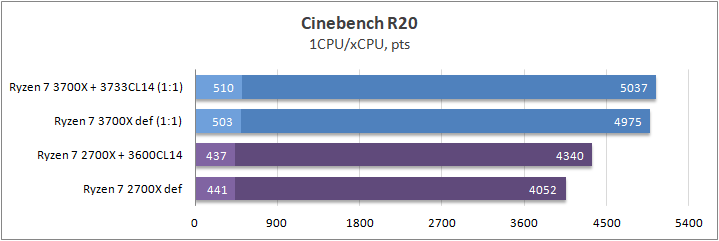
Рендеринг является наверно самой популярной рабочей нагрузкой процессора в наши дни, которую я не имел права обойти стороной. Данные тестовые пакеты являются одними из лучших индикаторов производительности в однопоточной и многопоточной нагрузке. Пакеты для рендернинга отлично откликаются на изменение частоты и IPC.
В итоге поколение Zen 2 обошел своего предшественника на величину до 20% в многопоточной нагрузке и до 15% в однопоточной, что собственно подтверждает заявление компании AMD относительно возросшего IPC. Про частоту в данном случае я не говорю, ибо Ryzen 7 3700Х отказался буститься на одно ядро свыше 4367 МГц даже при отключении лимитов PBO/андервольте или переходе в режим PB2. То есть, тесты в однопотоке можно считать равными. Разгон ОЗУ на результаты почти не повлиял.
Blender
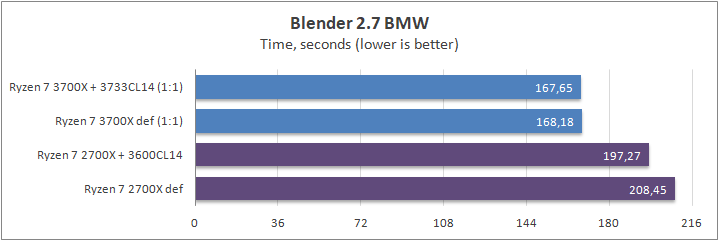
Еще один рендер-пакет. Он продемонстрировал куда большую разницу, нежели его предыдущие сородичи. Максимальный отрыв Zen 2 от Zen+ составил 36%. Разгон ОЗУ на результаты не повлиял.
X265
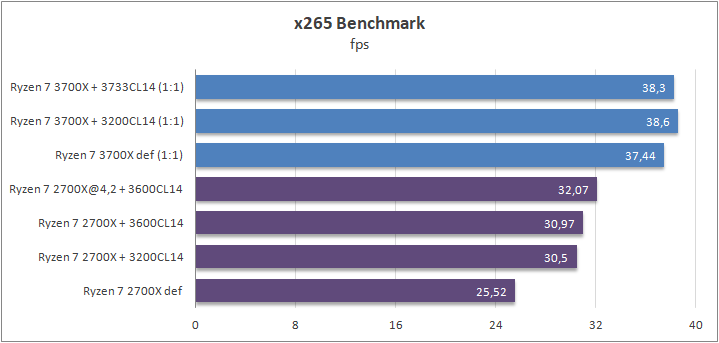
x265 — это открытая реализация нового стандарта кодирования видео H.265 (или по-другому High Efficiency Video Coding (HEVC)). Стандарт H.265 является логическим продолжением H.264 и характеризуется более эффективными алгоритмами сжатия. Разница достигает 46% между Ryzen 7 2700Х и Ryzen 7 3700Х в стоке. Разгон ОЗУ повилял слабо в случае Ryzen 7 3700Х, лишь несколько дополнительных процентов производительности.
Capture One

Популярный пакет обработки фотографий формата RAW. Полученный результат это время преобразования 30 фотографий формата RAW в формат JPG. Прелесть этой программы заключается в многопоточной поддержке и возможности ускорить обработку с помощью видеокарты. В данном тестировании ускорение с помощью видеокарты было отключено.
Почти 25% составил отрыв между Ryzen 7 2700Х и Ryzen 7 3700Х, также было замечено существенное влияние разгона ОЗУ на производительность.
Luxmark
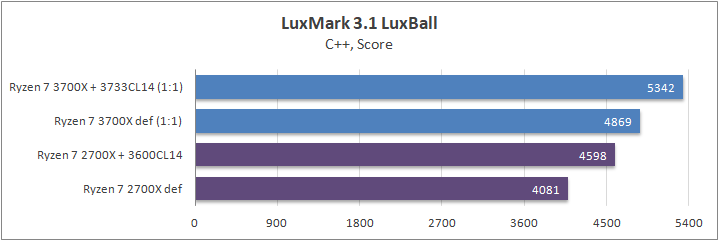
LuxMark является эталонным тестом, разработанным с использованием движка LuxRender, который предлагает несколько различных сцен и API.
В своем тесте я использовал простую сцену «Ball» в режиме C++. Эта сцена начинается с грубого рендеринга и медленно улучшает качество в течение двух минут, давая конечный результат, который, по сути, является «килолучами в секунду».
Разгон ОЗУ для Ryzen 7 3700Х позволил получить дополнительных 10% производительности. Разница между дефолтными состояниями процессора составила около 20%.
Также была попытка протестировать эту цену в режиме OpenCL CPU, но, к сожалению, поддержка OpenCL процессорами AMD была свернута еще в августе прошлого года с пакетом драйверов 18.8.1, хотя в заметках к выпуску об этом не было ни слова. Конечно, нативные приложения CPU работают лучше, чем приложения OpenCL на процессоре, но AMD была пионером в этом направлении и серьезным конкурентом для Intel. Сегодня же поддерживает OpenCL на своих CPU-платформах только Intel.
3DMark Time Spy (CPU)
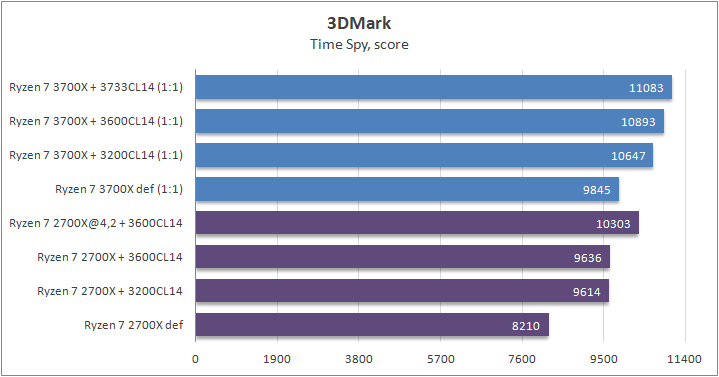
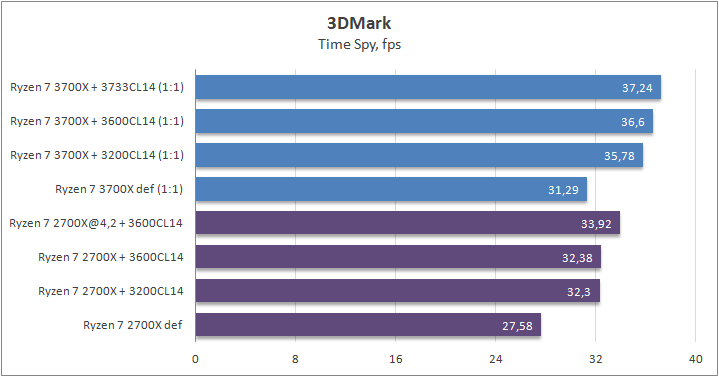
Каждый игровой тест состоит из одной или двух тяжелых сцен для графического процессора, а также физического теста для процессора. Основными о тестами в порядке сложности построения сцен являются Ice Storm, Cloud Gate, Sky Diver, Fire Strike и Time Spy. Я использовал Time Spy, так как он имеет поддержку AVX-512. Предупреждаю сразу, что результаты не являются результатом комби-теста, так как мы сегодня рассматривает процессоры.
13% разницы между стоковыми состояниями процессоров и весомый бонус производительности при разгоне ОЗУ для обеих поколений в размере 20%, что есть очень неплохо и говорит об нужде процессоров в высокоскоростной шины Infinity Fabric.
Игры
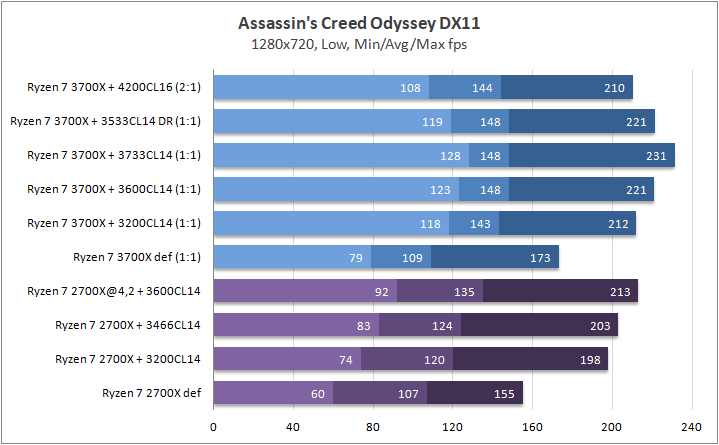
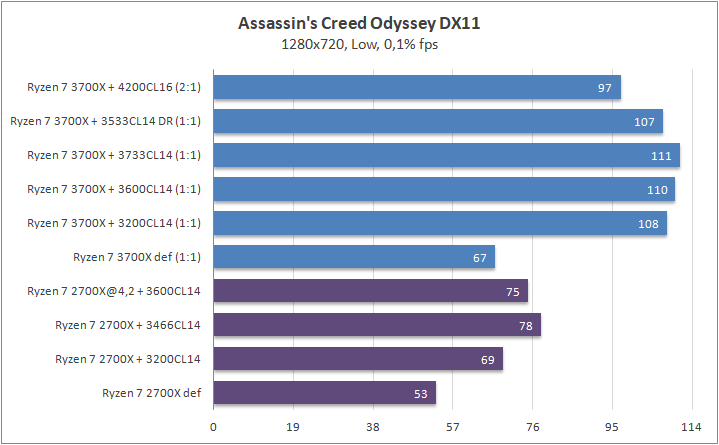
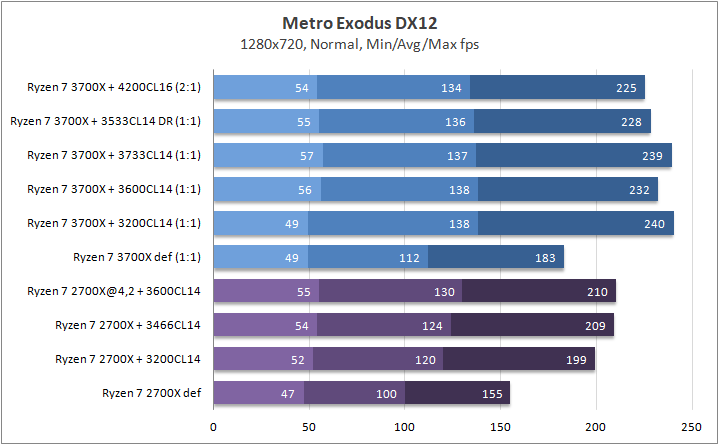
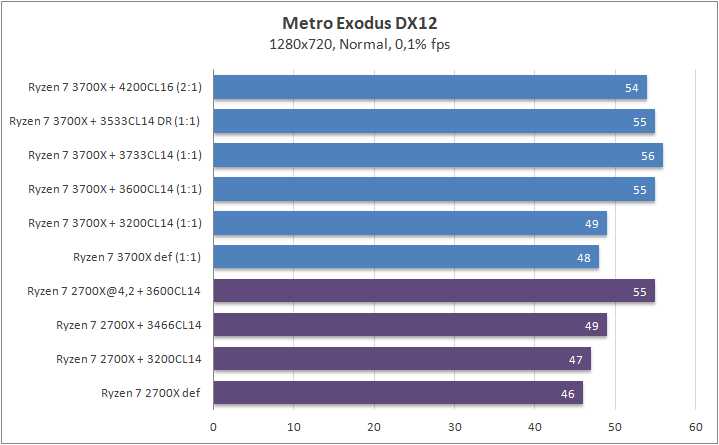
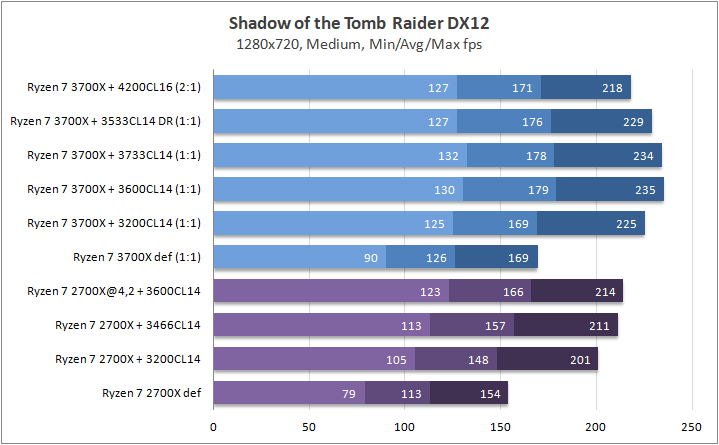
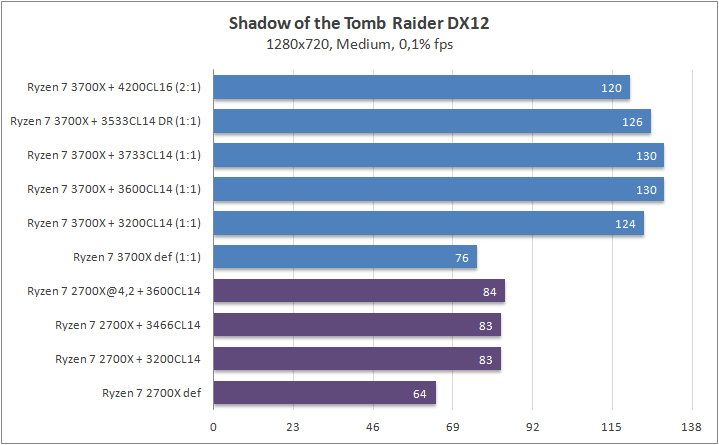
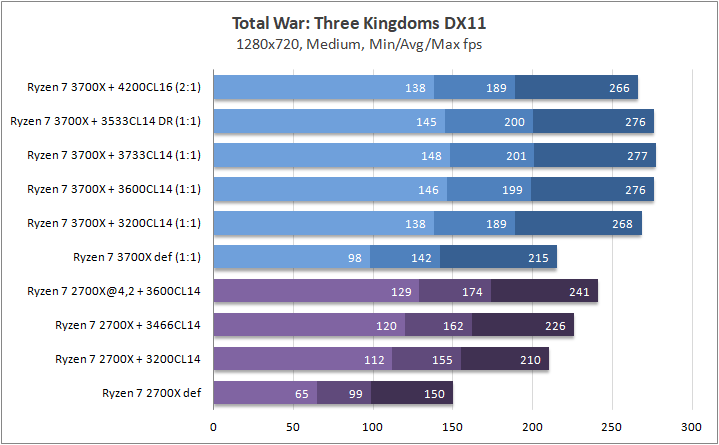
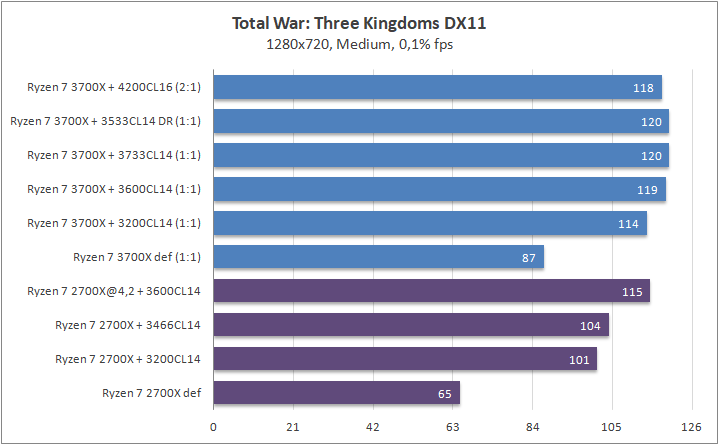
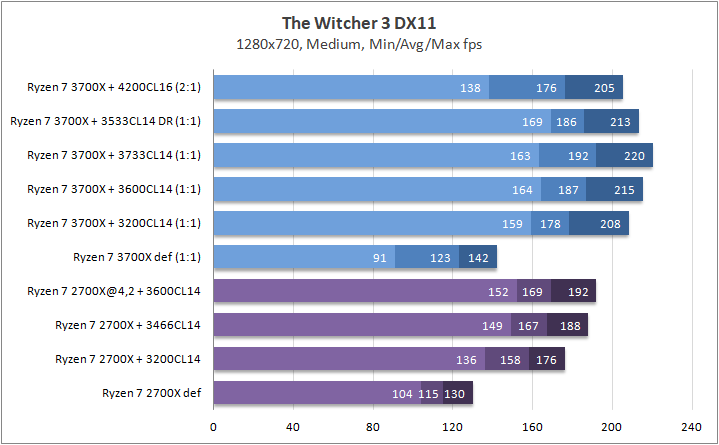
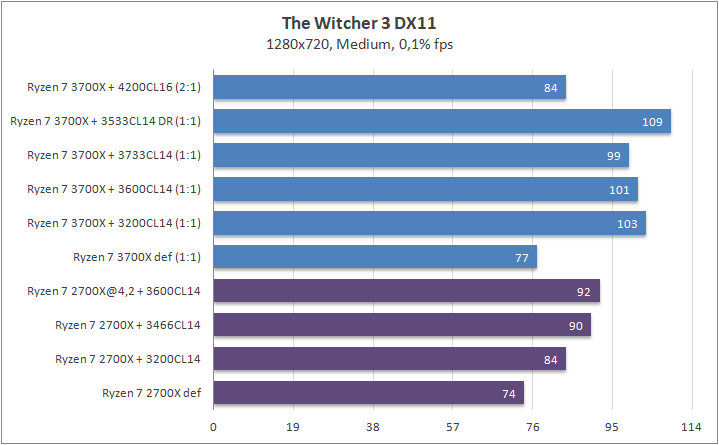
Что касается игр, то почти в любом сценарии был замечен серьезный рост 0,1% fps. Это, безусловно, крутая новость для киберспортсменов, когда ничто и никто не должны влиять на скилл. Средняя частота кадров «по больнице» возросла на 20%, а средняя загрузка видеоядра в субмаксимально низких разрешениях (720p) составила около 70–85%, что говорит нам о том что пора на рынок выпустить что-то посерьезней, чем GeForce RTX 2080 Ti. Я напомню, что это был лишь Ryzen 7 3700Х. С мощью темной красной стороны в лице Ryzen 7 3900Х я познакомлю вас спустя некоторое время.
Выводы
Начнем наверно с минусов. Первое, что морально зацепило многих фанатов, это доступность процессоров в первый день старта продаж. Причина этого явления — приоритет складских запасов для огромных торговых площадок плюс новый уровень защиты от утечек, который повлиял на логистику в целом (в том числе и на мой обзор). Второе, что меня без сомнения впечатлило, это лень производителей материнских плат, тестирование опытных образцов началось на довольно позднем этапе. К примеру, компания MSI до сих пор не родила какой либо финальный UEFI для своего прошлогоднего топа в лице M7 Gaming X (сегодня у нас 29.07.2019), а то что лежит на сайте я просто оставлю без комментариев. Поэтому я был вынужден пересесть сразу на X570 в лице ASUS Crosshair VIII Hero (WI-FI).
Также не могу не отметить странный буст в обзорах первого дня. В большинстве случаев обзорщики не стали следовать рекомендациям AMD и использовать Windows 1903 c чипсетным драйвером 1.07. Тестировали, на чем душе было угодно. Кто-то просто тестировал на не сертифицированной прошивке. В итоге некоторые ресурсы ретест делали даже 3 раза. К счастью, в реальности проблемы не существует как таковой, а неудачные экземпляры с посредственным бустом обусловлены бинингом или некорректной маркировкой успешных ядер. На моем экземпляре Ryzen 7 3700Х в однопотоке не получилось преодолеть 4367 МГц. Призванный на помощь режим андервольта оказался странным, PB2 или PBO адекватно на него не реагировали, при снижении напряжения помимо освобождения запаса по пакету PPT и температуре не позволяли увеличить частоту ядер в нагрузке, иногда даже был получен отрицательный частотный эффект. Возможно, Clock Stretcher имеет довольно агрессивные настройки, дабы максимально сделать системы с новыми процессорами Zen 2 стрессоустойчивыми. Представленный режим PB2 как «просто накинь +200 МГц к стандартному бусту» оказался неработоспособным на Ryzen 7 3700Х, но превосходно себя проявил на процессоре Ryzen 5 3600, который получил стабильные 4,4 ГГц в нагрузках на несколько ядер.
Еще одним забавным моментом было переход процессорных ядер во время бездействия в режим CC6 (глубокий сон) с VID в 1,47 вольта, что не позволяло процессору в режиме простоя экономить электроэнергию и иметь холодную крышку. К счастью решение нашлось довольно быстро, банальным переключением плана питания в сбалансированный режим с минимальным состоянием процессора в 85%. В ближайшие дни нас ожидает фикс в виде новых чипсетных драйверов.
Не могу не отметить Ryzen Master, утилиту, которая способна была отправить в бутлуп или повесить систему при изменении некоторых настроек, связанных с SMT, выборочным отключением ядер или изменение FCLK. К счастью данные утилиты любой фирмы имеют схожий ряд проблем, потому старый добрый разгон через прошивку никто не отменяет. На благо он, к моему удивлению, не имел багов или проблем. Потому я могу рекомендовать Ryzen Master на данный момент только в качестве информационной утилиты.
И да, не забывайте чистить руками реестр от старых версий, дабы не было конфликтов ПО.
Последним странным моментом для меня оказался вентилятор чипсета на X570, который непонятно по какой причине находится ровно под видеокартой (в случае ASUS Crosshair VIII Hero) и все тепло с видеокарты, разумеется, попадет в него. То ли это толчок энтузиастам, чтобы пересели на видеокарты с водой, то ли для того чтобы продвинуть корпуса с вертикальным воздушным потоком, в общем это осталось вне моего понимания. Малютка PCH во всех тестах держался на грани 75–80 градусов, по мнению HWInfo, потому я был вынужден открыть корпус и навесить 140-ку, которая обдувала память и захватывала скользящим потоком усилительную пластину видеокарты, тем самым формируя поток прохладного воздуха для PCH. В таком режиме температура хаба не переваливали отметку в 60 градусов. Из глобального, наверно, все.
Хотел бы уделить еще пару строк обновленному контроллеру памяти. Более гибкое дифференцированное управление питанием SOC и VDDG, новый режим 2:1 для профессиональных оверклокеров, хотя и сейчас я смысла в нем не вижу, ибо режим 1:1 с разгоном ОЗУ до 3533–3733 МГц обойдет любые 4200–4600 МГц. Предел для режима 1:1 является программным, присутствует ограничение в 1900 МГц по FCLK/UCLK и 3800 МГц по частоте ОЗУ соответственно. Обойти предел с помощью BCLK, к сожалению, невозможно. Существенно снизился нижний рабочий порог procODT, который говорит об прекрасном разгоном потенциале, что собственно получилось подтвердить на практике. Новички и энтузиасты могут ликовать, контроллер памяти, получив независимость, стал менее капризным, а тренинг памяти стал более предсказуем. Систему настроить стало гораздо проще даже на платах с чипсетом 300 серии. Это безусловно подарок для пользователей всех сегментов АМ4-плат.
Удивительно, но за последние два года компания AMD смогла сделать целых два «тик-так». Во первых это был Zen, новая архитектура (которая дала 52% рост IPC относительно «фикусов») и новый 14-нм техпроцесс, а теперь опять, по сути, новая архитектура и новый техпроцесс. Разница IPC между Zen и Zen 2 составляет 29,4% в вычислениях как на целых числах, так и на числах с плавающей запятой. Частота базового буста выросла с 4,35 ГГц до 4,6 ГГц, а число ядер увеличилось вдвое благодаря многочиплетному дизайну. Новая ступень энергоэффективности и производительности на ватт не оставят равнодушным ни геймеров, ни любителей организовать дома маленький сервер с огромными возможностями в рабочих приложениях. Не могу не отметить колоссальную работу, которую компания AMD проделала по хардварной оптимизации процессоров и материнских плат для оперативной памяти, благодаря которой мы можем заполучить дополнительные десятки процентов fps в сфере гейминга. Платы на чипсетах X570 являются просто роллс-ройсами в своем классе: огромное кол-во фаз, которые крайне сложно прогреть, разгон ОЗУ и новый стандарт PCI-E Gen 4.0 , который в ближайшие год позволит поднять производительность всей отрасли на новую ступень.
На сегодня все, а в ближайшее время я поведаю о Ryzen 9 3900Х, ряде плат на чипсете X570 и андервольте. Также у меня есть желание расширить количество игр и тестов. Оставайтесь на связи!