
Прошло довольно много времени с первого анонса на «анонс анонса». Нас дразнили процессорами AMD следующего поколения уже более года. Новый чиплетный дизайн был провозглашен не побоюсь этого слова — прорывом в производительности и масштабируемости процессоростроения, особенно в связи с тем, что с каждым поколением, с каждой архитектурой становится все труднее создавать большой чип с высокими частотами на меньших технологических нормах.

Ожидается, что этот смелый шаг повлияет на отрасль в целом. Сегодня я постараюсь для вас выкатить долгожданный очередной гайд-обзор, в котором будет и сравнение всех архитектур Zen, и гайд по разгону разных поколений процессоров и, конечно же, что нам даст разгон ОЗУ в поколении Zen 2. Хочу предупредить сразу, что обзора «содержимого коробок» вы в этой статье не найдете.
Поехали.
Архитектура
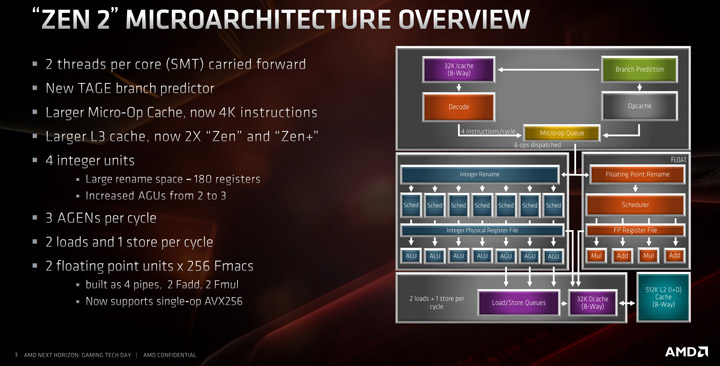
Начнем с того, что Zen 2 — это член семейства Zen, а не полноценно новая архитектура или новая парадигма обработки инструкций x86, и на верхнем уровне ядро выглядит примерно так же как и Zen/Zen+. Основные ключевые особенности архитектуры Zen 2 включают в себя новый предиктор ветвей L2 (известный как предиктор TAGE), удвоение микрооперационного кэша, удвоение кэша L3, увеличение целочисленных ресурсов, увеличение ресурсов загрузки/хранения и поддержку для одиночной операции AVX-256 (или AVX2) плюс отсутствие штрафов для AVX2.
CCD и CCX
Выше я уже упоминал о том, что компания AMD совершила прорыв в процессоростроении, применив многочиплетный дизайн. Тем не менее CCX-комплексы Zen 2 состоят из ядер аналогично предыдущим поколениям. В один блок CCX объединяется 4 ядра и 16 Мбайт общей кэш-памяти третьего уровня.
Пара CCX располагается на одном 7-нм кристалле и формирует процессорный чиплет, получивший аббревиатуру CCD (Core Complex Die). Помимо ядер и кэша, в CCD-чиплет входит также контроллер шины Infinity Fabric, посредством которого должно обеспечиваться соединение CCD с обязательным для любого Ryzen 3000 чиплетом ввода-вывода (IO), основанным на 12-нм кристалле, который мы могли пощупать ранее в Zen+.
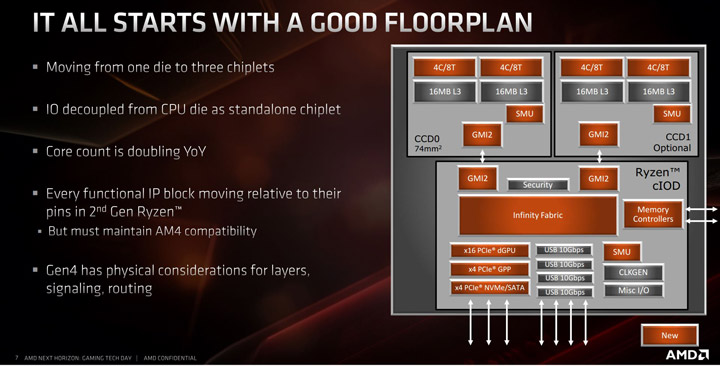
В чиплете ввода-вывода (I/O) процессоров поколения Zen 2 располагаются так называемые внеядерные компоненты, а также элементы северного моста и SOC. В нём, помимо всего прочего, находятся контроллер памяти и контроллер шины PCI Express 4.0. Также в I/O-чиплете реализованы и две шины Infinity Fabric, необходимые для соединения с CCD-чиплетами.
В зависимости от того, о каком процессоре семейства Ryzen 3000 идёт речь, он может состоять либо из двух, либо из трёх чиплетов.
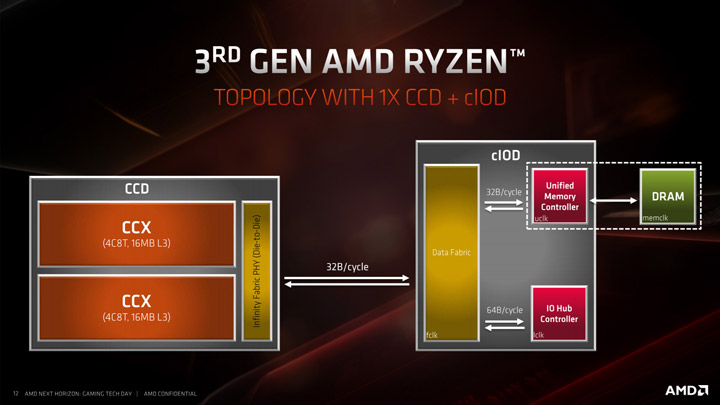
В процессорах с числом ядер восемь (потоков) и менее применяется только один CCD-чиплет и один I/O-чиплет.
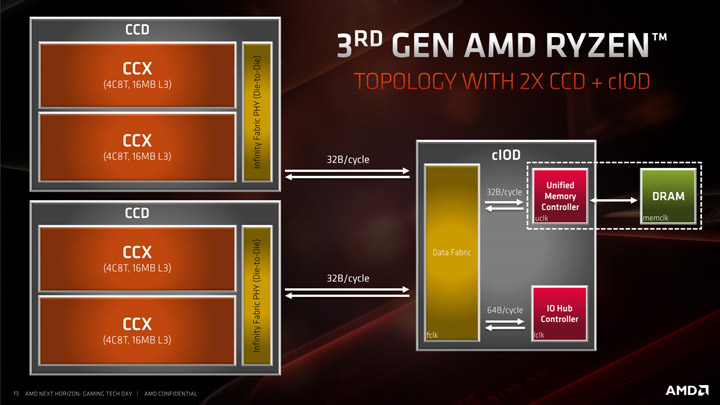
В процессорах с числом ядер более восьми CCD-чиплетов становится уже два. Однако нужно понимать, что процессор при этом всё равно остаётся единым целым. За счёт того, что в любых Ryzen 3000 контроллер памяти находится в I/O-чиплете и он всего один, любое из ядер может обращаться к любым её областям, никаких NUMA-конфигураций тут нет.
Безусловно чиплетная конструкция порождает определённые трудности для взаимодействия различных компонентов CPU и требует грамотной реализации специализированной шины, которой является Infinity Fabric. Впрочем, c этой задачей компании AMD удалось успешно справиться, и мы имеем возможность это пощупать на практике.
Без интересных особенностей, которые не попали на слайды, не обошлось, к примеру, шина Infinity Fabric на запись работает в режиме 16 байт за такт, а не 32 как нарисовано на слайдах. Увидеть просадку записи в ОЗУ можно в тестах AIDA и подобных. Расстраиваться в данном случае не имеет смысла, потому что скорость записи на самом деле не важна в большинстве задач. В любом случае, X86 имеет соотношение чтения / записи 2:1, и многие новые инструкции имеют даже соотношение 3:1 (a = a + b + c).
Zen 2 также имеет другой AGU, предназначенный для записи, который помогает быстрее найти правильный адрес для обратной записи, и теперь каждое ядро может записывать быстрее, чем раньше, несмотря на то, что общая пропускная способность записи между чиплетом и памятью уменьшается вдвое. Это также хорошо для игр, которые в некоторых случаях заполняют и генерируют больше записей, чем чтения.
Infinity Fabric
С переходом на Zen 2 мы также переходим ко второму поколению Infinity Fabric. Одним из основных обновлений IF2 является увеличение ширины шины с 256 до 512 бит, что означает двукратное увеличение пропускной способности и возможность пересылки по 32 байта за такт в каждом направлении. AMD пошла в первую очередь на это из-за появления в Ryzen 3000 поддержки PCI Express 4.0, а во вторых, чтоб увеличить производительность систем в ряде сценариев при условии недостаточной пропускной способности шины вызванной низкой тактовой частотой оперативной памяти (например пользователь купил дешевую память).

По данным AMD, общая эффективность IF2 увеличилась на 27%, что привело к снижению мощности на бит. В будущем нас ждут много чиплетные HEDT, которым, безусловно, новый интерфейс крайне необходим, но об этом мы уже с вами поговорим осенью.
Одной из особенностей IF2 является то, что контроллер памяти получил еще один режим, в котором его частота составляет половину от реальной частоты DRAM, то есть UCLK = 1/2 MEMCLK. Это было сделано для того, чтобы удовлетворить потребности энтузиастов в экстремальном разгоне и чтобы в случае неудачного кристалла IO пользователь все же смог разогнать ОЗУ без упора в IF2 и контроллер памяти. Тем не менее, на практике даже самый плохой экземпляр способен отлично работать на частотах UCLK 1800 МГц, а режим 2:1 остается эксклюзивом для энтзуиастов и оверклокеров.
Для Zen 2 синхронизации тактового сигнала доступны в вариантах 1:1 или 2:1, для поколений Zen 1 и Zen+ только 1:1.
Также я заметил, что на Reddit довольно много вопрос связанных с FCLK (это новая опция в UEFI), в частности как его настроить, чтоб система имела максимальную производительность. Идеальным вариантом для Zen 2 остается режим, когда FCLK = UCLK = MEMCLK, в этом случае отсутствуют «штрафы» синхронизации этих трех доменов.
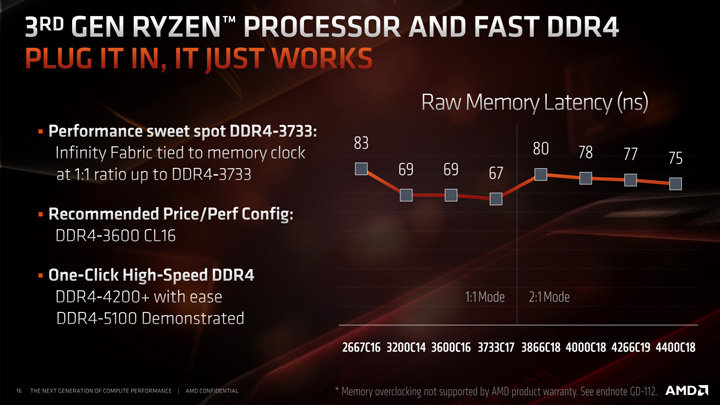
Касательно рекомендаций AMD все довольно просто, если нет желания заморачиваться с тюнингом таймингов, мы должны выбрать режим 1:1 (его, кстати, и выбирать не нужно, он включен по умолчанию), то есть как было и раньше, но если вы энтузиаст и знакомы с моим гайдом по разгону и тюнингу ОЗУ — вам ничего не мешает выжать максимум с любого режима.
Кэш
Серьезные изменения получила система кэша, самым заметным изменением является кэш команд L1, который был уменьшен с 64 до 32 КБ, но ассоциативность увеличилась с 4 до 8.
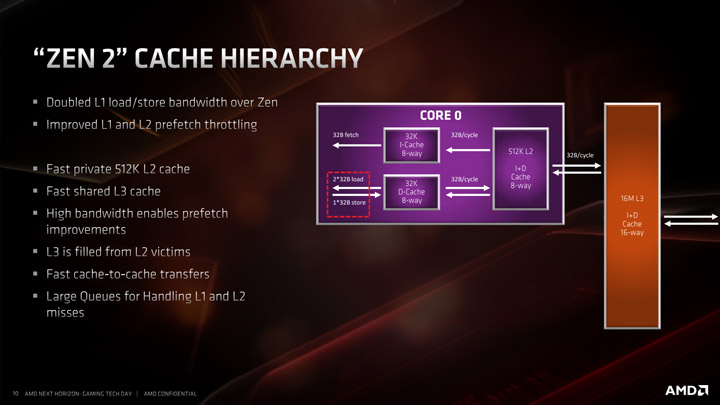
Это изменение позволило AMD увеличить размер микрооперационного кэша с 2 до 4 Кбайт и иметь более высокое использование L1-I. По мнению AMD это дало лучший баланс энергоэффективности и производительности в современных приложениях, которые не «блещут» оптимизацией и являются доминирующими на рынке ПО.
Кэш-память L1-D по-прежнему имеет 32 КБ с 8-канальной ассоциативностью, а кэш-память второго уровня 512 КБ с 8-канальной ассоциативностью. Кэш L3 теперь удвоился в размере на ядро комплекса (CCX) и составляет целых 16 MB, то есть один чиплет (CCD) в своем распоряжении имеет целых 32 MB L3. Латентность кэш-памяти для первых двух уровней не изменилась и составляет 4 такта для L1 и 12 тактов для L2, а вот L3 ожидает небольшой сюрприз, задержка увеличилась с 35 тактов до 40, что характерно для больших кэшей и не является чем-то ужасным.
Также AMD сообщила, что увеличила размер очередей, обрабатывающих пропуски L1 и L2, но не уточнила, насколько они велики.
Из «фишек» — теперь кэш-память может обслуживать по две 256-битных операции чтения и по одной 256-битной операции записи за такт на уровне L1, а также по одной 256-битной операции чтения и записи за такт на уровне L2, что вносит огромный вклад в скорость выполнения AVX.
Вычисления с двойной точностью
Основное улучшение производительности с плавающей запятой — полноценная поддержка AVX2. AMD увеличила ширину исполнительного блока со 128- до 256-битного, что позволяет выполнять расчеты AVX2 за один такт, а не разбивать вычисления на две инструкции и два цикла, следовательно, от Zen 2 можно ожидать двукратного увеличения скорости работы с AVX2-кодом.
Исполнительные устройства в FPU при этом остались нетронутыми. К тому же в Zen 2 AMD смогла добиться того, что обработка AVX2-инструкций может проводиться без какого-либо снижения тактовой частоты, как это происходит в процессорах Intel, при этом не стоит забывать, что частота может быть уменьшена в зависимости от требований к стоковым лимитам (температуры и напряжения), но это происходит автоматически и независимо от используемых инструкций. Должен сделать оговорку, что пользователь лимиты может изменить по желанию или вовсе отключить, тем самым переложив ответственность всю на систему охлаждения и свои плечи.

В модуле с плавающей запятой очереди принимают до четырех микроопераций за такт от модуля диспетчеризации, которые подают в файл физических регистров с 160 записями. Это перемещается в четыре исполнительных блока, которые могут быть снабжены 256-битными данными в механизме загрузки и хранения.
Были внесены другие изменения в модули FMA, помимо удвоения размера — AMD заявляет, что инженеры увеличили сырую производительность в распределении памяти, для физических симуляций (вычислений) и некоторых методов обработки звука.
Еще одним ключевым обновлением является уменьшение задержки умножения FP с 4 до 3 циклов. Это довольно значительное улучшение. Больше деталей об этом AMD обещала поведать на Hot Chips, которая состоится в августе.
Fetch/Prefetch
Основным заявленным улучшением является использование предиктора TAGE, хотя он используется только для выборок не из L1. AMD по-прежнему использует хешированный механизм предварительной выборки персептрона для выборок L1, который будет состоять из максимально возможного числа выборок, но предиктор ветвей TAGE L2 использует дополнительные теги, чтобы включить более длинную историю ветвей для лучшего прогнозирования. Это становится более важным для предварительных выборок L2 и выше, поскольку хешированный персептрон предпочтителен для коротких предварительных выборок в L1 на основе мощности.
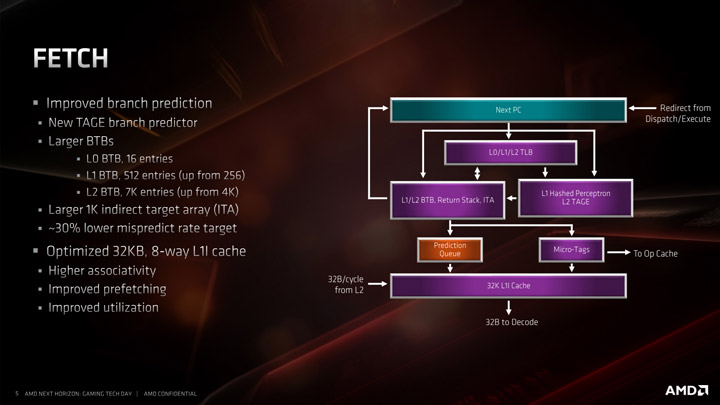
Во внешнем интерфейсе мы также получаем более крупные BTB, чтобы отслеживать ветви команд и запросы кэша. Размер L1 BTB увеличился в два раза с 256 до 512 записей, а L2 почти удвоился с 4K до 7K. BTB L0 остается на 16 записей, но косвенный целевой массив идет до 1K записей. В целом, эти изменения, по мнению AMD, позволяют на 30% снизить вероятность ошибочного прогнозирования, тем самым экономя электроэнергию.
Декодирование
Для этапа декодирования основным преимуществом является микрооперационный кэш. Удвоив размер с 2K записи до 4K записи, он будет содержать больше декодированных операций, чем раньше, что означает, что он должен многократно использоваться. Чтобы упростить это использование, AMD увеличила скорость отправки из кэша микроопераций в буферы до 8 объединенных инструкций.
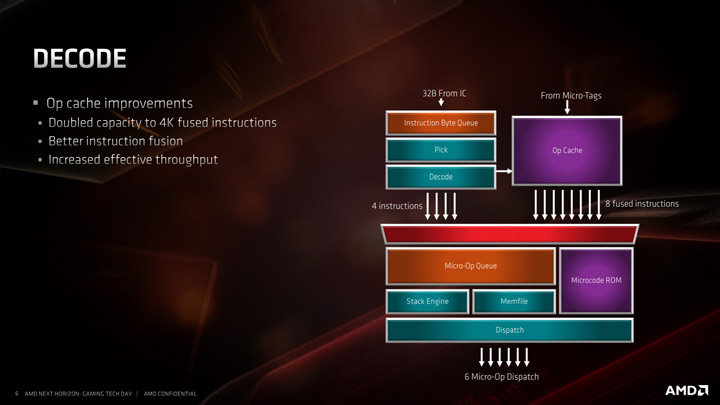
Декодеры в Zen 2 остаются прежними, у нас все еще есть доступ к четырем сложным декодерам, а декодированные инструкции кэшируются в кэш микроопераций и также отправляются в очередь микроопераций.
Выходя за пределы декодеров, очередь микроопераций и диспетчеризация могут вводить в планировщики шесть микроопераций за такт. Однако это немного несбалансированно, поскольку AMD имеет независимые планировщики целых чисел и операций с плавающей запятой: целочисленный планировщик может принимать шесть микроопераций за такт, тогда как планировщик с плавающей запятой может принимать только четыре. Однако отправка микрооперации может осуществляться обоим одновременно.
Исполнения инструкций
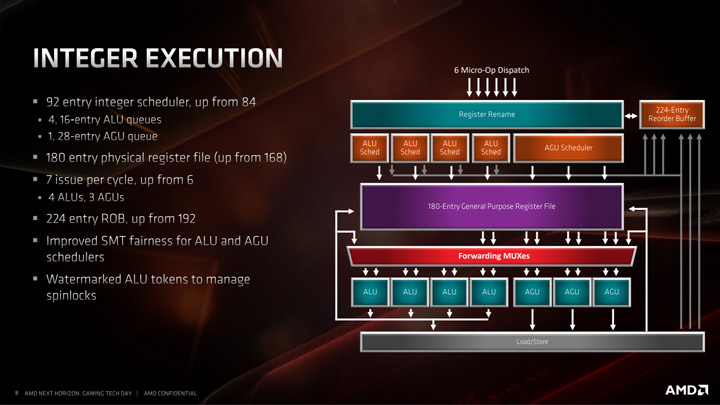
Планировщики целочисленных единиц могут принимать до шести микроопераций за такт, которые подаются в буфер переупорядочения с 224 записями (по сравнению с 192). Технически модуль Integer имеет семь исполнительных портов, состоящих из четырех ALU (арифметико-логических модулей) и трех AGU (блоков генерации адресов).
Планировщики состоят из четырех очередей ALU с 16 входами и тремя AGU с 28 входами. Блок AGU может подавать 3 микрооперации за такт в файл регистра. Также размер очереди AGU увеличился в результате моделирования распределений инструкций AMD в обычном программном обеспечении. Эти очереди поступают в регистровый файл общего назначения на 180 записей (вместо 168), но также отслеживают конкретные операции ALU для предотвращения возможных операций остановки.
Три AGU подают в модуль загрузки/хранения, который может поддерживать два 256-битных чтения и одну 256-битную запись за такт. Не все три AGU равны, AGU2 может управлять только хранилищами, тогда как AGU0 и AGU1 могут выполнять как загрузку, так и хранилища.
Загрузка и хранение
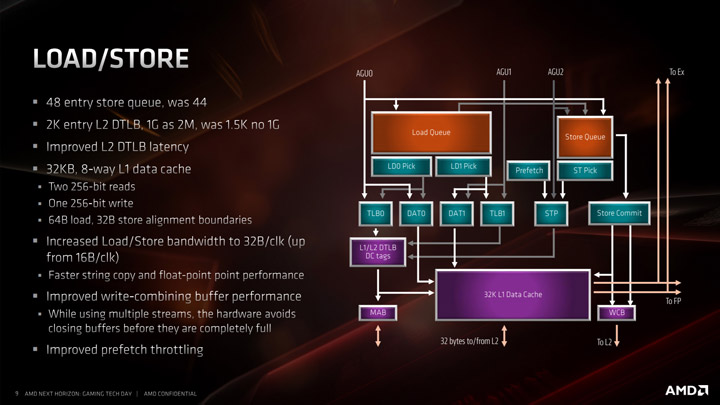
В Zen 2 была улучшена работа L2 TLB (буфера трансляции адресов). В первом поколении процессоров Zen размер этой таблицы составлял 1,5К, теперь же она увеличилась до 2К. L2 TLB теперь поддерживает страницы объёмом 1 Гбайт, чего в прошлых версиях микроархитектуры реализовано не было.
Еще одним ключевым показателем здесь является пропускная способность загрузки/хранения, поскольку ядро теперь может поддерживать 32 байта за такт, а не 16.
Также попутно была увеличена очередь хранения с 44 до 48 записей.
Контроль QoS пропускной способности кэша и памяти

В большинстве новых микроархитектур x86, существует гонка, чтобы повысить производительность с помощью новых инструкций, а также стремление к паритету между различными поставщиками в отношении того, какие инструкции поддерживаются. Касательно Zen 2, AMD не спешит «удовлетворять» Intel, добавляя в свое детище некоторые экзотические наборы инструкций. Компания добавляет новые, собственные инструкции в трех различных областях.
CLWB была замечена ранее в процессорах Intel в отношении энергонезависимой памяти. Эта инструкция позволяет программе помещать данные обратно в энергонезависимую память на тот случай, если система получит команду остановки и данные могут быть потеряны. Существуют и другие инструкции, связанные с защитой данных в энергонезависимых системах памяти, но AMD это не стала раскрывать. Возможно, компания стремится улучшить поддержку оборудования и структур энергонезависимой памяти в будущих разработках, особенно в своих процессорах EPYC и не хочет демонстрировать козыря раньше времени.
Вторая инструкция кэширования WBNOINVD относительно новая, она основывается на других подобных командах, таких как WBINVD и является экслюзивом для AMD-платформы. Эта команда предназначена для прогнозирования, когда в будущем могут понадобиться определенные части кэша, и очищает их, готовые для ускорения будущих вычислений. В случае, если необходимая строка кэша не готова, команда сброса будет обработана заблаговременно до необходимой операции, что увеличит задержку — запустив строку очистки кэша заранее, в то время как критическая для задержки инструкция все еще поступает, конвейер помогает ускорить его окончательное исполнение.
Третий набор инструкций QoS, фактически относится к тому, как назначаются приоритеты кэша и памяти.
Когда облачный ЦП разделяется на разные контейнеры или виртуальные машины для разных клиентов, уровень производительности не всегда одинаков, поскольку производительность может быть ограничена в зависимости от того, что другая виртуальная машина делает в системе. Это известно как проблема «шумного соседа»: если кто-то еще потребляет всю пропускную способность ядра к памяти или кэш-память L3, другой виртуальной машине в системе может быть очень трудно получить доступ к тому, что ей нужно. В результате этого шумного соседа другая виртуальная машина будет иметь очень переменную задержку при обработке своей рабочей нагрузки. В качестве альтернативы, если критически важная виртуальная машина находится в системе, а другая виртуальная машина продолжает запрашивать ресурсы, критическая виртуальная машина может в конечном итоге пропустить свои цели, поскольку у нее нет всех ресурсов, к которым ей требуется доступ.
Трудно иметь дело с шумными соседями, помимо обеспечения полного доступа к оборудованию в лице одного пользователя. Большинство облачных провайдеров даже не скажут вам, есть ли у вас соседи, и в случае миграции виртуальных машин в режиме реального времени эти соседи могут меняться очень часто, поэтому в любой момент гарантии стабильной производительности нет.
Как и в случае с реализацией Intel, когда серия виртуальных машин размещается в системе поверх гипервизора, гипервизор может контролировать объем пропускной способности памяти и кэш-памяти, к которым имеет доступ каждая виртуальная машина.
Корпорация Intel включает эту функцию только на своих масштабируемых процессорах Xeon, однако AMD включит и расширит линейку процессоров семейства Zen 2 для потребителей и корпоративных пользователей.
Безопасность
Другим аспектом Zen 2 является подход AMD к повышенным требованиям безопасности современных процессоров. Как уже сообщалось, значительное число недавних эксплойтов с побочными каналами не влияют на процессоры AMD, в первую очередь из-за того, как AMD управляет своими буферами TLB, которые всегда требовали дополнительных проверок безопасности, прежде чем большая часть этого стала проблемой. Тем не менее, для проблем, к которым уязвима AMD, она внедрила для них полную аппаратную платформу безопасности.

Изменение здесь коснулись для Speculative Store Bypass, известного как Spectre v4, — теперь новые процессоры имеют хардварную заплатку, которая будет работать в сочетании с ОС или диспетчерами виртуальной памяти, такими как гипервизоры. Компания не ожидает каких-либо изменений производительности от этих обновлений. Новые проблемы, такие как Foreshadow и Zombieload, не влияют на процессоры AMD.