
Строение CCD и иерархия кэшей
Иерархия кэшей имеет небольшие изменения.
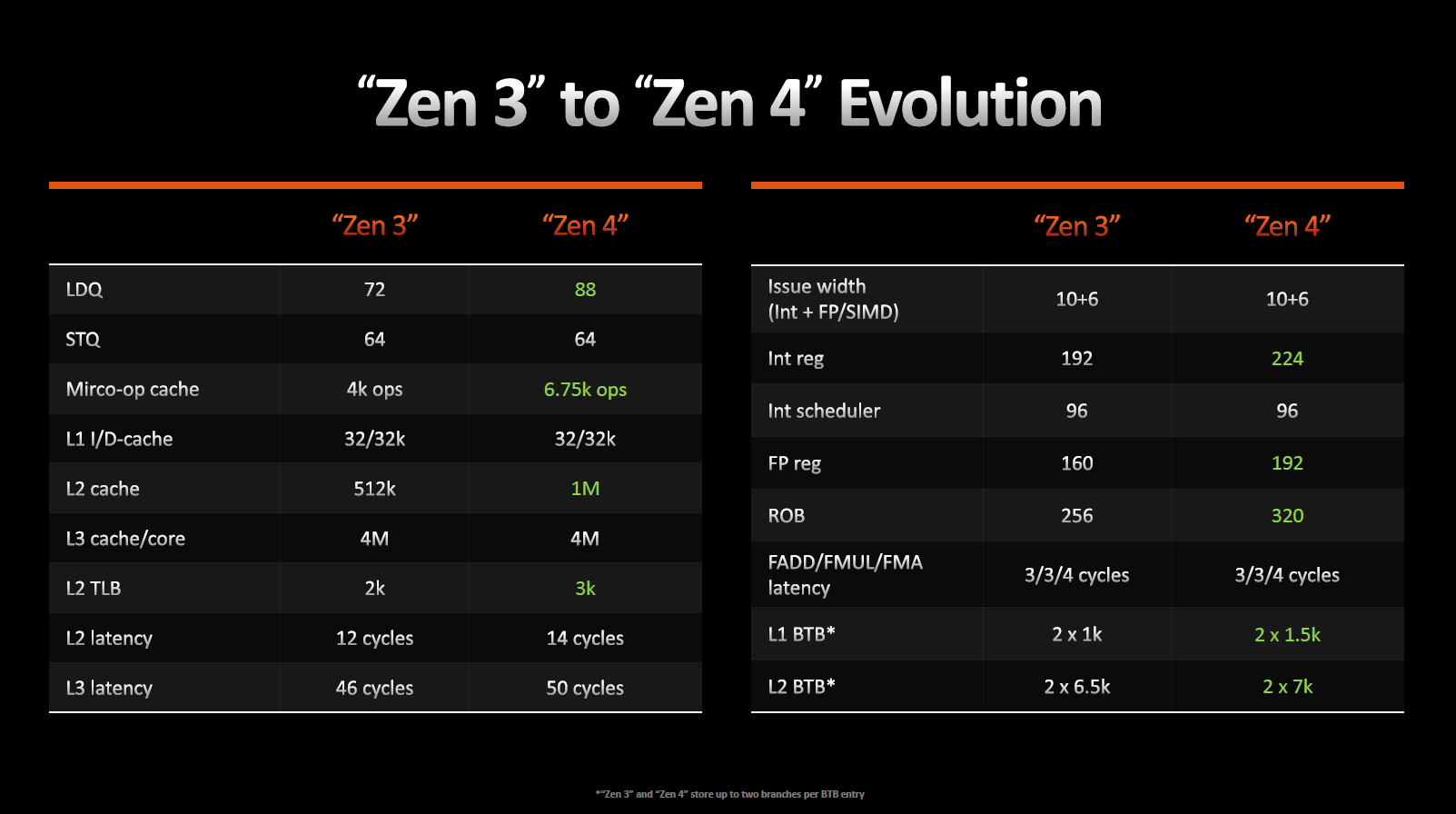
Кэш-память L1-I и L1-D по-прежнему имеет 32 Кбайт с 8-канальной ассоциативностью, а кэш-память второго уровня стала 1024 Кбайт с 8-канальной ассоциативностью, что в два раза больше, чем у предшественника. С точки зрения транзисторного бюджета несоизмеримое повышение затрат относительно полученного прироста IPC в 1%, но это оправдывает себя в высокоинтенсивных нагрузках, в частности в серверном сегменте.
Zen 4 поддерживает 64 существенных пропусков между L2 и L3 на ядро и 224 между L3 и оперативной памятью.
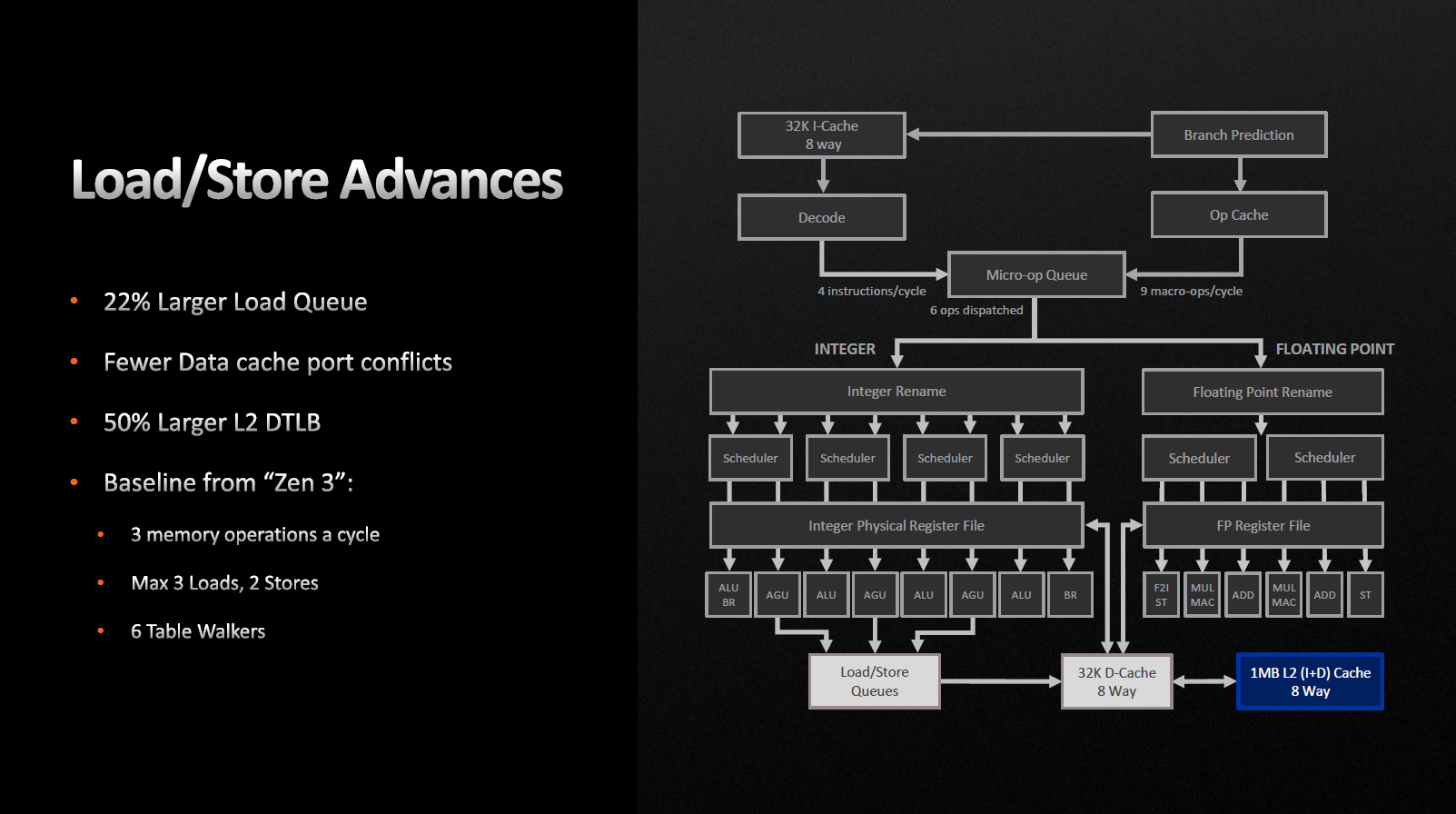
Кэш инструкций (L1-I) на цикл может обеспечивать 32-байтовую выборку, в то время как кэш данных (L1-D) допускает 3x 32-байтовых загрузки и 2х 32-байтовых сохранения за цикл. Очередь на сохранение не изменилась, но очередь на загрузку выросла с 72 до 88. Буфер трансляции адресов (TLB) L2 кэша также подрос на 50% и теперь составляет 3 Кбайт.
Стоит отметить, что подобные изменения должны серьезно повлиять на производительность в высокоинтенсивных задачах, которые приводят к большему количеству загрузок, чем сохранений.
Доступ близлежащих ядер к кэшу L3 осуществляется без использования Infinity Fabric, тут изменений нет. Задержка L3-кэша увеличилась, с 46 до 50 тактов. Основная причина этого явления все так же является объём монолитной структуры и возросшие тактовые частоты L3. Механизм заполнения кэша третьего уровня — виктимный, то есть на него не распространяется предварительная выборка, данные просто вытесняются в него из L2. Таким образом, L3-кеш оказывается преимущественно эксклюзивным.
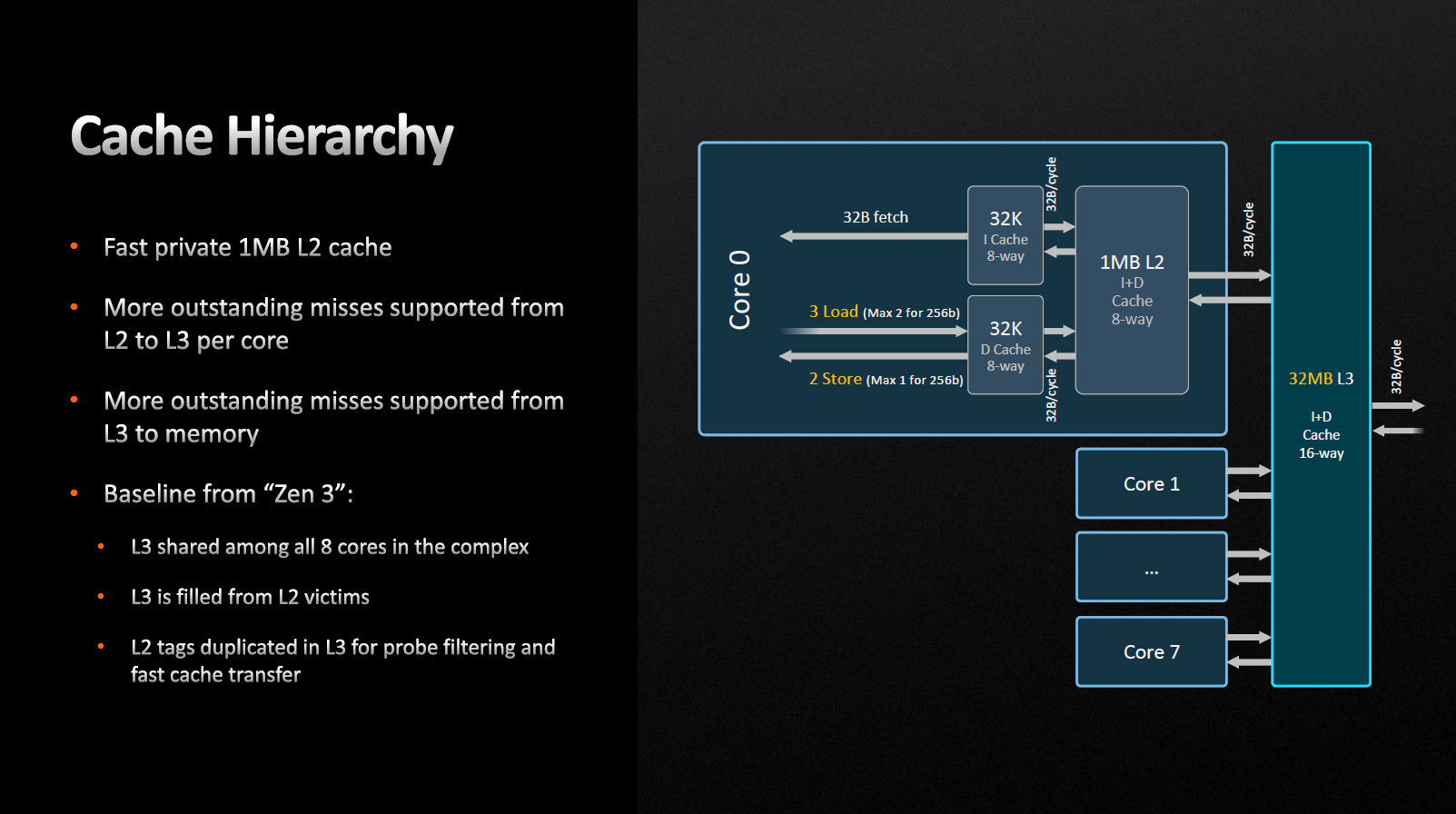
Компания AMD заявляет, что количество промахов кэшей L2 к L3 и L3 к оперативной памяти возросло. То есть если результат обрабатываемого запроса отсутствует в кэше, и чтобы его получить необходимо обращаться к внешней памяти. При получении ответа мы можем сохранить новое значение в кэш, вытеснив(удалив) некоторое старое, как результат — увеличение быстродействия.
Исполнительный блок и предсказатель ветвлений
Исполнительный блок почти не изменился. Все так же мы имеем четыре целочисленных унифицированных планировщика и два планировщика вещественных значений. Регистровый файл общего назначения подрос со 192 до 224, а регистровый файл для вещественных значений подрос со 160 до 192 записей.
«Ширина» конвейера осталась прежней, он позволяет выполнять за один цикл 10 целочисленных и 6 вещественных микроопераций.

Отмечается, что буферы по всему ядру стали более «глубокими», а очередь команд на выбывание возросла на 25%.
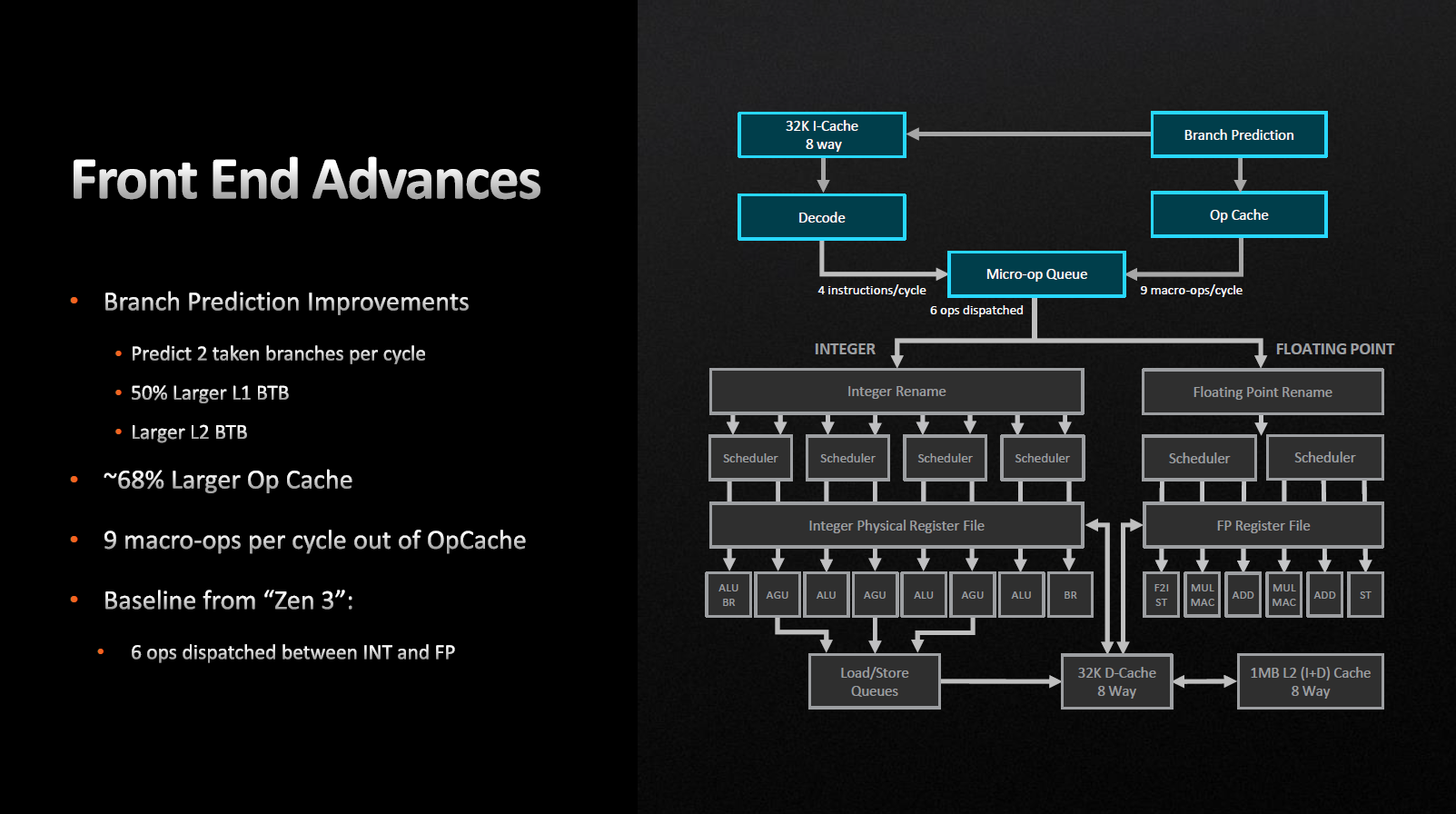
Архитектура Zen 4 позволяет предсказателю ветвлений за один цикл обрабатывать сразу две «ветки» вместо одной, как было ранее. Попутно были увеличены целевые буфера ветвления (BTB) для кэшей L1 и L2. Микрооперационный кэш был также увеличен с 4 до 6,75 Кбайт. Как итог мы можем наблюдать увеличение количества исходящих микроопераций из Op-кэша с восьми до девяти за один цикл.
Хочу отметить, что все вышеперечисленные изменения в первую очередь направлены на то, чтобы конвейер был максимально загружен и не возникало ситуаций с «простоем». Да, безусловно хотелось увидеть более «широкий» конвейер и более «жирный» декодер инструкций, но видимо это припасено для будущих архитектур.
AVX-512 и ускорение вычислений для нейросетей
Однажды «отец» семейства операционных систем Linux Линус Торвальдс критически высказался о перспективах расширения набора команд Intel AVX-512 (Advanced Vector Extensions). Основным посылом было то, что на тот момент Intel бесполезно палила транзисторный бюджет, создавая «магические» инструкции, пригодные только для тестов и сравнительного превосходства над конкурентами. Закончилось это тем, что Intel начала блокировать AVX-512 через вендоров материнских плат. Теперь с этим пришла компания AMD. Почему?
Как и все предшественники, AVX-512 предназначен ускорить работу приложений, использующих мультимедийные инструкции для работы определенных алгоритмов. Например, AVX и AVX2 используются для ускорения конвертации видео, эмуляторов игровых приставок, работы фото- и видеоредакторах, в частности для размытия фона и других операциях.

Заметного ускорения за счет новых инструкций уже сегодня можно добиться и при кодировании видео формата HEVC. Представители AMD говорят о том, что данные инструкции в первую очередь пригодятся для программного обеспечения, которое задействует глубокое обучение и искусственный интеллект, а также различные техники масштабирования изображений.
Вторая причина текущего прихода AVX-512 в настольный сегмент — это то, что серверная архитектура является родителем настольных процессоров. Именно в серверной архитектуре AVX-512 достаточно эффективно используется для научных расчетов, моделирования и других высокоинтенсивных задачах. По сути, то, что мы имеем, это приятный бонус, на который делается акцент.
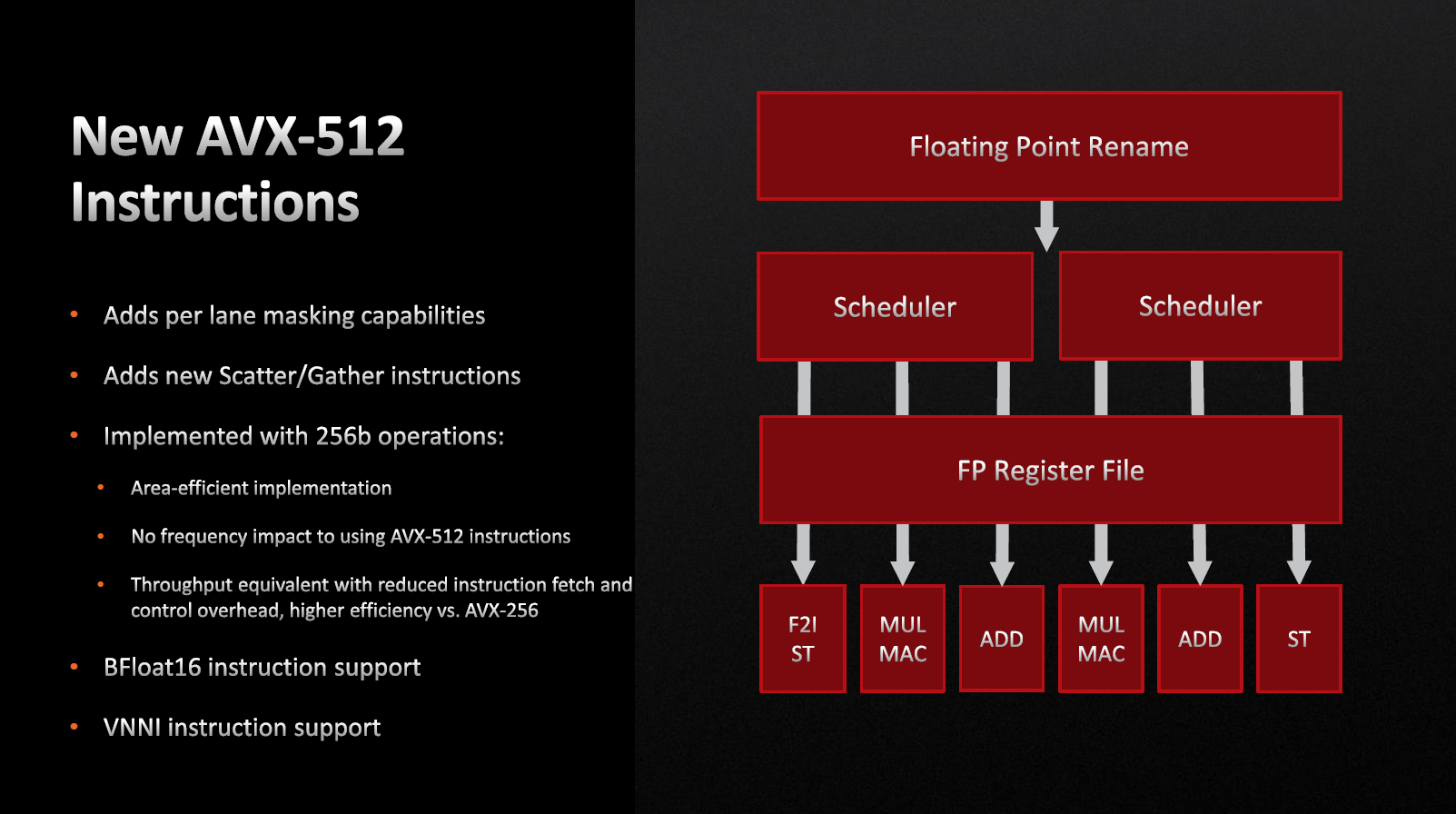
Нужно отдать должное, штрафов выполнения AVX-512 нет, а частотный предел ограничен лишь допусками по току и температуре.