Сложность и масштаб современных моделей ИИ постоянно растут, что ведет к росту требований к вычислительным системам и ресурсам памяти. Исследователи Google представили специальный метод векторного квантования TurboQuant, который способен повысить эффективность ИИ и уменьшить использование памяти, что может быть важным решением в условиях современного дефицита памяти.

Векторы — основной метод, с помощью которого модели ИИ обрабатывают информацию. Небольшие векторы описывают простые атрибуты, а многомерные векторы отражают сложную информацию, например, особенности изображения, значение слова или свойства набора данных. Многомерные векторы невероятно мощны, но потребляют огромные объемы памяти, что приводит к узким местам в кэше «ключ-значение» (key-value cache), где хранятся данные для быстрого доступа, чтобы система не искала их в громоздкой базе данных. Векторное квантование предлагает сжатие данных многомерных векторов для быстрого векторного поиска и ускорение работы с кэшем «ключ-значение». Метод TurboQuant предлагает эффективный алгоритм сжатия векторных данных PolarQuant для уменьшения модели ИИ с сохранением точности и устранением скрытых ошибок. PolarQuant осуществляет преобразование данных в меньшие наборы дискретных данных, а алгоритм QJL использует математические методы для коррекции ошибок. PolarQuant преобразует вектор из стандартной системы координат в полярные координаты, используя декартову систему координат. В качестве наглядного примера приводят такое сравнение: это сопоставимо в тем, как заменить фразу «пройти 3 блока на восток, 4 блока на север» описанием «пройти 5 блоков под углом 37 градусов», когда нужно два параметра (радиус и угол) для верного направления движения.
Исследователи провели тщательную оценку всех трех алгоритмов на тестах с длинным контекстом, включая LongBench, Needle In A Haystack, ZeroSCROLLS, RULER и L‑Eval с применением открытых LLM Gemma и Mistral. Экспериментальные данные показывают, что TurboQuant достигает оптимальной производительности при уменьшении использования памяти key-value cache.
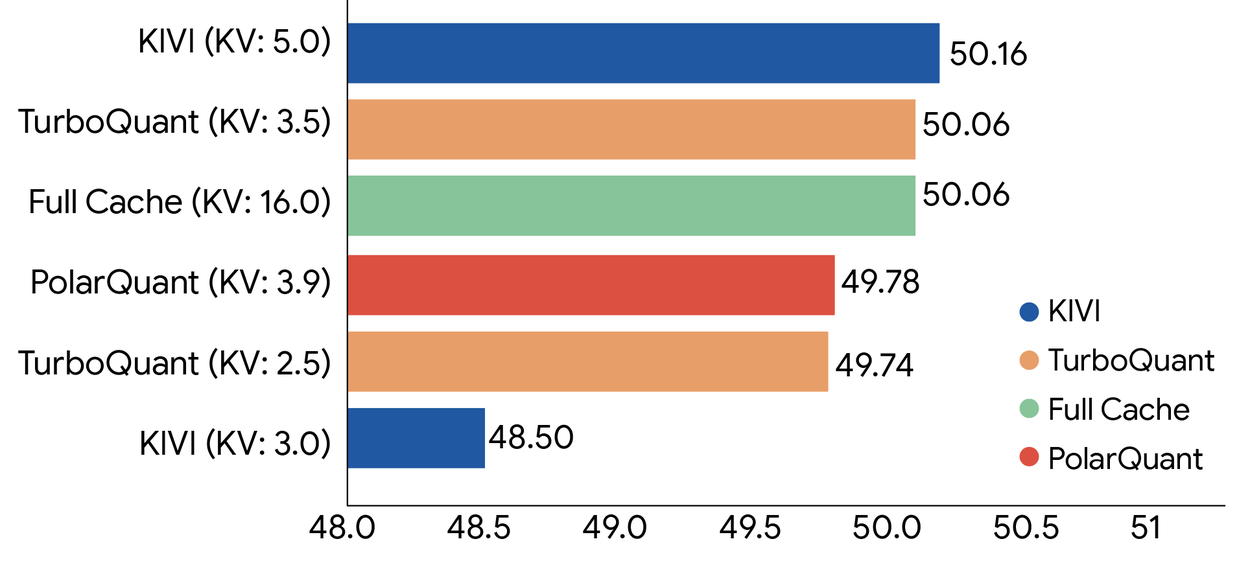
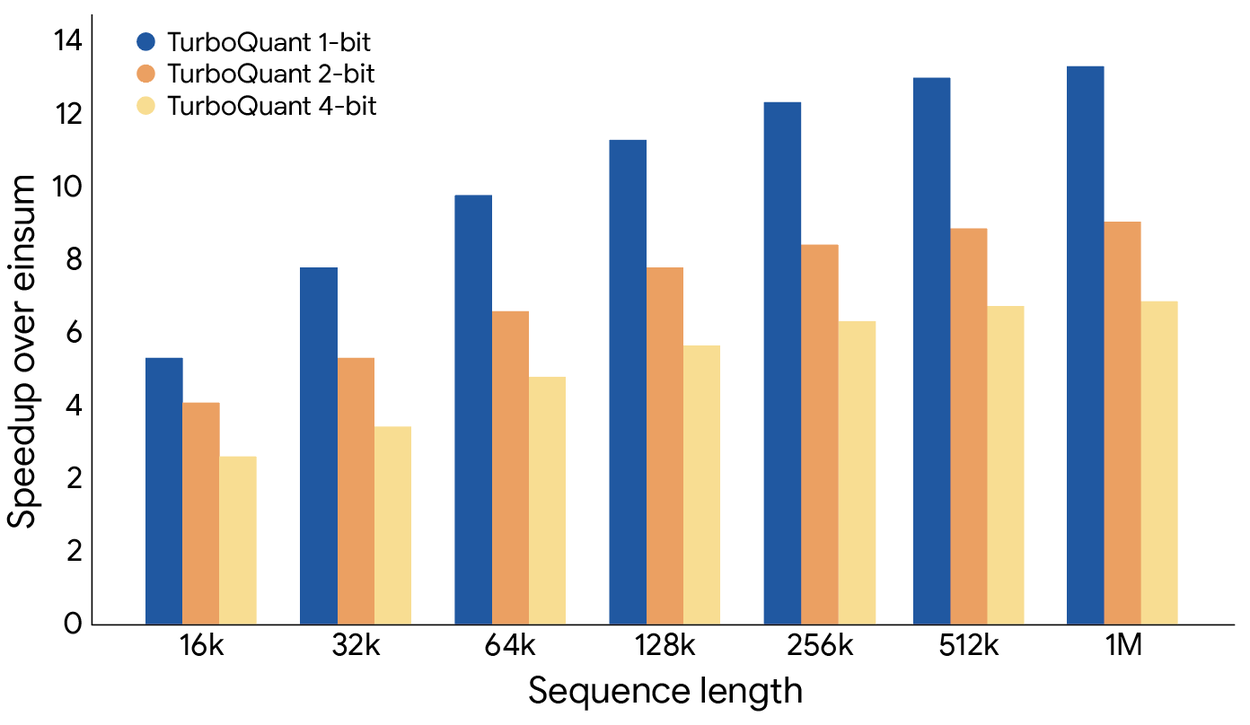
Метод связан с небольшими дополнительными вычислительными расходами, но обеспечивает значительный рост общей эффективности ИИ без ущерба для общей точности модели. В определенных специфических операциях 4‑битный метод TurboQuant обеспечивает 8‑кратное увеличение производительности по сравнению с 32-битными неквантованными данными на графических ускорителях H100.
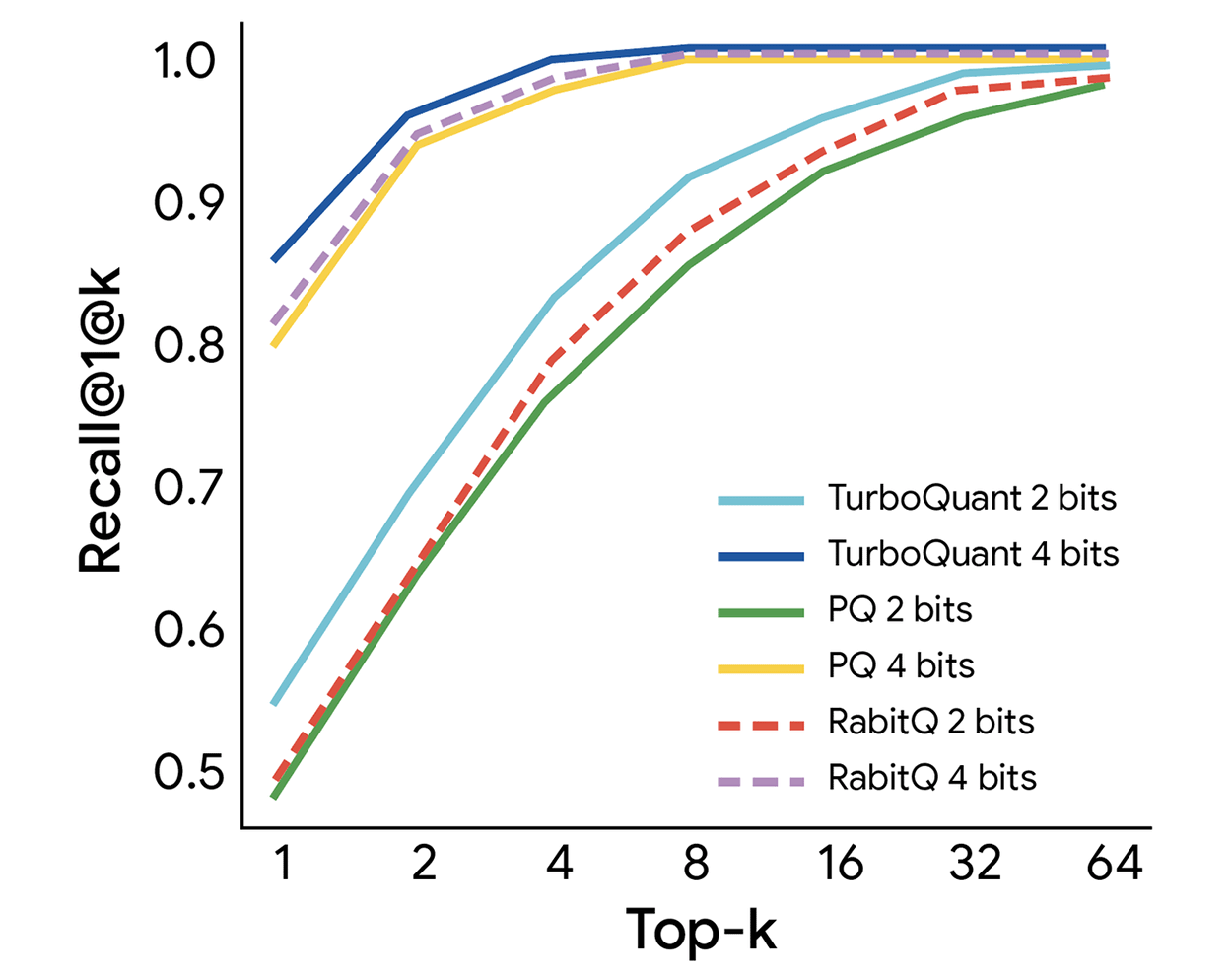
Также новый метод обеспечивает серьезный рост производительности в задачах векторного поиска.