
Видеокарта является неотъемлемой частью сегодняшнего компьютера, и трудно представить, что было время, когда без нее можно было спокойно обойтись. С тех пор прошло довольно много времени, и сейчас "видеокарта" приближается к некому рубежу, за которым - неизвестность. В статье мы постараемся вкратце проследить эволюцию видеокарты. Сразу отмечу: читать придется много, даже очень много, и при этом без некоторого умственного напряжения не обойтись, так что если это вас не смущает, и вы жаждете новых знаний, можете спокойно приступать к чтению. Особенно рекомендовано тем, кто в детстве любил разбирать игрушки - затем чтобы глянуть, что же там внутри.
Поначалу я намеревался дать подробное описание всех перипетий, связанных с видеокартами, но когда стало понятно, что по теме можно писать чуть не вечно, было принято решение "взять в руки ножницы и скотч и немного поработать". Но девиз остался прежним: "все что вы хотели знать, но боялись спросить".
Вчера
Для начала мы окунемся в историю и заодно освежим в памяти теорию, термины и определения.
Для того чтобы создать любой трехмерный объект (из совокупного числа которых мы получаем трехмерную сцену), нам нужно задать ему вершины, определяющие ключевые точки, и полигоны, которые образованы линиями, соединяющими вершины. (Как известно, графические ускорители работают с полигонной графикой, а это означает, что любой объект состоит из набора плоских многоугольников. Последние, в свою очередь, практически всегда разбиваются на простейшие треугольники. С такими фигурами очень удобно и, главное, просто работать. К тому же для всех алгоритмов закраски изображения нужно, чтобы полигоны были плоскими, т.е. их вершины должны лежать в одной плоскости - а треугольники таковы всегда по определению.) Т.е. формируем "геометрию" объекта. Затем накладываем по специальным алгоритмам цвет на наши полигоны. Как правило, делаем мы это с использованием заранее нарисованных плоских изображений - текстур (этот процесс называется закраской).
С созданием "геометрии" объекта (и сцены в целом) может справиться центральный процессор (что и происходит), но когда дело доходит до закраски, средствами одного центрального процессора (CPU) нам не обойтись. Ведь "натягивание" текстур на полигоны - довольно трудоемкая задача (для жалких сотни треугольников приходится рассчитывать как минимум 7–8 миллионов точек в секунду, если мы хотим получить приемлемое число кадров в разрешении 1024ґ768). Если заставить CPU помимо расчета геометрии еще и текстурами заниматься, пожалуй, многовато для него будет. Но самое главное - текстуры зачастую являются очень большими изображениями и, в отличие от небольшого набора геометрической информации, в кэш-память процессора не помещаются, тем самым вынуждая его непрерывно обращаться к далеко не такой быстрой как кэш оперативной памяти. Таким образом, закраска становится бутылочным горлышком при отрисовке сцены, и именно для аппаратного ускорения соответствующих операций были созданы первые 3D-акселераторы.
Но даже когда мы создали объект и закрасили его, нужно озаботиться еще и освещением. Тут особая свистопляска, в которую мы пока соваться не будем - да поможет вам Гуро с его методом (Gouraud method - лег в основу ускорителей с фиксированным конвейером (Fixed Function Pipeline (FFP)): видеокарты поколения DirectX 7), позволяющим эффективно и быстро добиться хорошего результата. Конечно же, первые ускорители рассчитывать освещение не могли. Но это не говорит о том, что игры были убогие - нет, разработчики выкручивались как могли, создавая вполне реалистичные проекты. Даже с тенями. Движок игры сам заблаговременно рассчитывал освещенность объектов и создавал соответствующие текстуры освещения, т.е. ускоритель рисовал уже просчитанные блики света. Для статического освещения подход хороший, но динамика выглядела ужасно - не сравнить с современными играми, рассчитывающими освещение "на лету". Как следствие, из-за возросшей нагрузки на центральный процессор, 3D-ускорители впоследствии получили аппаратный блок геометрических вычислений - Hardware Transform & Lightning (T&L - трансформация и освещение). После этого освещенные объекты все же оставались плоскими, гладкими и не сильно-то реалистичные, но и против этой напасти быстро нашли решение. Модифицировав алгоритм расчета цвета точки, мы можем, не усложняя геометрическую модель, радикально улучшить ее внешний вид. Такая техника получила название bump mapping (впервые появилось у Matrox (Environment Bump Mapping), а затем и у NVIDIA (DOT3). Конечно, bump mapping - не панацея от всех бед, для улучшения картинки применяется еще куча специальных техник и методов, например метод Фонга или его улучшенные варианты). Но ее реализация (и не только ее) требовала возможности программирования пиксельных конвейеров, т.е. шейдеров.
Шейдер - небольшая программа, позволяющая программировать графический ускоритель. На практике шейдер - короткая последовательность машинных кодов, которую разработчик, как правило, описывает на специальной разновидности ассемблера (правда, NVIDIA уже давно предлагает C-компилятор шейдеров - Cg, а в DirectX 9.0c Microsoft включила стандартный High-Level Shader Language (HLSL)). При этом шейдер позволяет творить настоящие чудеса с простыми моделями. Например, персонажи Doom 3 построены из небольшого числа полигонов, но при поддержке ускорителем шейдеров этого совершенно не ощущаешь. Существует несколько их версий (Shader Model), о которых мы еще успеем поговорить по ходу разбора типов шейдеров.
К счастью, шейдеры не являются основной темой статьи, так что пройдемся по ним поверхностно. И начнем мы с вершинных шейдеров (Vertex Shader), которые являются естественным развитием идей T&L. Так сложилось, что блок T&L ускоряет некоторые геометрические преобразования, и поэтому без особых махинаций мы можем поручить ему более широкий класс задач, "откусив" попутно у CPU часть функций, чтобы без его непосредственного участия шевелить траву и листья деревьев в сцене, детализировать на лету близкие объекты и огрублять дальние. Попутно разработчик получает полный контроль над механизмами T&L и может использовать вершинные шейдеры для расчета специфической геометрической информации, которую потом будут использовать пиксельные шейдеры.
Вершинный шейдер даже первой версии при относительно небольших объемах геометрических вычислений в процессе рендеринга может быть довольно сложной многострочной программой. Впрочем, первая версия вершинных шейдеров имела достаточно большие ограничения - не допускались никакие переходы (тем более не было условных переходов и, ясное дело, циклов), т.е. в ходу были прямолинейные и простые программы. Вторая версия шейдеров с некоторыми ограничениями допускает условные переходы и циклы. (В двух словах: условные переходы - это команда на изменение порядка выполнения программы в соответствии с результатом проверки некоторого условия. Очень распространенная, надо сказать, команда, и довольно проблематичная для вычислительного устройства (потеря времени). С циклами, думаю, все понятно.) А еще шейдера второго поколения позволяют организовывать функции, благодаря чему можно реализовать практически любой алгоритм. Третья версия стала еще более "демократичной" - она позволяет использовать в вычислениях текстуры и создавать "свои" свойства для вершин - таким образом, вершинный блок постепенно становится полноценным процессором с нешуточными возможностями.
Конечно, при этом стоит учитывать, что вершинные шейдеры, по сути, существуют для разгрузки центрального процессора, и их легко можно имитировать драйверами, "подсовывая" обычный CPU вместо соответствующего блока в видеокарте. А вот с пиксельными шейдерами такой номер не пройдет. Их просто нечем заменить. Отчасти поэтому я считаю их одним из главных и фундаментальных составляющих современного GPU. И говоря о шейдерах и их версиях, как правило, имеют в виду именно пиксельные шейдеры.
Пиксельный шейдер (Pixel Shader) обычно задает модель расчета освещения отдельно взятой точки изображения, производят выборку из текстур и/или математические операции над цветом и значением глубины. Пиксельные шейдеры могут автоматически генерировать текстуры (например, стилизация под дерево, или под воду, или блики на дне ручья, отбрасываемые рябью на его поверхности, причем текстуры, изменяющиеся во времени и не теряющие детализации даже при приближении к ним), а также производить с текстурами различные операции (например, мультитекстурирование - наложение нескольких слоев текстуры). Если говорить образно, пиксельный шейдер - это рельефные стены и естественное освещение (в том числе и динамическое и от многих источников света), рябь на воде, блики света на металлических и стеклянных поверхностях, очень реалистично выглядящие "пористые" поверхности и разнообразные спецэффекты. Т.е. это все то, чем мы восхищаемся в красивых и динамичных игрушках (тот же Doom 3 с его тенями и интерьерами, или вспомните воду в FarCry). Правда, пиксельный шейдер не столько вычисляет, сколько изменяет некий предварительно вычисленный стандартными способами цвет, поэтому даже если ваша видеокарта не поддерживает пиксельные шейдеры, то она все-таки сможет (не всегда, конечно) кое-что выдать на экран.
Но как вы понимаете, отработка пиксельных шейдеров - это колоссальная нагрузка на графический ускоритель (например, для хранения больших текстур нужно много памяти, а работа с ними может с легкостью озадачить даже самую производительную систему). Но овчинка стоит выделки! Реалистичность игрового мира - это вам не шутки, ради нее можно и побороться. Но благо нагрузка велика, ограничения на шейдерную программу здесь гораздо жестче, чем в случае вершинных шейдеров. Помимо арифметических манипуляций присутствуют и специализированные "текстурные", осуществляющие выборки цвета и арифметические вычисления с данными текстур. Что касается различий между версиями пиксельных шейдеров, они, аналогично вершинным шейдерам, отображают тот же эволюционный принцип: от полного ограничения к постепенному увеличению возможностей. Так, пиксельный шейдер первой версии поддерживал не больше восьми арифметических инструкций и не более четырех текстурных. Шейдеры версии 1.4 - те же восемь арифметических, но уже шесть текстурных инструкций, и без каких либо условных переходов. А вот во второй версии случилась маленькая революция - появилась поддержка чисел с плавающей точкой. Это позволило превысить стандартный диапазон 8-битного цвета, которого явно не хватало для отображения всего богатства оттенков. Третья версия шейдеров не принесла ничего особенного - включена поддержка условных переходов. Для освещения эта функция практически бесполезна. Но для "математических" операций как нельзя кстати, так как позволяла добиться некоторой оптимизации производительности шейдеров (например, можно не проводить вычислений над заведомо бесперспективными пикселами).
Это все хорошо, но до сих пор непонятно, как это все работает в результате. Постараемся в этом разобраться.
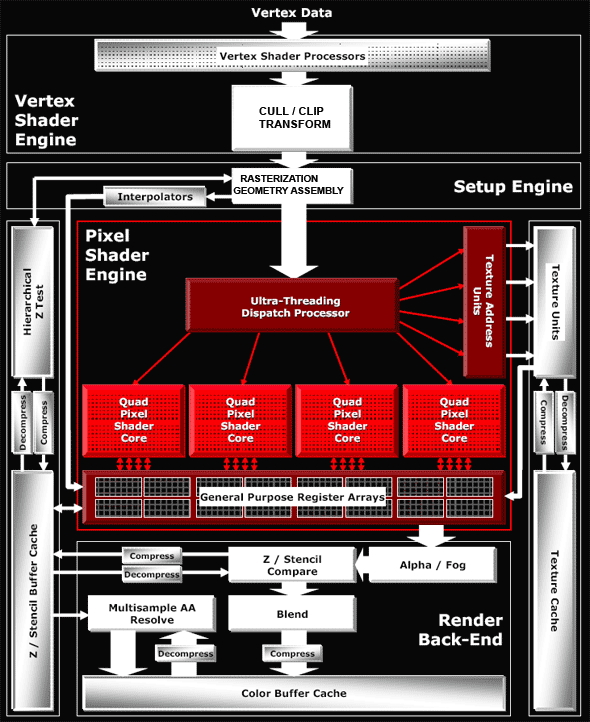
Есть такая интересная штука - графический конвейер, который реализует обработку графики конвейерным способом. И работает он следующим образом:
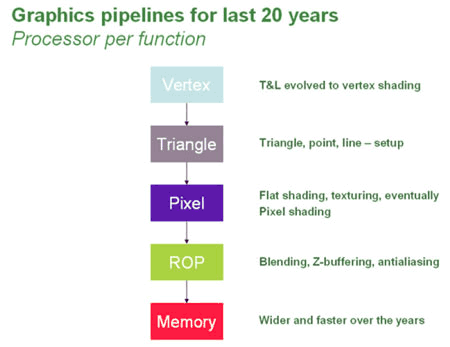
На первом этапе в графический процессор поступают данные от CPU об объекте, который надо построить. Эта информация попадает в блок вершинных процессоров и обрабатывается в нем (не путайте "блок вершинных процессоров" и "вершинные процессоры": блок - это совокупность вершинных процессоров, работающих по принципу конвейера. То же самое относится и к пиксельным процессорам). Вершинный конвейер (Vertex Pipeline) занимается расчетом геометрии сцены и определяет положение вершин, которые при соединении образуют каркасную модель трехмерного объекта, плюс осуществляет математические операции с вершинами (изменение параметров вершин и их освещения, этим занимается блок T&L). Все это происходит под управлением вершинных шейдеров. Тут по сути ничего сложного нет, про вершинные шейдеры мы уже успели достаточно поговорить.
После блока вершинных конвейеров данные поступают в следующий блок (Triangle), где происходит сборка (Setup) трехмерной модели в полигоны. После чего они попадают в блок пиксельных процессоров (Pixel Pipeline). Где и происходит операция закраски, плюс средствами пиксельных шейдеров происходит растеризация (процесс разбиения объекта на отдельные точки - пикселы) для каждого пиксела изображения, а также еще некоторые интересные вещи, о которых мы уже говорили (мультитекстурирование, попиксельное освещение, создание процедурных текстур, постобработка кадра и т.д.). Затем данные попадают в блок растровых операций ROP (Raster Operations Pipes), где с использованием буфера глубины (Z-буфера) определяются и отбрасываются те пикселы, которые не будут видны пользователю (в данном кадре). Также реализуется обеспечение полупрозрачности. В данном блоке происходят не менее интересные вещи: Antialiasing (т.е. сглаживание - удаление "лесенки" на изогнутых линиях путем добавления вокруг пикселов, создающих прямые линии из других пикселов, немного других оттенков), Blending (если кратко - плавный постепенный переход от одного цвета к другому, или преобразование одной геометрической формы в другую). Потом в ROP снова собираются все фрагменты (пикселы) в полигоны, и уже обработанная картинка передается в кадровый буфер (frame buffer). Данный буфер нужен для того, чтобы вывод и формирование картинки не зависели друг от друга. И так как монитору нужно непрерывно получать видеосигнал из данного буфера, применяется специальный преобразователь RAMDAC (RAM Digital-to-Analog Convertor - цифро-аналоговоговый преобразователь памяти), который непрерывно читает кадровый буфер и формирует сигнал, передаваемый через дополнительные схемы на выход видеокарты. Аналогично могут формироваться цифровые или телевизионные выходные сигналы. Причем, у современных GPU, как правило, несколько RAMDAC, что позволяет одновременно и независимо выводить видеосигналы на несколько мониторов одновременно.
Вышеописанный "классический" графический конвейер дает нам наглядное представление об основных этапах формирования изображения видеокартой. Конечно, графический конвейер я описал в сильном упрощении, там куда более сложные дела творятся, но, на мой взгляд, и того достаточно. Но самое главное то, что в GPU не один, а несколько конвейеров, работающих параллельно, и чем их больше, тем более производительным является GPU. Но стоит также учитывать то, что "графический конвейер" - понятие условное, так как в графическом процессоре используются несколько разных конвейеров (т.е. пиксельные или вершинные процессоры), которые выполняют различные функции. В этом смысле более правильно говорить о вершинных или пиксельных конвейерах, но не о конвейерах вообще. Хотя сложилось так, что под конвейером понимали пиксельный процессор, который подключен к своему блоку наложения текстур (TMU (Texture Module Unit) - текстурные блоки, о них мы успеем поговорить отдельно). Например, если у GPU шестнадцать пиксельных процессоров, каждый из которых подключен к своему блоку TMU, то принято говорить, что у GPU шестнадцать конвейеров. Но отождествлять число графических конвейеров с числом пиксельных процессоров все-таки не совсем корректно, поскольку конвейерная обработка подразумевает работу не только с пикселами, но и с вершинами, а значит, необходимо учитывать и количество вершинных процессоров. Так что число конвейеров будет корректной характеристикой GPU, только если их количество совпадает с числом пиксельных и вершинных процессоров и блоков TMU. И дело в том, что равное число различных конвейеров было бы самым производительным решением, если бы нагрузка на каждый из процессоров (будь-то вершинные или пиксельные) была одинакова. Но в реальной ситуации все совсем не так идиллично - нагрузка, как правило, неравномерна, и поэтому приходится искать оптимальный подход, комбинируя процессоры в зависимости от потребностей. Так как важно не переборщить с геометрическими характеристиками и в то же время не пренебречь красотами мультитекстурирования и роскошью сложных пиксельных шейдеров. И из-за этого имеем разное число пиксельных и вершинных процессоров, причем каждый производитель определяет свою пропорцию. Но решение проблемы золотой середины между количественным соотношением процессоров уже существует, о нем мы еще вспомним.
Я надеюсь, вы уже заметили, что мы вплотную подошли к архитектуре GPU, и конечно, на достигнутом мы останавливаться не будем. Причем, "глазеть под капот" мы начнем, так сказать, с "доунифицированной" архитектуры. Это затем, чтобы потом было ясно, что нового дает нам эта унифицированная архитектура и что изменилось. Но не беспокойтесь, закапываться глубоко мы не будем, и тем более опускаться в "дошейдерную" эпоху (хотя по иронии судьбы данные строки пишутся на компьютере, в котором стоит GeForce 2 MX400), а начнем с более свежих графических ускорителей.
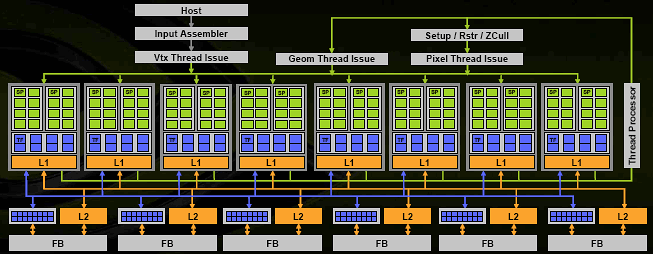
И первым у нас будет GPU от NVIDIA, так как на примере данного GPU можно легко разобраться в устройстве "классической" архитектуры, а заодно усвоить некоторые понятия и термины - просто чтобы не отвлекаться потом.
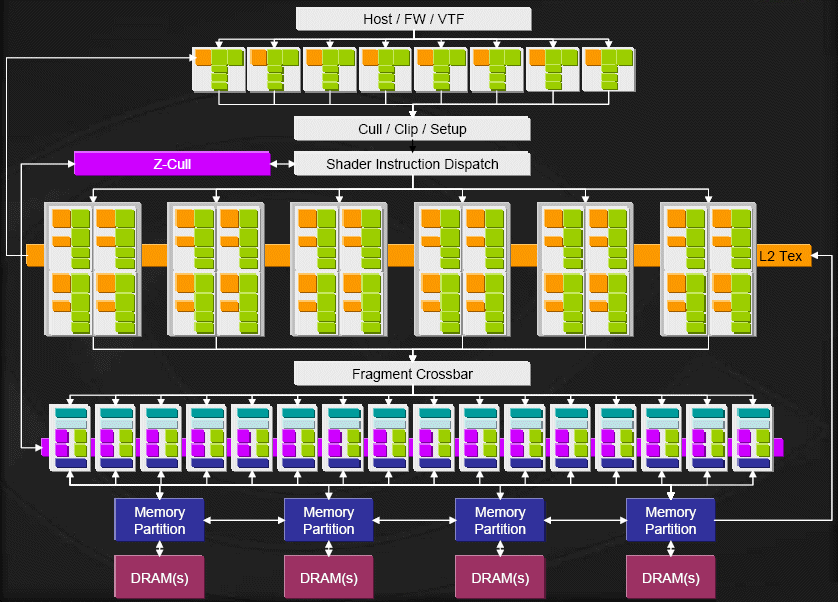
Итак, вышедший в 2005 г. графический чип G70 (GeForce 7800) стал дальнейшим эволюционным развитием чипов NV4x (ранее G70 значился как NV47, т.е. он относится к тому же поколению чипов, что и GeForce 6800). Имеет 24 пиксельных конвейера, по одному текстурному блоку на конвейер (т.е. 24 TMU), 8 вершинных конвейеров и 16 блоков растровых операций (ROP). Остальные характеристики можно посмотреть в сравнительной таблице. А теперь внимательно смотрим на схему и разбираемся.
| G70 (GeForce 7800) | R520 (Radeon X1800) | G71 (GeForce 7900) | R580 (Radeon X1900) | G80 (GeForce 8800) | R600 (Radeon HD2900) | |
| Пиксельных блоков (шт.) | 24 | 16 | 24 | 48 | 128 | 320 |
| Вершинных блоков (шт.) | 8 | 8 | 8 | 8 | 128 | 320 |
| Количество TMU (текст. за такт) | 24 | 16 | 24 | 16 | 8 (32) | 4 (16) |
| Количество ROP (пикс. за такт) | 16 | 16 | 16 | 16 | 6 (24) | 4 (16) |
| Частота ядро (МГц) | 430 | 625 | 650 | 650 | 575 | 742 |
| Частота вершинного блока/унифиц. проц. (МГц) | 470 | 700 | 1350 | |||
| Техпроцесс (нм) | 110 | 90 | 90 | 90 | 90 | 80 |
| Площадь кристалла (мм2) | 333 | 288 | 196 | 352 | 480 | 425 |
| Количество транзисторов (млн. шт.) | 302 | 305 | 279 | 384 | 681 | 700 |
| Объем памяти (Мб) | 256 | 256 | 512 | 512 | 768 | 512 |
| Частота памяти, номин/факт (МГц) | 600/1200 | 750/1500 | 800/1600 | 775/1550 | 900/1800 | 828/1660 |
| Ширина шины памяти (бит) | 256 | 256 | 256 | 256 | 384 | 512 |
| Тип памяти | GDDR3 | GDDR3 | GDDR3 | GDDR3 | GDDR3 | GDDR3 |
| Производительность (Гигафлопс) | 165 | 83 | 230 | 360 | 518 | 475 |
| Пропускную способность памяти (Гб/с) | 38,4 | 48 | 51,2 | 49,6 | 86,3 | 106 |
| Энергопотребление (Вт) | 110 | 100 | 70-80 | 120 | 145 | 215 |
Графический процессор состоит из нескольких пиксельных конвейеров, работающих параллельно, и чем больше конвейеров, тем более производителен GPU. За счет того, что мы рассовываем пикселы по разным конвейерам. Например, если мы имеем 24 пиксельных конвейера, то первый конвейер обрабатывает 1-й, затем 25-й, затем 49-й пиксел и т.д., а второй, соответственно – 2-й, 26-й и 50-й пиксел. Думаю, смысл понятен.
Уже давно принято объединять пиксельные процессоры в группы по четыре штуки (процессоры квадов), чтобы они обрабатывали не отдельные пикселы, а блоки 2ґ2 пиксела (квады). На представленной ниже илюстрации мы можем это увидеть – 6 блоков по 4 процессора в каждом.
В свою очередь, "сердцем" пиксельного процессора G70 являются два шейдерных блока (они же векторные ALU (Arithmetic & Logic Unit, базовое устройство, выполняющее основные вычислительные операции), способные исполнять 2 разные операции над 4 компонентами) и два mini ALU (простейшие скалярные ALU, параллельное исполнение простых операций (данные блоки, кстати, уже были реализованы во времена NV35, однако в NV40 использованы не были)).
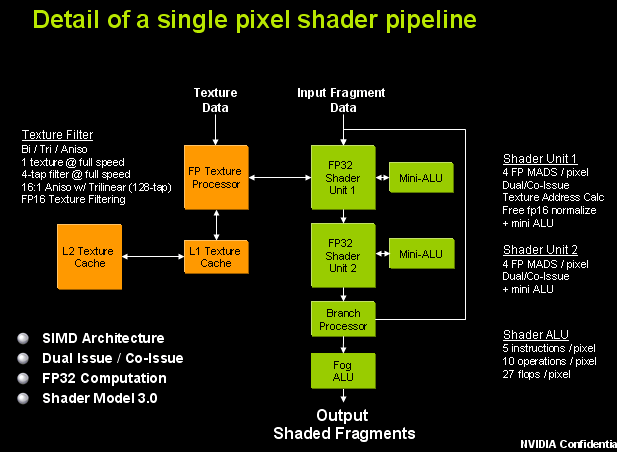
Благодаря этим "упрощенным" ALU (про то, что такое "скалярные" и "векторные", мы поговорим потом) можно увеличить математическую производительность процессора, а следовательно, и скорость исполнения пиксельных шейдеров. В нашем случае каждый пиксельный процессор может выполнять 8 инструкций типа MADD (Multiply Add, поэлементное умножение двух 4-компонентных векторов с прибавкой к полученному вектору третьего вектора - к этой штуке мы тоже еще вернемся) за такт, а суммарная производительность 24 процессоров на инструкциях такого типа достигает цифры в 165 гигафлопс (например, у предшественника - GeForce 6800 Ultra, производительность достигала всего 54 гигафлопс)...
Тут стоит отвлечься и сказать несколько слов о гигафлопах, плавающих запятых и про "математику" вообще (я залезу немного вперед, только для того чтобы не отвлекаться потом). Начнем с "плавающей запятой" (FP - Floating point, с английского это переводится как "плавающая точка", но разницы тут, как вы понимаете, нет), которая является формой представления дробных чисел.
Часто приходится обрабатывать очень большие числа (например, расстояние между звездами) или, наоборот, очень маленькие (размеры атомов или электронов). При таких вычислениях пришлось бы использовать числа с очень большой разрядностью. В то же время нам не нужно знать расстояние между звездами с точностью до миллиметра. Для вычислений с такими величинами числа с фиксированной запятой, которой точно прописано ее место, неэффективны. Поэтому для подобных максимальных и минимальных вычислений и применяются вычисления с плавающей запятой.
Одна деталь: на ранней стадии развития компьютеров операции с плавающей запятой не рассчитывались с помощью центрального процессора (из-за ряда технических причин), а всецело ложились на плечи специального сопроцессора - математического сопроцессора (специальный модуль операций с плавающей запятой (floating point unit (FPU)) - задача которого сводилась к выполнению широкого спектра математических операций над вещественными числами с плавающей запятой. Данный модуль был выполнен в виде отдельной микросхемы и имел специальное гнездо на материнской плате. Впоследствии он со всеми пожитками перекочевал в ядро CPU, где вместе с блоками целочисленных вычислений (ALU) продолжил развитие и выполнение своих функций. Это все так, к слову. Но этот момент мы запомним.
При этом существуют промышленные стандарты на представление числа с плавающей запятой в двоичной форме – IEEE 754, в котором определяются два вида чисел: с одинарной (float) и с двойной (double) точностью. Для записи числа в формате с плавающей запятой одинарной точности требуется тридцатидвухбитовое (FP32) слово, для записи чисел с двойной точностью - шестидесятичетырехбитовое (FP64). И если вычислительное устройство отвечает данному стандарту (т.е. может производить операции с FP32 или даже с FP64, что намного лучше), то его возможностей достаточно для выполнения "серьезных" научных (и других) вычислений, так как обеспечена высокая точность, надежность и правдивость результатов.
Но также важно, сколько операций с плавающей запятой производит вычислительное устройство за заданное время. Причем данный показатель является основным мерилом производительности компьютерных процессоров или других вычислительных устройств, и называется этот показатель FLOPS (Floating point Operations Per Second - операции с плавающей запятой в секунду) - эта величина как раз и показывает производительность вычислительного устройства (как правило, из-за высокого уровня производительности используются производные величины от FLOPS, образуемые путем использования стандартных приставок системы СИ (Мегафлоп, гигафлоп, терафлоп и т.д.). Как и большинство других показателей производительности, данная величина определяется с помощью тестовых программ, которые запускаются на подопытном устройстве (Широко распространена программа Linpack, первоначально библиотека на языке Фортран, содержавшая набор подпрограмм для решения систем линейных алгебраических уравнений, впоследствии на основе ее появился тест Linpack benchmark, с помощью которого определяется вычислительные способности не только "обычных" устройств, но и суперкомпьютеров TOP500 (данный тест, по сути, является основным тестом в рейтинге TOP500). Правда, существует уже более продвинутый тестовый пакет Lapack, более эффективный для современных компьютеров.)
Чем хорош флопс - при всей своей теоретичности он наиболее объективный, наиболее приближенный к реальным способностям устройства, в то время как остальные тесты являются чересчур субъективными и зависят от многих факторов. В основном они позволяют оценить испытуемую систему лишь в сравнении с рядом других аналогичных устройств. Правда, "флопс" не абсолютно точный показатель, есть много сложных нюансов (уже в самом термине "операция с плавающей запятой" много неопределенности, не говоря уже многих моментах, влияющих на результат и не связанных с производительностью вычислительного устройства - пропускная работа оперативной памяти, кэш-памяти, пропускная способность шины и т.д.). Впрочем, если опираться на результаты только одной программы (например, той же Linpack, но и тут есть одна проблема - все производители должны использовать одну и ту же программу, а такое не всегда происходит) и при этом брать средние значения, то можно получить более-менее правдивые результаты. Но есть проблемы другого рода - например, существуют системы, для которых, например, Linpack, не подходит из-за конструктивных особенностей. Например, суперкомпьютер MDGrape-3 имеет рекордную теоретическую производительность в 1 Петафлопс (для сравнения: первый номер TOP500, BlueGene/L, имеет только 280,6 Терафлопс), но он применим только для узкого круга задач, и поэтому очень сложно определить его "реальную" производительность (чтобы хоть приблизительно определить его место в TOP500), так как Linpack с ним не дружит.
Я понимаю, что данная информация кажется чересчур избыточной, но эти сведения нам очень сильно пригодятся потом, в следующих частях нашей статьи. Ну а сейчас вернемся к G70.
…Так как значительная часть вычислений пиксельного конвейера всегда связана с использованием одной или нескольких текстур и, соответственно, выборки из них, которая происходит не очень быстро, то для увеличения скорости выборки уже давно применяются специальные текстурные блоки (TMU), единственная задача которых - осуществлять выборку из текстур и их фильтрацию. В идеале - на определенное число конвейеров приходится равное число TMU, и за такт каждый из них способен произвести одну выборку. И если, например, TMU вдвое меньше чем конвейеров, а для проведения вычислений над точкой нужно две текстуры (что не такая и редкость в играх), то текстурные модули будут выдавать вдвое меньше данных, чем способны обработать конвейеры, и в итоге пикселы будут сходить с конвейера не каждый такт, а допустим, каждый второй такт. Поэтому число TMU является довольно важным параметром графического ядра. Но не стоит забывать и про вершинные процессоры, которые долгое время просто немного "шлифовали", не внося особых изменений - чтобы увеличить производительность данных конвейеров, обычно просто увеличивали их число. Правда, в G70 инженеры прибегли к необычному решению - ввели разделение частот, и теперь у пиксельных процессоров своя частота, а у вершинных своя. Что, конечно же, повлияло на увеличение производительности.
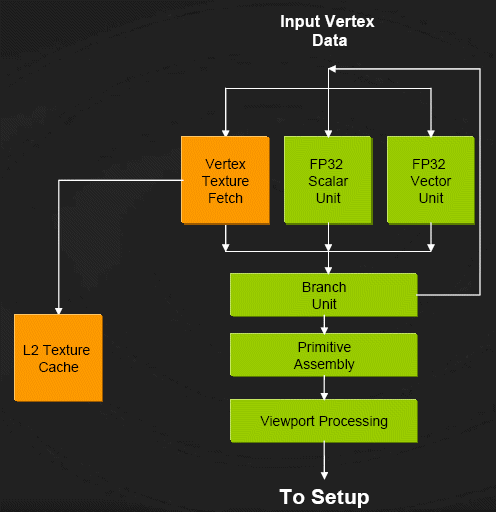
В свою очередь, вершинные процессоры также играют немаленькую роль в обработке изображения, так как работают с геометрией объекта, а затем отправляют свои данные на сборку (setup), после чего следует растеризация, обработка в пиксельных конвейерах, а затем все пикселы попадают в блок растровых операций (ROP - я надеюсь, вы помните, что он делает). При этом данный "блок" (имеется ввиду совокупность блоков ROP) перетерпел некоторые изменения. Если ранее в ускорителях NVIDIA было по одному блоку ROP на пиксельный конвейер, то в G70 их "всего" 16 (а точнее, они объединены в 4 блока по 4 ROP в каждом) на 24 пиксельных процессоров.
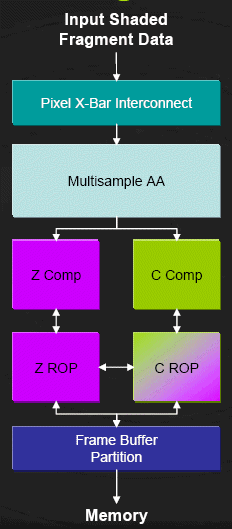
В первую очередь это сделано для экономии места на кристалле. Но это ни в коем случае не влечет падение производительности. Для оптимизации расхода транзисторов просто-напросто используются одни и те же ROP'овские ALU в разных целях в зависимости от задачи. При этом блоки ROP и пиксельные конвейера общаются между собой с помощью быстрого коммутатора, который перераспределяет рассчитанные квады между блоками. Также увеличение числа и сложности пиксельных конвейеров (которые стали тратить много сил на математические вычисления) привело к тому, что такое же число ROP будет не самым оптимальным решением, так как велик шанс того, что какие-то части ROP будут просто простаивать, и не последнею роль в этом будут играть малые возможности памяти (при имеющейся пропускной способности не факт, что за 1 такт удастся записать в кадровый буфер даже 16 полноценных пикселов - надо сказать, последняя по своим возможностям недалеко ушла от VRAM той же GeForce 6800 Ultra. Т.е. в GeForce 7800 просто было найдено оптимальное и более производительное соотношение, которое не уменьшало производительность, но и не увеличивало число транзисторов.
Стоит сказать несколько слов о видеопамяти. Как правило (исключением в основном является интегрированные решения) это несколько микросхем памяти, распаянных на плате ускорителя, и специальный высокопроизводительный контроллер памяти, интегрированный непосредственно в GPU. Причем специфика работы диктует свои определенные условия - требуется очень быстрая память. Для увеличения быстродействия ставятся несколько микросхем памяти, работающих независимо, благодаря чему за один такт будет считываться 64, 128, 256 и т.д. бит информации (эти числа называются шириной шины памяти). Ну и, разумеется, увеличивается частота, причем она намного больше, чем у обычной оперативной памяти. В первую очередь из-за того, что требования к надежности памяти здесь гораздо ниже: ведь кто заметит ошибку где-то в 13508-м пикселе текстуры?
Хотя любой современный акселератор может работать непосредственно с оперативной памятью, и такой подход в основном реализуется в интегрированных решениях. Конечно, о грандиозной производительности тут говорить не стоит (ведь часто даже вершинные процессоры "вырезаются" и реализуются посредствам драйверов, как, например, в Intel GMA 915), но ее вполне хватает для большинства задач (ваш покорный слуга играл в "Сталкера2 на Intel GMA 945, причем не чувствовал никакого дискомфорта - игра вела себя вполне нормально, хоть, конечно, не на максимальных настройках).
В свое время выход GeForce 7800 вывел NVIDIA в лидеры. Ответ конкурента в виде R520 задержался на долгих 4 месяца, впрочем, даже после появления Radeon X1800 (о нем читайте ниже) ситуация не сильно изменилась. А вот выход R580 с его доселе невиданными характеристиками автоматически вывел ATI на первой место. Но, конечно, NVIDIA не собиралась с этим мириться, и вскоре свет увидел новый чип - G71. Данный GPU по сути представляет собой "вылизанный до блеска" G70, о чем говорит практически идентичная архитектура. Правда, вылизан он был действительно идеально. Судите сами: с тем же количеством пиксельных и вершинных процессоров, с теми же 24 TMU и 16 ROP, что и у G70, причем их структура не перетерпела изменений, G71 имеет увеличенные частоты (характеристики смотрите в сравнительной таблице), при этом он уменьшил свое энергопотребление, тепловыделение и размеры. Конечно, это отчасти удалось достичь благодаря переходу на более тонкий 90-нм техпроцесс. Но как объяснить то, что новый GPU "потерял" транзисторы? Ведь по сравнению с G70 у G71 их на 25 миллионов меньше. Повторю - G71 имеет все то же самое, ничего не пропало. Есть только два более-менее разумных объяснения этого факта (как вы понимаете, NVIDIA не раскрыла секрет): первое предполагает героизм инженеров, которые провели колоссальную работу по оптимизации разных частей GPU (маловероятно, конечно, так как шкура, по сути, не стоит выделки - деньги огромные, а 25 млн. транзисторов как-то маловато для серьезных изменений. Но самое главное - зачем?); второй вариант - возможно, в G70 было зарезервировано какое-то число блоков (например, не 6 квадов, а 7, или не 8 вершинных процессоров, а, допустим, 9) для увеличения числа выхода годных чипов. То ли выход годных чипов на 90-нм процессе был достаточно высок, то ли NVIDIA смогла позволить себе больше брака, но в результате она просто удалила "запасные" транзисторы. Это, конечно, догадки, факт в том, что NVIDIA удалось на основе G70 сделать совершенно новый продукт с новой производительностью, что помогло ей сократить разрыв с ATI. Благодаря этому этапу стало возможным создать такие интересные продукты как GeForce 7900 GX2 и GeForce 7950 GX2, которые, по сути, являются уникальными - у ATI ничего подобного нет.
Думаю, уже хватит про NVIDIA, пришел черед и канадским американцам - ATI/AMD - показать свои "мускулы". Сразу скажу, что продолжать давний спор ATI vs. NVIDIA мы не будем. Так как они постоянно идут "ноздря в ноздрю". Разве что кто-то кого-то умудрился на определенном этапе обогнать - но только на определенном этапе. Дальше "отстающий" обязательно поднатужится и найдет чем ответить. Конечно, если у вас есть желание проводить сравнения, то пожалуйста, проводите, я же буду это делать только в тех случаях, когда без этого не обойтись, причем крайне ограниченными порциями.
Первым представителем ATI у нас будет чип R520, и не просто потому, что он является ответом G70, а в первую очередь из-за того, что в этом чипе ATI немного отступила от концепции "классической" архитектуры и при этом заложила основы для дальнейшего многолетнего развития, в том числе и в эпоху унифицированной архитектуры. Но, как говорится, все по порядку.
Когда-то очень давно ATI висела практически на волоске. Видеокарта, которая продвигалась в то время (а именно - Radeon 8500) как hi-end-решение по производительности дотягивала лишь до "начального уровня" конкурента. Продажи падали, компания терпела большие убытки. Положение спас вышедший R320 (и его модификации). С тех пор почти 3 года ATI просто занималась шлифовкой удачной линейки Radeon 9xxx, причем по старому и проверенному способу - увеличение числа конвейеров, оптимизация, иногда переход на новый техпроцесс и т.д.
В какой-то степени ситуация начала повторяться в 2005 г., когда NVIDIA выпустила GeForce 7800, а ATI чересчур долго тянула с ответом. Результат - провальный квартал, снижение продаж и $104 млн. убытков. Почему тянули? - ответов тут несколько: параллельная разработка R500 (графический чип Xbox 360, который, кстати, немного повлиял на архитектуру R520); накладки с переходом на новый 90-нм техпроцесс, но самое главное то, что это время требовалось для завершения работ над новой архитектурой, которую без больших угрызений совести можно назвать "революционной". За это время была проделана действительно колоссальная работа.
(Под "этим временем", конечно, имеются ввиду не те несколько месяцев задержки, а несколько лет, на протяжении которых велась разработка новой архитектуры. И если вы думаете, что у ATI, как и у NVIDIA или у любой другой компании, один инженерный отдел, который, например, после завершения работы над одним чипом приступает к новому, то вы глубоко ошибаетесь: у каждой компании, которая занимается проектировкой и разработкой микропроцессоров (особенно таких сложных как CPU и GPU), имеется несколько подразделений, работающих параллельно - одни разрабатывают "сегодняшний" чип, другие "завтрашний", а третьи проектируют процессор далекого будущего.)
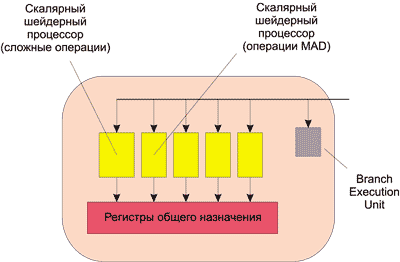
Во-первых, радикально переработана святая святых GPU - блок пиксельных процессоров. В прошлом он состоял из однотипных и простых пиксельных конвейеров, каждый из которых вычислял цвет отдельно взятого пиксела. Последний, однажды попав на один из конвейеров, обрабатывался прописанной ему программой (шейдером) и болтался внутри конвейера, пока не закончится вычисление его цвета. При этом почти все зависимые устройства (например, TMU) подключены непосредственно к исполнительным устройствам конвейера - схема очень проста и эффективна, но лишь до определенного момента. На смену прежней архитектуре был предложен своеобразный суперскалярный процессор, который, по сути, работает как один большой конвейер, имеющий возможность обрабатывать несколько пикселов одновременно.
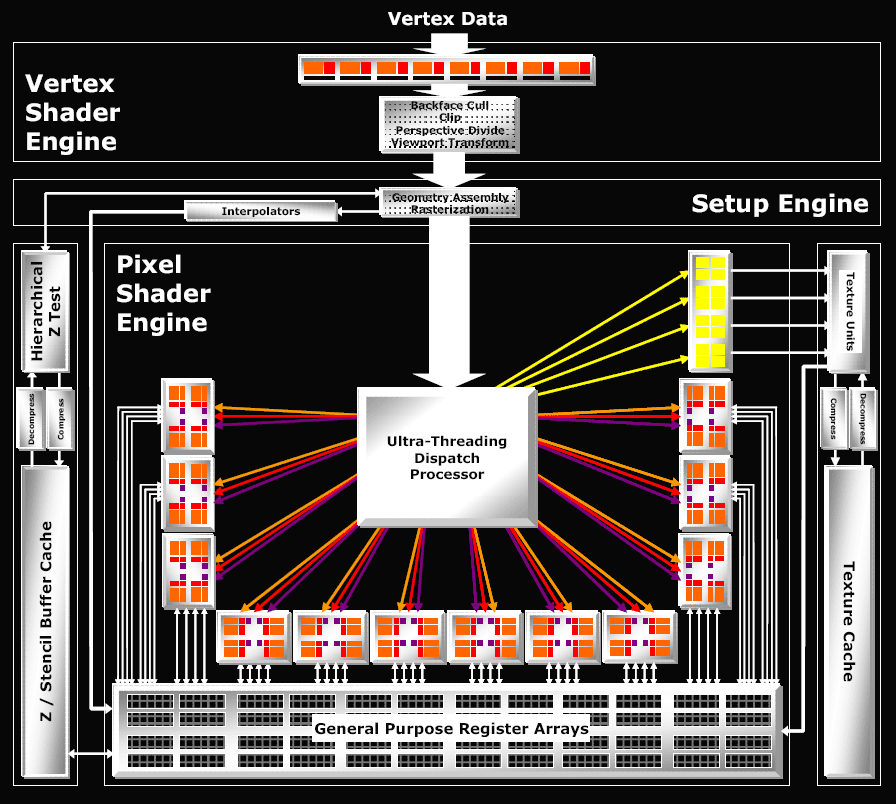
Вместо того чтобы сразу пихать пикселы в разные конвейеры, R520 накапливает их вместе с шейдерными инструкциями в специальном огромном планировщике - Ultra-Threading Dispatch Processor. В данном планировщике все квады хранятся в длинной очереди и по мере освобождения вычислительных ресурсов отправляются на обработку. Причем устройства, на которые планировщик отправляет данные, различны - TMU, ROP (которых, кстати, в этих GPU было по 16) или пиксельные процессоры. Это автоматически развязывает руки разработчикам - теперь можно спокойно варьировать соотношение пиксельных процессоров и текстурных модулей (так как они больше не подключены друг к другу. Тем более что раньше TMU своими зачастую медленными операциями могли вообще блокировать весь конвейер, так как пиксельным процессорам приходилось ждать от них ответа. И конечно, динамического переупорядочивания инструкций в GPU не предусмотрено (это ж вам не CPU), поэтому высвободить немного вычислительных мощностей под более нужные вещи не было возможности (те же пиксельные процессоры).
Благодаря данному чудо-планировщику ATI смогла наконец-то организовать поддержку Shader Model 2.0a и 3.0 (т.е. поддержку условных переходов, которую NVIDIA, к слову, реализовала еще в чипах NV4х), с которыми она до этого не сильно дружила. Ведь ради упрощения пиксельных конвейеров их схемы делались таким образом, чтобы они всякий раз настраивались на определенную операцию (сложение, вычитание, умножение), через которую пропускалось огромное количество пикселей. Схема была очень эффективна благодаря своей простоте, но для шейдеров с условными переходами (т.е. сложных программ) такой подход, мягко говоря, не предназначен. NVIDIA решает данную задачу так: в конвейере все пикселы обрабатываются "по кругу", но в решающий момент над некоторыми из них производят операцию, а некоторые просто игнорируют.
Шейдерами с условным переходом занимается специальный диспетчер ветвлений шейдера - GigaThread. Конечно, подход не идеальный, но самое главное - проблема решается. А вот ATI умудрилась реализовать поддержку Shader Model 3.0 практически бесплатно, без лишней свистопляски: все хранится в планировщике, то есть имеется возможность пускать только те квады, с которыми действительно нужно что-то делать сейчас, остальные же ожидают "в курилке". Таким образом, конвейер продолжает и дальше работать по старой схеме (смотрите выше), но при этом он не спотыкается на условных переходах. Можно, конечно, решить проблему совсем просто - с помощью специальных "предсказателей" (вообще, содержимое GPU можно назвать, с большой натяжкой, блоком предсказаний) - но это ж вам не CPU. Но что-то нас уже в такие дебри понесло…
R520 на первый взгляд немного смахивает на G70 своими пиксельными процессорами, но реального сходства мало, так как скалярные и векторные ALU работают отдельно.
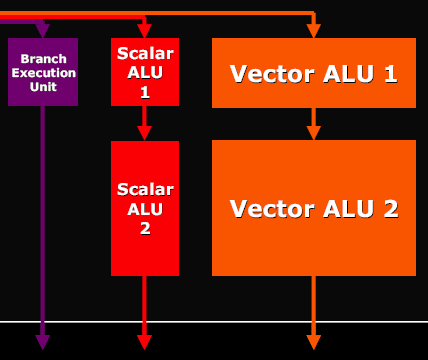
Вот только пиксельные процессоры G70 будут производительней (так как могут выполнять немного больше сложных и простых команд за такт), чем у R520, у которого их к тому же всего 16. Они дают скромную суммарную производительность в 83 гигафлопс (у G70 - 165). Тут сравнивать, конечно, тяжело, но заметим, что при сопоставимом числе транзисторов (смотрите таблицу) ATI смогла всунуть только 16 пиксельных процессоров. Это, по сути, плата за сложность архитектуры. Ведь чем сложнее устройство, тем оно и менее производительно, а самое главное, менее рентабельно. У ATI всегда с этим проблема - пытаясь догнать и перегнать конкурента с его неизменно простым и эффективным подходом, ей приходится "брать грубой силой" - идти на постоянные усложнения, серьезные переработки и инновации, которые часто выливаются в побочные эффекты - цена, тепловыделение и т.д. Ведь только благодаря сложности R520 ATI сумела догнать - но, к сожалению, не перегнать - G70. Впрочем, R520 оказалась хорошо масштабируемой архитектурой, позволив ATI практически сразу выпустить монстроподобный R580, который, к слову, если не принимать во внимание увеличенное число пиксельных процессоров (до 48), а также цены, тепловыделения, размеров, частот и немного большей производительности, существенно не отличается от R520.
На что NVIDIA ответила улучшенным G70, при этом оставив "все как есть", и спокойно догнала ATI. Но не перегнала - не считая 7950 GX2, на который ATI ответила выходом X1950 XTX, но до NVIDIA не дотянув. Как говорится, почувствуйте разницу в подходах - простым и сложным.
Хочется еще много чего сказать, но перейдем к следующей части нашей статьи.
Сегодня
Сегодня мы имеем немного другие архитектуры и несколько измененный графический конвейер. Связанно это с появлением последней версией API - DirectX 10, и новой, 4 версией шейдеров (Shader Model 4.0).
Основные цели, которые поставила перед собой Microsoft при разработке API DirectX 10 были таковы:
- Снизить зависимость от центрального процессора;
- Предоставить разработчикам унифицированный набор инструкций для программирования пиксельных и вершинных шейдеров;
- Увеличить функциональность пиксельных и вершинных шейдеров;
- Предоставить разработчикам возможность создавать новые геометрические эффекты непосредственно в шейдере;
- Дать возможность графическим процессорам управлять потоками данных внутри себя (с помощью Stream Output), увеличивая тем самым эффективность исполнения кода;
- Увеличить эффективность работы с текстурами, максимальное разрешение текстур, поддержать новые форматы HDR и произвести другие эволюционные изменения.
Все это было реализовано в полной мере, и результаты мы сможем увидеть в играх следующего поколения, вооружившись новыми графическими ускорителями, поддерживающими DirectX 10 и Shader Model 4.
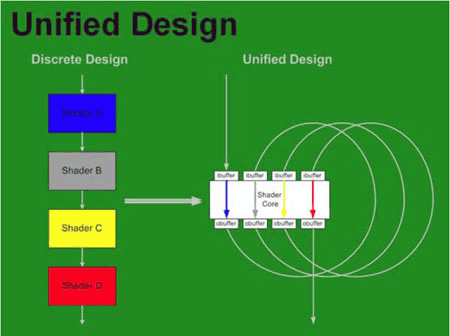
В четвертой версии шейдеров в первую очередь было принято решение отказаться от поддержки низкоуровневого ассемблерного языка программирования, теперь применяется только высокоуровневый язык, например HLSL 10 (High Level Shader Language). Было снято ограничение на количество инструкций в шейдерах и увеличено количество поддерживаемых шейдерами текстур, которые ими используются, плюс введена обязательная поддержка FP32. Все эти (и другие) изменения призваны открыть весь потенциал унифицированных шейдеров и максимально повысить быстродействие и производительность системы. Сам смысл унифицированных шейдеров мы рассмотрим на примере иллюстраций: при разделении на вершинные пиксельные процессоры мы часто можем столкнуться с ситуацией, когда одни работают на полную катушку, другие вполсилы.
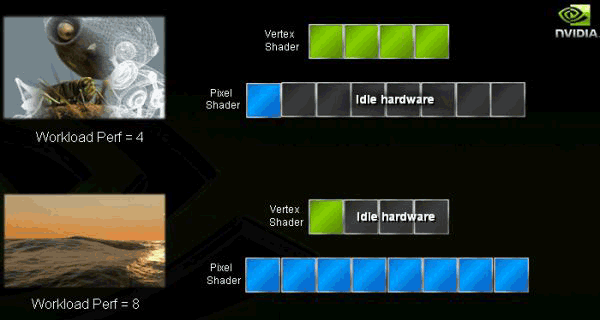
Теперь же, когда мы имеем набор унифицированных процессоров, мы можем распределять нагрузку в зависимости от ситуации, и тем самым повысить общую производительность всего GPU.
 >
>При этом к основным двум типам шейдеров (пиксельные и вершинные) был добавлен еще один - геометрический шейдер (Geometry Shader), умеющий самостоятельно добавлять новые вершины (а также точки, линии и треугольники), работать с ними и, по сути, рисовать новые примитивные фигуры, собирая их и делая с ними все что угодно (в рамках своих входных алгоритмов). Это все заставило немного изменить сам графический конвейер - смотрим на блок-схему и разбираемся, что изменилось:
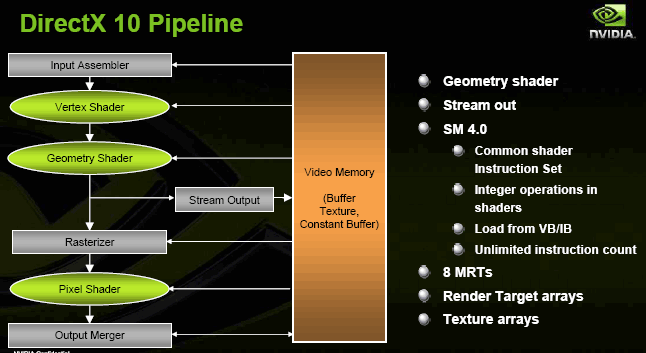
Первое изменение - блок Input Assembler (IA) помимо общения с центральным процессором получает вершинные данные из буфера вершин (Vertex buffer) или данные из буфера индексов (Index buffer, обеспечивает прирост производительности, так как позволяет избежать повторного просчета данных с тем же индексом). Данный блок может повторно вводить на конвейер данные, рассчитанные вершинными, пиксельными и геометрическими блоками, загруженные в память с помощью потокового вывода (Stream Output). Благодаря этому можно снова и снова вводить на конвейер одни и те же требуемые данные, не повторяя их расчет, что, конечно же, разгружает сам конвейер и увеличивает производительность. При этом потоковый вывод может также загружать данные из памяти непосредственно в геометрический блок и тем самым "отсекать" пиксельные и вершинные блоки, заставив работать конвейер (на определенном необходимом этапе) без них. Но основная задача Stream Output - снабжать геометрический блок нужной ему информацией. Все остальное осталось без больших изменений, но и вышеперечисленного хватает с головой, чтобы поднять производительность и вычислительные способности графического ускорителя на новый качественный уровень.
Вообще, все изменения, появившееся в новом графическом конвейере и новой версии шейдеров, тянут на целую отдельную историю, так что остановимся на этом и перейдем непосредственно к разбору новых архитектур "сегодняшнего" GPU. А первым графическим процессором нового поколения по праву считается G80 (GeForce 8800) от NVIDIA. Вот с него и начнем.
Как вы понимаете, изменение архитектуры графического конвейера повлекло за собой и изменение ядра GPU, теперь вместо отдельных пиксельных и вершинных блоков имеем один большой многофункциональный блок, а проще сказать, унифицированный.
У G80 128 унифицированных процессоров (они же скалярные ALU), собранных в 8 больших блоков — именно они, эти 8 блоков (16 ALU + 4 TMU), являются основными вычислительными единицами. В любой момент времени такой блок может заниматься своим делом - пиксельными, шейдерными или геометрическими операциями; напротив, ни один из 128 ALU независимо от остальных такого себе позволить не может.
В каждом из блоков содержится по 16 ALU, что в сумме дает наши 128 унифицированных процессоров, причем теперь они называются потоковыми процессорами (Stream Processors).

Почему потоковые? Все из-за возможности повторной обработки данных, выведенных одним процессором с помощью другого процессора.
В классическом конвейере данные сначала должны пройти до конца и быть выведены в кадровый буфер, теперь же данные, обработанные одним процессором, которые загружаются в кэш (stream output), могут быть вычитаны другим процессором (stream input). При этом все обработанные данные, выходящие из шейдерных блоков, могут снова поступить на вход конвейера. Такая "карусель" находится под управлением нового блока (Thread Processor), который вместо кэширования данных и отправки на следующие стадии конвейера пускает их по кругу, если, конечно, есть такая необходимость. Также переработан диспетчер ветвлений (GigaThread), теперь он может производить вычисления над несколькими шейдерами с ветвлением одновременно, а не последовательно, как в случае с G7x.
И еще один немаловажный факт: ALU у нас теперь только скалярные (забудьте про векторные, их уже нет, они проигрывают в производительности грамотно построенным скалярным), которые работают на "своей" 1350-МГц частоте. Унифицированные шейдерные процессоры представляют собой суперскалярные процессоры общего назначения для обработки данных с плавающей запятой. Традиционно в процессорах задействовано два типа математики: векторная и скалярная. В случае векторной математики данные (операнды) представляются в виде n-мерных векторов, при этом над большим массивом данных производится всего одна операция. Самый простой пример - задание цвета пиксела в виде четырехмерного вектора с координатами R, G, B, A, где первые три координаты (R, G, B) задают цвет пиксела, а последняя - его прозрачность. В качестве простого примера векторной операции можно рассмотреть операцию сложения цвета двух пикселов. При этом одна операция осуществляется одновременно над восемью операндами (двумя четырехмерными векторами). В скалярной математике операции осуществляются над парой чисел. Понятно, что векторная обработка увеличивает скорость и эффективность обработки за счет того, что обработка целого набора (вектора) данных выполняется одной командой. До недавнего времени векторная архитектура являлась в какой-то мере традиционной для графических процессоров, то есть в графических процессорах предыдущего поколения применялась векторная архитектура исполнительных блоков. Вместе с тем многие инструкции в шейдерах не используют все компоненты векторов. Поэтому в GPU до DirectX 9 применялась так называемая функция recall, которая описывала способ объединения двух инструкций в одну. К примеру, можно применять разные операции к значениям цвета (вектор из трех элементов, vec3) и к альфа-уровню. В этом случае вместо одной векторной команды над четырехмерными векторами необходимо выполнить одну векторную операцию для трехэлементных векторов плюс одну скалярную операцию (схема "3+1").
Векторные исполнительные блоки в графических процессорах ATI Radeon X1000 работают по схеме "3+1", т.е. способны выполнять за такт одну векторную операцию над четырехэлементными векторами или одну векторную операцию для трехэлементных векторов плюс одну скалярную операцию. Векторные исполнительные блоки в графических процессорах NVIDIA GeForce 6 работают по схеме "2+2", т.е. способны выполнять одновременно две векторные операции для двухэлементных векторов или одну векторную операцию для четырехэлементных векторов, а GeForce 7 кроме схемы "2+2" мог работать и по схеме "3+1". В графическом процессоре NVIDIA GeForce 8800 применяются полностью скалярные блоки, которые работают по схеме "1+1+1+1". Теоретически, такой подход обеспечивает большую гибкость.
Также из приведенной ниже схемы следует, что к каждому из восьми блоков процессоров подключено 4 блока TMU, состоящих из 4 модулей адресации (TA - определение по координатам точного адреса для выборки) и 8 модулей фильтрации (TF - билинейная фильтрация).

И самое интересное то, что теперь выборка и фильтрация текстур не требует ресурсов ALU и выполняется параллельно. Т.е. если раньше ALU затрачивал на эту операцию ресурсы, и при этом приходилось ждать конца выборки, то теперь математические операции выполняются непрерывно, а выборка идет параллельно (конечно, генерация текстурных координат (т.е. отправка запроса) еще отнимает некоторое время и у ALU ("А" на иллюстрации), но ждать завершения выборки уже не надо).

Что касается ROP, то они практически остались без изменения, и у G80 их шесть штук, каждый из которых способен обрабатывать 4 пиксела за такт (или 16 субпикселей, как показано на рисунке - синие квадратики вблизи кэша L2), что означает возможность обработки всего 24 пикселов за один такт в цвете и с Z-буфером (т.е. с данными о глубине). При работе только с Z-буфером специальная технология обеспечивает обработку до 192 самплов за такт, при условии, что один сампл соответствует одному пикселю. При включении 4-кратного полноэкранного сглаживания возможна обработка в Z-буфере до 48 пикселей за такт.
Кроме всего этого, G80 еще имеет блоки, запускающие на исполнение данные тех или иных форматов (Vertex, Geometry и Pixel Thread Issue).

Они подготавливают данные для числодробилки в шейдерных процессорах в соответствии с форматом данных, текущим шейдером и его состоянием, условиями ветвлений и т.д., причем впоследствии они будут объединены в один блок (т.е. почти как Ultra-Threading Dispatch Processor у ATI).

Еще есть Setup/Raster/ZCull - блок, разбивающий полигоны на пиксели. И про Input Assembler мы говорили чуть выше.
Все остальное мы благополучно опустим и перейдем к первому процессору нового поколения от AMD - R600, который был разработан новоиспеченным графическим подразделением, созданным из купленной в 2006 г. ATI. Причем, AMD переняла от ATI ее постоянную карму – "догонять" конкурента (вообще, у AMD и у ATI в этом смысле много общего). Так что выхода R600 все ждали почти полгода, и как результат – "привычное" падение продаж, потеря позиций на рынке и миллионные убытки. Впрочем, AMD тоже не привыкать к подобным ситуациям, ведь за 30 лет своего существования она заработала в чистом виде аж целых $300 млн.… Думаю, аналогии и сравнения с прямым конкурентом и с остальными игроками IT-рынка проводить нет смысла, цифра говорит сама за себя. Так что если вам кто-то скажет, что AMD скоро загнется, можете рассмеяться ему в лицо: AMD "загибается" уже 30 лет.
Как уже было сказано выше, основные шаги к унифицированной архитектуре ATI сделала еще в R520 (и в R500, который был первым унифицированным процессором, отчего AMD называет R600 "архитектурой унифицированных шейдеров второго поколения"), т.е. основные изменения коснулись только пиксельных и вершинных блоков.
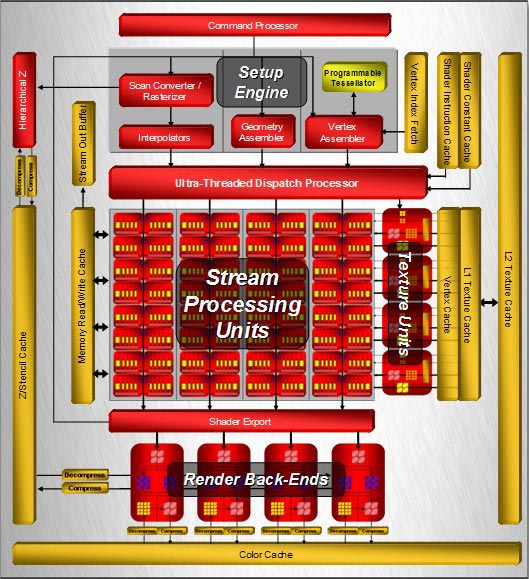
Итак, шейдерный блок состоит из 320 унифицированных суперскалярных потоковых процессоров, которые сгруппированы в 64 блока (вычислительные единицы). Каждый из них содержит по 5 ALU плюс блок ветвлений и условных переходов (Branch Execution Unit), который освобождает основные ALU от этих задач и, по идее, снижает потери от переходов на ветвящемся коде шейдера.
Согласитесь, число "320" выглядит довольно внушительно по сравнению с "128" у NVIDIA, но сравнивать их только по числу потоковых процессоров некорректно (хотя и по частоте они также несопоставимы, так как частота скалярных процессоров у G80 отличается от частоты всего ядра, и при этом она больше, чем у R600). У R600 процессоры не однородны, и в каждом из 64 блоков только один из 5 ALU может выполнять сложные операции (SIN, COS, LOG, EXP и т.д.). Остальным четырем под силу только самые простые инструкции умножения или сложения (MADD), в то время как у G80 все процессоры могут выполнять любые операции, будь-то сложные или простые. Это влечет за собой большую производительность, как в "чистом" виде (т.е. в гигафлопсах, которых R600 может дать только 475, а вот из G80 в идеале можно выжать аж 518), так и в реальных приложениях. Именно по этому Radeon HD 2900 XT позиционируется AMD как ответ на GeForce 8800 GTS, а с 8800 GTX должен будет "драться" 2900 XTX (а теперь просто представьте, что и в каком количестве должно быть напихано в XTX, чтобы тот вывел AMD вперед!), которого еще нет. К слову, AMD с каждым месяцем будет все сложнее перегнать NVIDIA, так как последняя не собирается сидеть сложа руки, и уже успела выпустить модель с суффиксом Ultra. Эта версия отличается от GTX повышенными частотами, что, конечно же, привело к росту производительности. Да и не стоит забывать про упорные слухи о GeForce 8900 GTX и сдвоенной 8950 GX2.
Как и у предшественников, в R600 для распределения и хранения шейдерных инструкций применяется Ultra-Threading Dispatch Processor, который помимо пиксельных инструкций теперь хранит и ставит в очередь векторные и геометрические.
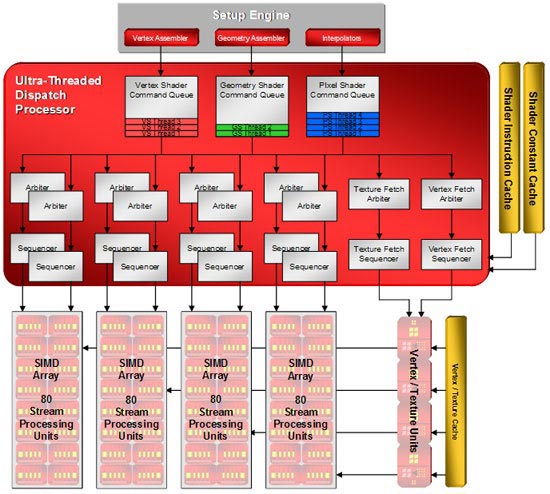
Что касается блоков выборки (TMU), то они также претерпели изменения, но незначительные. Их у нас всего четыре штуки, но при этом нет большой потери производительности. А для того чтобы не начинать отдельный долгий разговор с пояснениями, скажу, что и у NVIDIA их немного - по сути восемь штук. А вообще, достаточно просто взглянуть на структуру блока и сравнить его с подобным от NVIDIA.
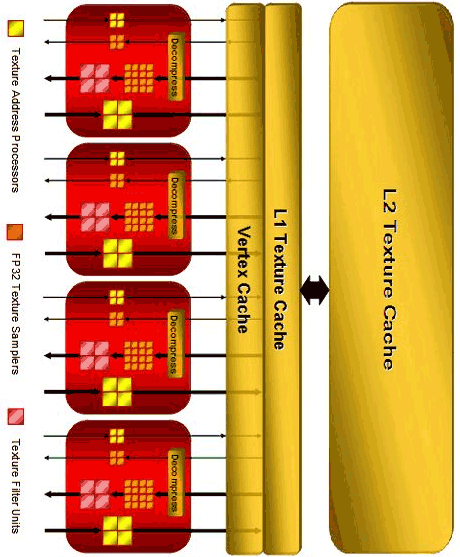
Просто мы смотрим на число выдаваемых текстур за такт, и видим что у AMD 16 текстур с фильтрацией и 16 без, что, конечно, намного меньше, чем у NVIDIA с ее 32 "чистыми" текстурами (по сути, получается всего 16, поскольку фильтрация либо есть, либо ее нет). С ROP (которые, к слову, не перетерпели больших изменений) все так же - R600 имеет всего 4 таких блока, но они способны выдать 16 пикселов за такт (у NVIDIA, как вы помните, 6 ROP, т.е. 24 пиксела). Я ни на что не намекаю, но вспомним, сколько ватт кто потребляет, кто сколько тепла выделяет, сколько у кого транзисторов, кто сложнее, "массивней" и т.д. Смотрим на результат и понимаем, кто тащит всю команду назад, кто положил в банк меньше всех денег, кто самое слабое звено… Ну, это уже из другой оперы… Главное, чтобы мы почувствовали разницу в подходах: простой - сложный.
Опять же, хочется еще многое сказать, но впереди у нас еще длинный разговор, так что оставим "извечный бой" и переходим к…
GPU вне игры
Так, а теперь вспомним все, что было сказано выше (если надо, перечитайте) и выделим из этой питательной для ума массы "прыгающую точку" - флопс. Именно она станет отправной точкой нашего разговора в данной части статьи.
Итак, производительность Intel Core 2 Duo Е6700 (с частотой 2,66 ГГц) – 21,28 Гфлопс, производительность GeForce 6800 Ultra – 54 Гфлопс. Как видите, даже GPU позапрошлого поколения спокойно обгоняет по производительности новенький двухъядерный процессор. А если вспомнить характеристики последних GPU, так вообще становится страшно: пол терафлопса - это просто-таки бешеная производительность, даже самые дорогие серверные CPU остаются далеко позади. (Так, просто на заметку - Sony PlayStation 3 имеет производительность 2 терафлопс, что позволило одной исследовательской группе с помощью SPS 3 моделировать синтез белка с головокружительно скоростью. Впрочем, тут не все так просто - поговорим об этом ниже.) Так почему такой колоссальный разрыв? И почему эта мощь задействована только в играх, а остальное время мирно дрыхнет, пока "малопроизводительный" CPU работает как проклятый и в дождь, и в слякоть?
Во-первых, одно арифметическое устройство, оперирующее числами с плавающей запятой, занимает очень мало места на кристалле, и их можно "напихать" туда очень много. Вот только проблема в том, что не всегда получается загрузить их всех работой. Тут в первую очередь вина ложится на память, которая хоть и слепо следует закону Мура, увеличивая свой размер почти каждый второй год, но темпы увеличения пропускной способности памяти уже на четверть меньше, а ее латентность (задержка обращения к новому участку памяти) сокращается вообще еле заметными темпами. Конечно, ту же латентность можно сократить, втискивая в процессор больше кэш-памяти, но это ведет к тому, что ее размер уже занимает почти половину кристалла. При этом даже большие размеры - не всегда панацея от всех бед. Ведь часто встречается ситуация, когда обращение к памяти происходит только однажды (потоковая обработка). С оперативной памятью, думаю, все и так понятно - на первый взгляд, возможности почти ничем не ограничиваются, любая инструкция в программе может считать или записать произвольную ячейку большой оперативной памяти, но на деле это выливается в совершенно нерегулярный набор обращений к памяти. Что, по сути, приводит не только к "каше", но и увеличению латентности, да и сама скорость работы оперативной памяти изначально недостаточно велика.
Вторая проблема - недостаточно хорошее распараллеливание, так как те инструкции, которые можно выполнить независимо, тем самым повысив быстродействие (это не относится к зависимым инструкциям, так как распараллелить их очень трудно), нужно еще распознать - на выявление скрытого параллелизма тратится заметная порция площади кристалла (да и тактов тоже). При этом сам процессор настолько сложен, что даже если инструкции могут хорошо распараллелиться (т.е. не зависят друг от друга и могут выполняться параллельно), все равно достаточно много ресурсов уходит на то чтобы преобразовать инструкции в "процессорный код", распределить по вычислительным устройствам, а после выполнения собрать и проверить. А если инструкция содержит обращение к памяти, то время обработки оной может вообще затянуться на десятки и даже сотни тактов. И все это из-за "особенностей" памяти! Поэтому чем меньше программа обращается к памяти, тем лучше - это программистам на заметку. Как следствие - даже при самом лучшем стечении обстоятельств не удается загрузить все исполнительные устройства. Кстати, это было одной из главных проблем архитектуры NetBurst - несмотря на просто колоссальный задел на будущее и гениальные инженерные решения, полностью разгрузить его работой было по сути невозможно. Недаром Hyper-Threading NetBurst показывает практически двукратный прирост производительности - HT позволяют эффективнее загрузить исполнительные устройства процессора, "разрезая" его надвое.
А вот у GPU со всем этим проблем меньше. Ведь если вспомнить описанное выше, то можно сразу выделить одну вещь: GPU изначально разрабатывался и долгие годы шлифовался для выполнения независимых операций. И на данном этапе графический процессор является почти идеальным представителем конвейерной и параллельной обработки. При этом для обеспечения произвольного порядка обработки, например, фрагментов изображения, текстура, в которую выполняется рисование, не может в то же самое время использоваться и для выборки. То есть видеопамять делится на непересекающиеся участки только-для-чтения и только-для-записи. Также новые точки и структуры в видеопамяти не могут совпадать, так как положение каждого фрагмента (пиксела) строго фиксируется еще на этапе растеризации. Также при обращении одного шейдера (последовательность программ) к памяти конвейер GPU не простаивает в ожидании конца выборки, а просто переключается на другую часть шейдера (т.е. на обработку другого пиксела), им и занимается. В результате получаем гибкость и эффективное распараллеливание процессов.
Конечно, от ячеек памяти, из которых можно и считывать, и в которые можно записывать, не обойтись, поэтому для этой цели предоставляются специальные регистры для каждого шейдера, и благодаря этому все промежуточные вычисления ведутся без обращения к внешней памяти, куда попадает лишь финальный результат. Также шейдеры, как правило, являются достаточно небольшими программами, а это ведет к тому, что можно хранить код программы не в видеопамяти, а внутри процессора, что еще больше увеличивает быстродействие за счет минимизации обращений к памяти. И как результат всего этого (и не только этого) мы имеем такую большую "чистую" производительность.
Вообще, если образно сравнивать GPU и CPU, то GPU выглядит такой себе спортивной машиной, а CPU - танком. Как вы понимаете, танк грязи не боится, ездит везде, делает почти все (даже стреляет!), но имеет весьма посредственную скорость. А вот машина - быстрая, мобильная, красивая, но ненадежная, и тем более не везде проедет. Конечно, если постараться, то из машины можно сделать что-то вроде танка, но вы прекрасно понимаете, сколько всего надо сделать и сколько это будет стоить (представьте, какие метаморфозы должна перетерпеть, например, Феррари), да и кто будет этим заниматься? Хотя способностей нашей "машины" вполне может хватить для некоторых специальных задач, и уже давно ведутся работы в этом направлении.
Конечно, изначально GPU могли выполнять только очень простые операции, притом ни о какой более-менее приемлемой точности говорить не приходилось. Переломный момент наступил в конце 2002 г., когда в продаже появились видеокарты GeForce FX от NVIDIA и Radeon 9500 от ATI. В них была заложена поддержка шейдеров Shader Model 2.0, которые накладывали на производителей определенные требования. А именно - умение выполнять гораздо более сложные программы и по количеству инструкций, и по числу обращений к текстурам, вдобавок, все промежуточные операции должны выполняться с действительными числами высокой (по сравнению с предшествующими GPU) точности. И что немаловажно, появилась поддержка операций с плавающей запятой, хотя их точность была небольшой (только позднее появились GPU с половинной точностью - FP16), но это уже был настоящий прорыв. Из-за возросшей сложности шейдеров пользоваться ассемблером стало не так удобно, и приблизительно в то же время стали появляется С-подобные языки высокого уровня (Cg, HLSL и GLSL), которые, несмотря на свою схожесть, имеют много отличий в лексике и синтаксисе - но в целом, это был достаточно большой шаг вперед.
Конечно же, бурное развитие и усложнение GPU, их растущая производительность и простота программирования не могли не впечатлять ценителей гигафлопс. И первыми это подметили разнообразные университеты и исследовательские институты, которые начали активно работать в данном направлении примерно с 2003 г. Именно этот год можно считать настоящим началом новой "не-игровой" жизни для GPU, так как начиная с этого года стали появляться научные статьи, посвященные алгоритмам и принципам расчетов общего назначения средствами графических процессоров (GPGPU - General-Purpose Computation on GPUs). А с 2004 г. регулярно организуются научные конференции в рамках GPGPU.
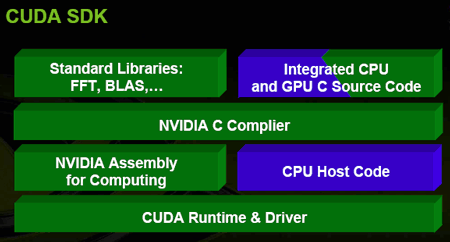
Как оказалось, GPU под силу не только расчет и построение игровых сцен, но и тяжелые ресурсоемкие научные расчеты (например, расчеты синтеза белка, коллапса сверхновой, построение нейронных сетей и т.д.) Причем, графический процессор может выполнять их в несколько раз (до 10 и более) быстрее, чем самый производительный и дорогой CPU. И хотя число задач, которые под силу GPU, все-таки ограничено, оно постоянно растет - стараниями ученых мужей, усилиями производителей видеокарт, которые постоянно усложняют GPU, проводят различные мероприятия, семинары и мастер-классы по программированию на GPU. При этом NVIDIA даже создала специальный язык - CUDA, который полностью поддерживается G80, единственной задачей которого является облегчение работы программистов при проектировании неигровых задач на GPU.
Но самое главное - возможности GPU постоянно растут, и организаций, которые заинтересованы расчетами на GPU, становится все больше (вспомнить хотя бы тот же расчет коллапса сверхновой, который был произведен только средствами одного массива GPU, так как производительности массива CPU было недостаточно для получения относительно быстрого результата).
С выходом Shader Model 3 ситуация еще активнее стала набирать обороты, так как вместе с повышением производительности самих видеокарт появилась возможность выполнять на GPU более сложные программы - с циклами, динамичными и условными переходами, и так далее. Также была повышена точность как целочисленных вычислений, так и операций с плавающей запятой. А вот выход четвертой версии шейдеров - просто подарка лагерю GPGPU, так как наконец-то графический процессор получил полную поддержку стандарта IEEE 754 (т.е. поддержку одинарной точности в операциях с плавающей запятой (FP32)), что позволяет на G80 и R600 выполнять практически любые программы и расчеты, причем любой сложности (конечно с некоторыми ограничениями).
Но очевидно, что сообществу GPGPU, в который входят практически все крупные научные учреждения, было бы туго без непосредственной поддержки самих производителей. Конечно, те не стоят в сторонке, а принимают самое активное участие в развитии расчетов общего назначения на графическом процессоре. И даже выпускают специализированные продукты, предназначенные для этого пока молодого, но довольно перспективного рынка. Правда, ATI несколько лет скептически смотрела на концепцию GPGPU, и только с появлением R520 начала активно сотрудничать с исследовательскими организациями. Как результат, уже AMD выпустила специальный потоковый компьютер для расчета неграфических задач (Stream Computing, основанный на R580, он выпускается под названием FireStream - по логике вещей, вскоре стоит ждать появления подобного продукта на основе R600).

Также при содействии Стэндфордского университета разрабатывается специальная библиотека GROMACS, так как для не-графических расчетов необходимо иметь доступ к GPU на самом низком командном уровне и программировать в этих командах, что, как любое низкоуровневое программирование, чрезвычайно трудоемко.
А вот NVIDIA вникла в концепцию GPGPU с самого начала, даже больше, является одним из самых активных участников данного проекта. К тому же именно ее GeForce 6800 была основным "подопытным кроликом" в неграфических вычислениях. Позднее ее место заняла седьмая модель, а теперь вот пришел черед G80. Также недавно состоялся анонс новой специализированной линейки - Tesla. Она предназначена для расчетов общего назначения, которая стала основным ответом на Stream Computing от AMD (NVIDIA, кстати, называет свое детище GPU Computing). Причем данная линейка имеет довольно неплохой ассортимент в виде целых трех устройств: C870, S870, D870.
Tesla C870 является внутренней платой расширения на видеопроцессоре серии GeForce 8 (внешне практически идентична "обычной" 8800), устанавливаемой в разъем PCI-E x16.

Устройство требует внешний источник питания и потребляет порядка 170 Вт энергии в пике нагрузки. По заявлению производителя, Tesla C870 способна выдать 518 гигафлоп (т.е. как обычная 8800 GTX). Tesla S870 (между прочим, брат-близнец анонсированной ранее внешней системы для визуализации Quadro Plex) по сути представляет из себя сервер, основанный на четырех графических процессорах все той же 8 серии GeForce, работающих параллельно.

Tesla S870 имеет вычислительную мощь аж 2 терафлопа, вот только ест она около 800 Вт в пике нагрузки. И последняя - Tesla D870 является той же S870 по производительности, но более энергоэкономной (только 550 Вт) и компактной (типоразмер 1U).

Если вы хотите приобрести подобные продукты, то вот приблизительные цены на них: $1500 (C870), $12000 (S870) и $7500 (D870). Но самое главное, что благодаря CUDA (Complete Unified Device Architecture - унифицированная вычислительная архитектура, являющаяся инструментом для программирования под аппаратную часть инициативы GPGPU, которая уже была опробована на NVIDIA G80) данным продуктам под силу не только сугубо научные расчеты, но и более приближенные к IT дела - обработка видео, звука, расчет физики, механики сплошных сред, рендеринг анимации и т.д.
Хотя все-таки приходится констатировать, что данные продукты и вообще не-графические расчеты на GPU являются пока что уделом небольших научных организаций, предприятий и IT-фирм, которые не могут себе позволить суперкомпьютер. Но все, как говорится, начинается с маленького, и может быть, через пару лет в домашнем компьютере GPU не будет простаивать во время "обычной работы"… Впрочем, может оказаться, что до этого и не дойдет. Так как грядут большие перемены.
Завтра
Тут стоит сразу оговориться: сейчас мы вступим на немного зыбкую почву, так как продуктов, о которых пойдет речь дальше, нет не то что на прилавках, а в большинстве случаев даже в кремнии они еще не воплощены. Но официальной (или почти официальной) информации все-таки предостаточно, так что мы можем позволить себе небольшую вольность и поговорим про то, что будет "завтра". При этом стоит учитывать, что где-то ошибка наверняка должна закрасться (консультантов среди производителей, к сожалению, не имею), ведь многое еще может измениться.
Итак, условно скажем, что все началось в конце 2006 г., именно тогда AMD во время завершения поглощения ATI объявила на весь мир о своей новой инициативе под названием Torrenza.
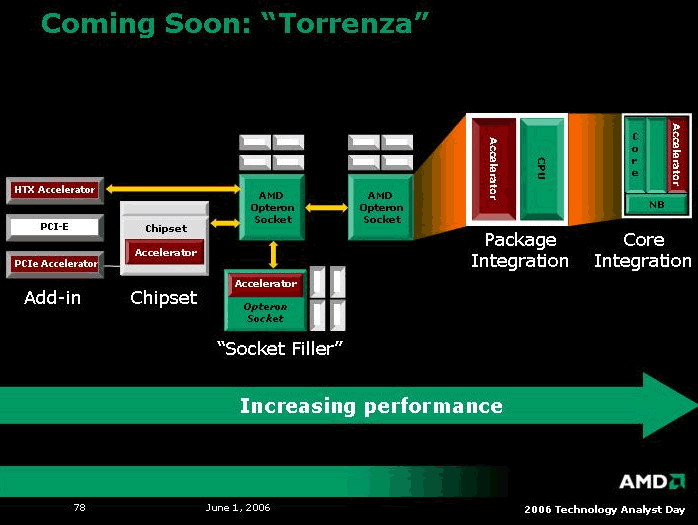
В первую очередь, Torrenza - это бизнес-инициатива, своеобразный призыв к сотрудничеству сторонних разработчиков в разработке платформы будущего. И как стало известно, AMD уже более трех лет в тесном сотрудничестве с такими компаниями как IBM, HP и Sun Microsystems работала в этом направлении. А объявлением на весь мир идей архитектуры Torrenza она решила приманить побольше других производителей. И надо отметить, что это ей удалось - с каждым месяцем все больше и больше компаний-производителей говорят о пользе данной инициативы и готовы приступить к совместным разработкам. Но вопрос: вокруг чего сыр-бор, и что такое Torrenza?
Тут все просто и даже почти гениально (хотя не ново). Как оказалось, Torrenza - долгосрочные планы AMD, которые никак не связаны с экстенсивным развитием многоядерности (хотя по этому пути она будет продолжать развиваться некоторое время). Компания прогнозирует возникновение спроса на принципиально новый тип процессоров - Accelerated Processing Units (APU).
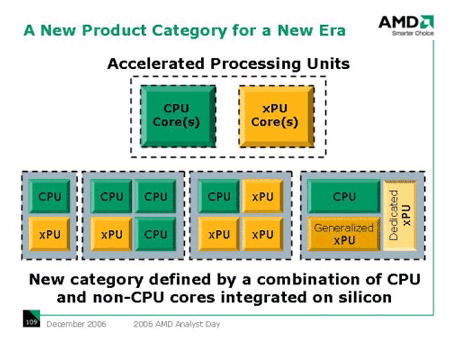
И как вы понимаете, данный план несколько отличается от планов Intel, которая на каждом углу твердит о постепенном наращивании количества старых добрых ядер на одном кристалле. (Впрочем, несколько тузов у Intel в рукаве все-таки припрятано - о них, а точнее, об одном из них, потом.) А вот концепция APU заключается в несколько ином подходе к многоядерности, а именно: вместо кучки однотипных CPU предлагается засовывать в одну упряжку много разнообразных сопроцессоров, причем сугубо специализированных, которые могут предназначаться для самых разных целей. Сначала, конечно, планируется связывать их через шину HyperTransport (т.е. каждый сопроцессор будет иметь свой разъем на материнской плате или иметь вид платы расширения), затем наступит более сложный этап - сбор всех сопроцессоров в одну или несколько упаковок. А после всех этих мытарств их должны впихнуть в один кристалл. Еще позже будут вестись дальнейшее уплотнение и "кровосмешение". При этом AMD планирует впоследствии сделать полностью отрытую платформу, для облегчения создания новых сопроцессоров от сторонних производителей. И кстати, кандидат номер один для сопроцессора уже давно имеется - это математический сопроцессор (да-да, все возвращается на круги своя) от ClearSpeed, CSX600 Advance Board (выпущенный, кстати, еще в 2004 г.), который представлен в виде платы расширения и может увеличить вычисления операций с плавающей запятой на 25 гигафлопс.

И это, по идее, только начало. А в целом планируется создать целый спектр различных сопроцессоров - специальный процессор, ускоряющий обработку физики (может, даже PhysX от Ageia подойдет), процессор, ускоряющий декодирование видео, ну и так далее. Т.е. вся затея очень интересна и выглядит довольно перспективно, но тут стоит учитывать один факт - следует для начала создать спрос (пускай, даже искусственно) на подобные гибридные продукты, иначе у их производителя останется только один путь - утонуть в убытках. Именно поэтому AMD будет делать все для продвижения идеи Torrenza в массы, а сам штурм рынка планируется начать приблизительно в 2009–2010 гг. Конечно, сроки могут и сместиться, как в ту, так и в другую сторону - все зависит от рынка.
Так причем здесь видеокарты? - спросите вы. Дело в том, что при анонсе Torrenza, был также анонсирован первый продукт, который откроет начало данной инициативе - продукт, создающийся с учетом графических наработок ATI, который носит кодовое название Fusion. И как становится понятно, Fusion - это устройство, в котором будут объединены GPU и CPU вместе.
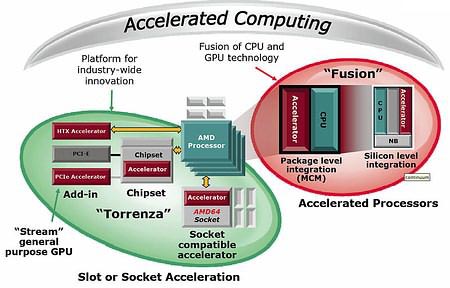
Но, конечно, сначала планируется начать с многочипового производства, а только затем перейти к одночиповой компоновке. И впоследствии интегрировать "графическое ядро" в ядро процессора общего назначения (недавно VIA Technologies также предлагала что-то подобное под названием CoreFusion, но эта разработка носила несколько другой характер, да и не вызвала такого резонанса, как Fusion от AMD).
Получается, что в перспективе мы имеем совершенно новый самодостаточный и многофункциональный продукт, которому под силу будут не только графические расчеты, но и остальные более "мирные" вычисления. При этом графическая часть нового "гибридного процессора" не будет простаивать во время обычной работы. Также планируется, что подобные системы (как и Torrenza в целом) будут рассчитаны на самые разные решения - мобильные, серверные, настольные и даже портативные. Все это, конечно, очень хорошо и интересно, но сразу возникает конкуренция между "раздельными" (CPU и GPU) и "гибридными" платформами (собственно Fusion), и не факт, что последние будет экономически выгодней (а главное - выгодней по производительности), чем первые. Впрочем, несмотря на всю эту неопределенность, AMD утверждает, что к 2009 г. (именно тогда планируется появление Fusion) рынок уже будет создан, и спрос на подобные устройства будет достаточным. При этом стоимость Fusion будет ниже, чем у "раздельных" продуктов. Так что поверим AMD пока на слово, благо планы ее потрясают - в дальнейшем Fusion будет иметь по несколько ядер CPU и "GPU" (именно в кавычках, так как это уже будет не то наше GPU, каким мы его представляем сейчас). А когда туда начнут подсаживать остальные сопроцессоры, на выходе мы будем иметь уже настоящее чудо инженерной мысли, умеющее делать все на свете. Но я думаю, что хватит заниматься пиаром того, чего еще нет, и поговорим про диковинки от другого производителя - опять же, несуществующие.
Итак, оружие возмездия от Intel называется Larrabee. Вот только в отличие от остальных, Intel пытается как можно больше напустить дыма перед своей разработкой (Intel даже не поленилась почистить всю информацию по поводу Larrabee после откровений Патрика Гелсингера на пекинском IDF 2007), так что информации просачивается крайне мало. Но все-таки более-менее конструктивно пообщаться мы сможем.
Условной датой рождения этой технологии также можно считать конец 2006 г., когда на одном специализированном сайте Intel разместила объявление о наборе высококвалифицированных разнопрофильных специалистов в новоиспеченное подразделение - Larrabee Development Group. (Точнее, "новоиспеченным" оно было в августе 2006 г., а только потом было принято решение усилить данное подразделение свежей кровью. По некоторым данным, сейчас над Ларраби трудятся около 800 человек - к примеру, у NVIDIA вдвое меньше людей задействовано на разработках графического чипа.) Многие тогда предположили, что Intel кует свою собственную дискретную графику (среди требований к специалистам был опыт проектирования графических архитектур), а значит, настали черные дни для NVIDIA (про ATI никто сильно не волновался, к тому времени она уже была благополучно куплена), но как оказалось, все намного интересней.
Так вот, Larrabee является ни чем иным как конкурентной разработкой, призванной бороться с Fusion от AMD. Только при этом она выглядит на порядок интересней, так как она не является заменой GPU и CPU (что, по сути, и предлагает AMD), а "всего-навсего" отдельным продуктом. Чем-то вроде специализированного сопроцессора, который будет выполнен в виде карты расширения.
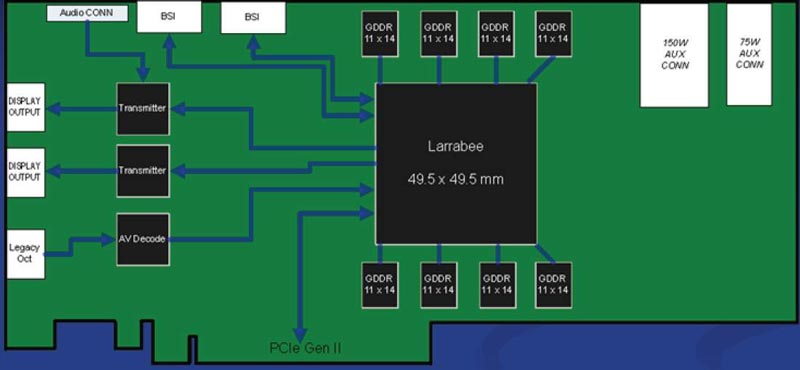
При этом изначально планируется, что он будет оснащен 16 (шестнадцатью) процессорами, спроектированными на основе усовершенствованной архитектуры х86. И впоследствии также прогнозируется увеличение их числа до 24, затем 32 и к 2010 г. до 48 процессоров. Сам Larrabee, скорее всего, может появиться в районе 2009 г. При этом он будет внешне напоминать видеокарту, иметь интерфейс PCIe второго поколения, два разъема дополнительного питания (150 и 75 Вт), память около 2 Гб (причем, может быть сразу GDDR5), 256-битную ширину доступа к памяти, пропускную способность 128 Гб/с и производительность в 1 терафлопс (к слову, как предполагается, 80-ядерный процессор от Intel будет иметь также 1 терафлопс), а сам чип будет просто огромным - в два с половиной раза больше, чем самый крупный GPU.
Что касается двух "BSI" возле аудио-входа верху "видеокарты", то бытует мнение, что это не что иное как соединительные разъемы а-ля CrossFire и SLI, т.е. предположительно можно будет сделать целый массив подобных монстров-ларрабеев.
Но самое главное - на Larrabee будут доступны вычисления самого разного рода, начиная от графических и кончая сугубо научными ребусами. Т.е. данное устройство будет просто идеальным оружием против сложных задач, например того же GPGPU, и не чета всяким там Stream Computing и GPU Computing от NVIDIA и AMD (думаю, Torrenza сможет что-то еще показать, но только не на ранних этапах развития). Впрочем, поживем-увидим, как оно все сложится.
Но не стоить думать, что видеокарты как таковые ждет скорая смерь - они еще долгое время будут развиваться параллельно всяким вышеизложенным новаторским разработкам. По крайней мере последний из Могикан - NVIDIA, которая, если верить назойливым слухам, принимает непосредственное участие в разработке Larrabee, смотрит твердо вперед и не собирается, по крайней мере в ближайшее время, свернуть с намеченного пути. Так что несмотря на всякие игры с GPGPU, она будет продолжать радовать нас новыми видеокартами. Впрочем, как и AMD, которая также не собирается сворачивать свои графические разработки в ближайшее время. Но как оно будет, знают лишь производители.