
Настало время подвести итоги недавней презентации NVIDIA и собрать воедино всю озвученную информацию. После долгих слухов и домыслов графический гигант наконец-то анонсировал второе поколение GeForce RTX. Новая архитектура, новые программные возможности и новый уровень производительности. Обо всем этом мы поговорим в данном обзоре.

Видеокарты GeForce RTX 3000 должны стать серьезным скачком для индустрии, делая RTX-технологии доступнее. Ключевыми преимуществами последнего поколения являются: реализация новой архитектуры Ampere с обновленными RT-ядрами и тензорными ядрами, переход на 8-нм техпроцесс и применение самой быстрой в мире памяти GDDR6X. Также компания продолжает развивать программные технологии, представляя новые инициативы в рамках NVIDIA Reflex, NVIDIA Omniverse Machinima и NVIDIA RTX IO, о которых подробнее поговорим ниже.

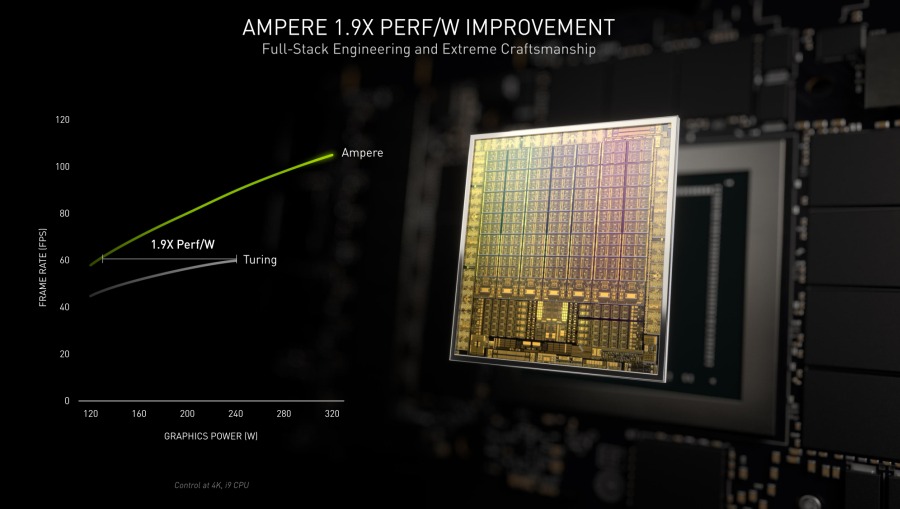
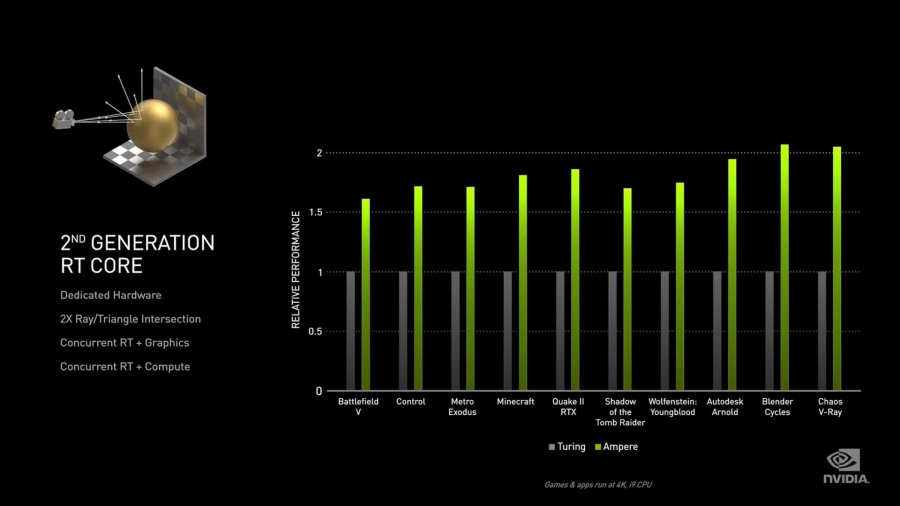
Ampere серьезно превосходит Turing в производительности на ватт, вплоть до 1,9 раз в играх и до 2 раз в профессиональных приложениях для рендеринга.
Пока нам представлено три видеокарты — GeForce RTX 3090, GeForce RTX 3080 и GeForce RTX 3070. И все они должны превзойти по производительности GeForce RTX 2080 Ti, даже младшая из названных моделей. А для GeForce RTX 3080 заявлено двукратное превосходство над GeForce RTX 2080.
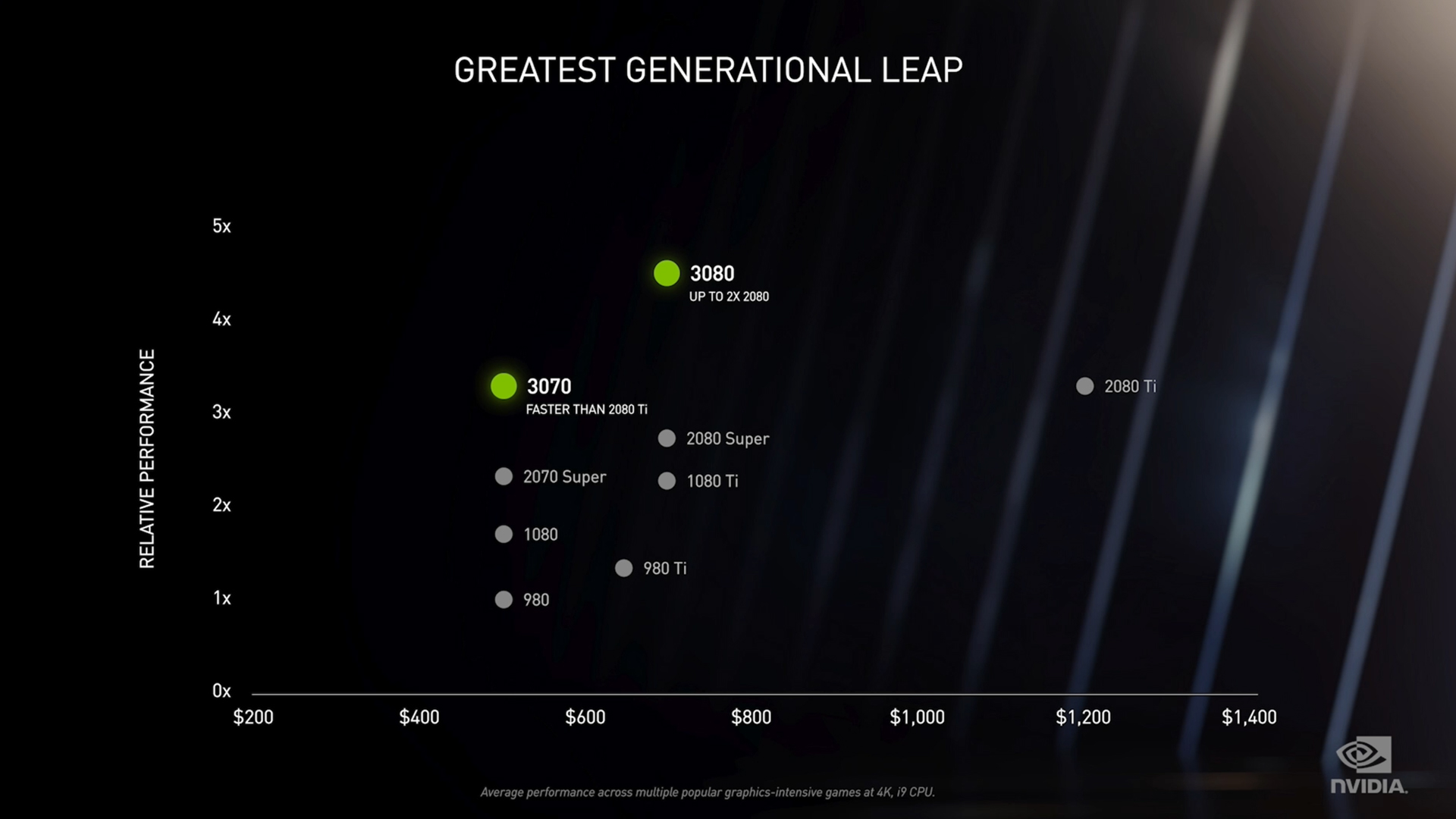
Сложно припомнить ситуацию, когда сразу несколько новых моделей могли потеснить существующий флагман. А GeForce RTX 3090 и вовсе выглядит «монстром» со своими характеристиками — 10496 потоковых процессоров CUDA и 24 ГБ памяти на 384-битной шине.

Даже GeForce RTX 3080 впечатляет своими основными параметрами, поскольку в активе этой видеокарты 8704 потоковых процессоров CUDA, что вдвое больше количества аналогичных блоков у GeForce RTX 2080 Ti.

Но прежде чем сравнивать характеристики нужно поговорить об архитектуре.
Архитектура Ampere и особенности новых GPU
Компания NVIDIA пока не раскрыла всю информацию о технических нюансах Ampere, но основные моменты нам уже известны. Первым продуктом на новой архитектуре стал представленный в мае ускоритель вычислений NVIDIA A100.

NVIDIA A100
Это специализированное устройство для высокопроизводительных систем. В основе его находится графический процессор A100 с 8192 ядрами CUDA, но рабочие версии GPU оперируют 6912 потоковыми ядрами. Специально для игрового направления разработанный GPU GA102 стал основной для GeForce RTX 3090 и GeForce RTX 3080. GPU A100 насчитывал 128 мультипроцессорных блоков SM по 64 вычислительных ядра и 4 обновленных тензорных ядра в каждом.
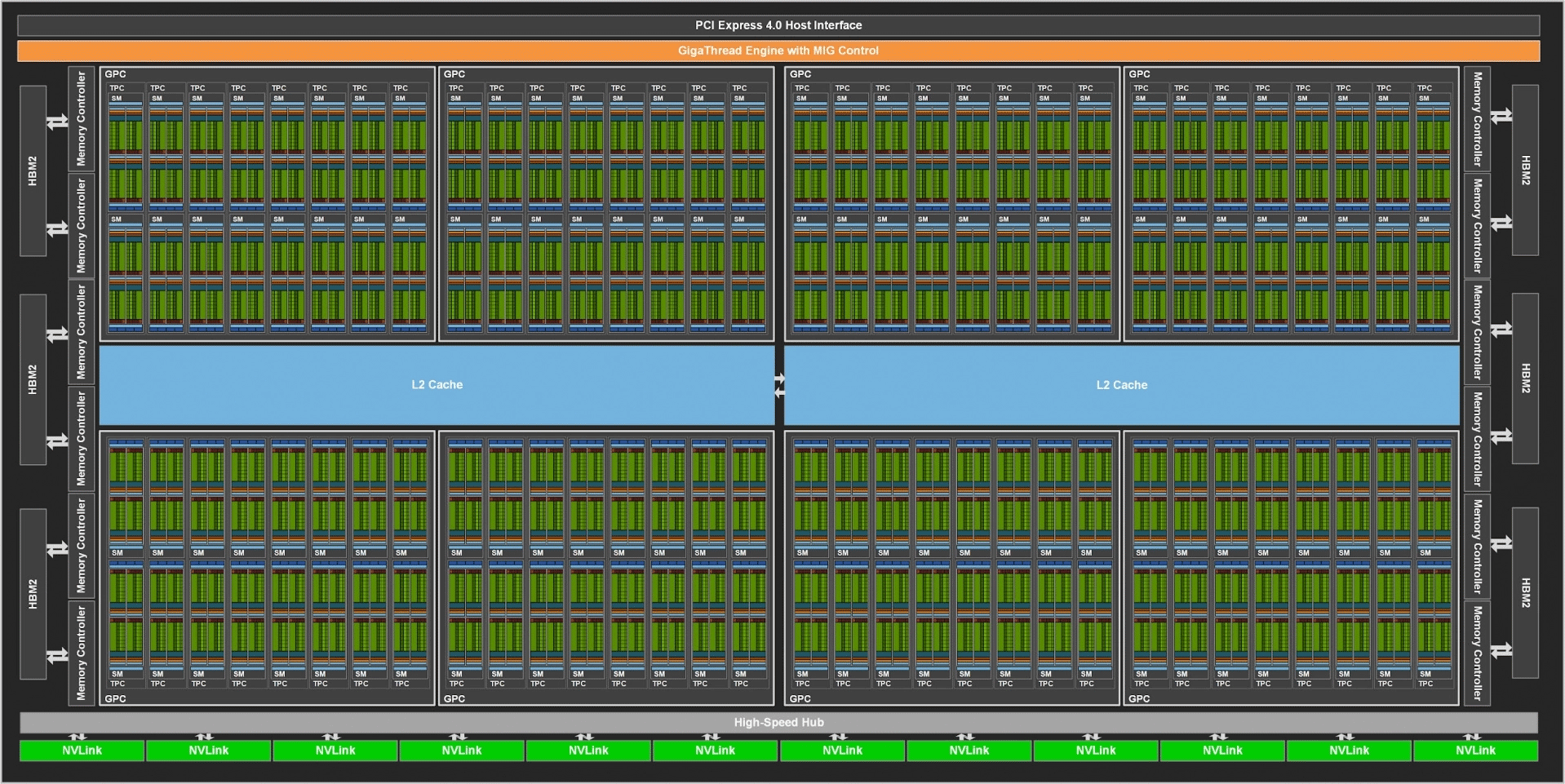
На более крупном уровне все SM объединены в кластеры GPC. У A100 это 8 кластеров по 16 SM в каждом. У процессора TU102 (GeForce RTX 2080 Ti и Titan RTX) это 6 GPC по 12 SM, у TU104 (GeForce RTX 2080) это 6 GPC по 8 SM. И во всех случаях SM оперирует 64 ядрами для графических вычислений FP32. Полная схема процессора GA102 пока недоступна, хотя NVIDIA использует определенную иллюстрацию, на которой можно четко выделить 7 кластеров.

Ключевым изменением игровых GPU Ampere стало удвоение вычислительных блоков FP32 — по 128 на SM, плюс 64 блока INT32. При этом новый SM сохранил основную структуру старых SM. Это четыре массива обработки данных со своими диспетчерами и планировщиками задач, 4 блока выборки текстур и блок RT для ускорения трассировки лучей. В данном случае реализованы новые RT-ядра второго поколения с повышенной производительностью. Задействовано 4 тензорных ядра по типу NVIDIA A100. У Turing было по 8 тензорных ядер на в SM. Но тензорные ядра Ampere 3-го поколения обещают намного большую производительность.
Сравнить структуру SM к NVIDIA 100, GeForce RTX 3090 и GeForce RTX 2080 Ti можно по нижнему слайду.
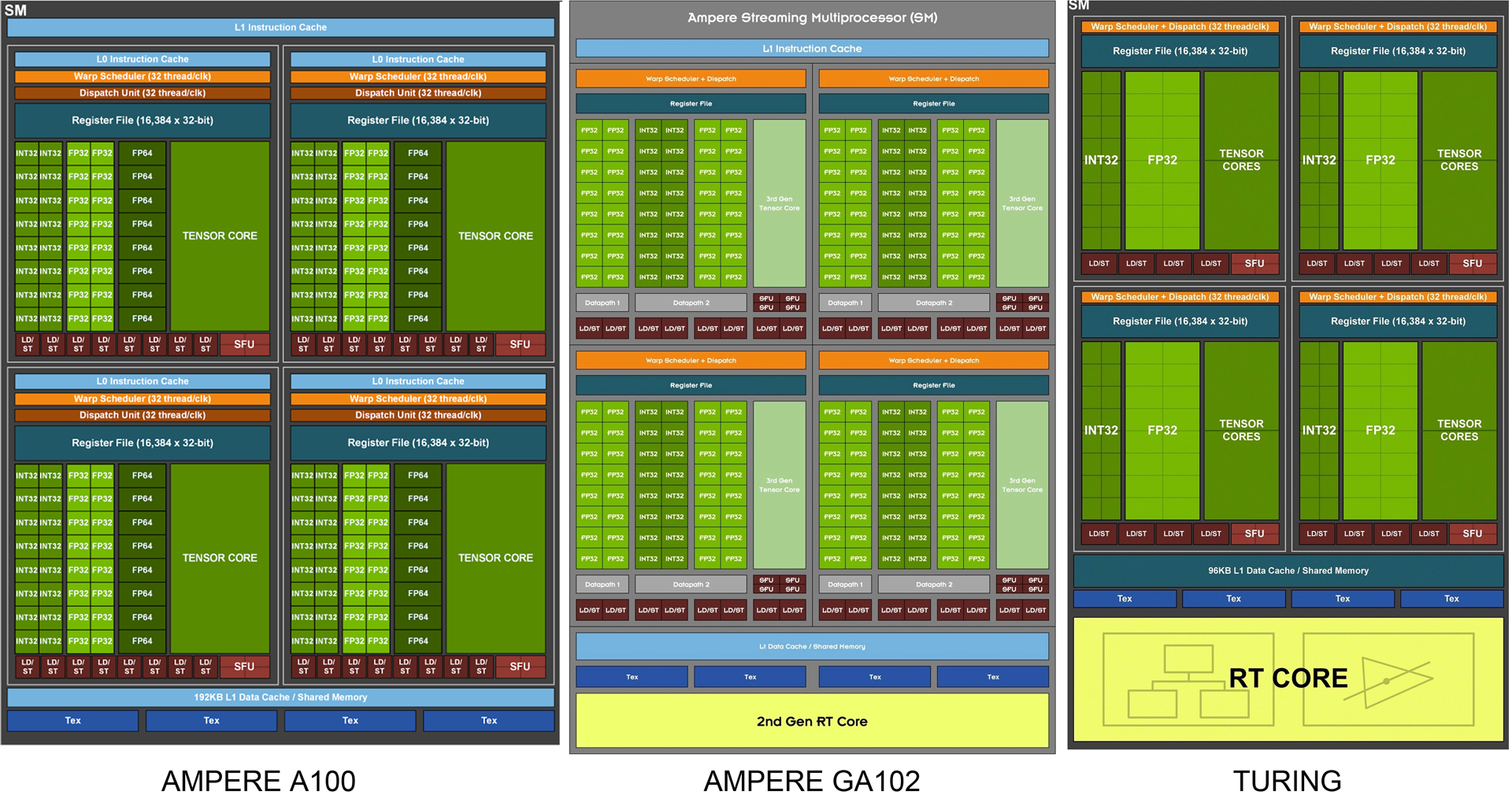
Увеличение производительности SM важно для выполнения современных алгоритмов, часто сочетающих операции разного типа. Новый SM выполняет за такт 128 операций FP32 или 64 FP32 + 64 INT32. Изменена структура кэша, чтобы обеспечить удвоение пропускной способности кэш-памяти L1: 128 байт/такт в Ampere против 64 байтов/такт в Turing. Общая пропускная способность L1 для GeForce RTX 3080 составляет 219 ГБ/с против 116 ГБ/с у GeForce RTX 2080 Super.
Опираясь на известные данные о 10496 потоковых процессорах FP32, мы получаем 82 активных SM. Отсюда можно вычислить количество других блоков — 328 текстурных блока, 328 тензорных ядра и 82 ядра RT. При 7 кластерах общее количество вычислительных блоков должно быть выше, и мы имеет типичную ситуацию, когда в топовом GPU часть SM отключена. Судя по приведенной выше иллюстрации тут 12 SM на кластер, что дает 84 SM и 10752 потоковых процессора. Нельзя исключать, что по мере совершенствования техпроцесса в будущем мы увидим новый Titan на полноценном процессоре GA102.
Если провести аналогичный анализ для GeForce RTX 3070 и GA104 с 5888 потоковыми процессорами, то получим 46 SM, что намекает на конфигурацию из 48 SM (4 GPC x 12 SM) при 6144 потоковых процессорах. Это неплохо согласуется со слухами о наличии некоей видеокарты GeForce RTX 3070 Ti.
Старшие видеокарты оснащены новой памятью GDDR6X, разработанной Micron для NVIDIA. У GeForce RTX 3090 эффективная частота обмена данных модулей GDDR6X соответствует 19500 МГц. При этом видеокарта оснащена 24 ГБ видеобуфера на 384-битной шине. В GeForce RTX 3080 последняя урезана до 320 бит, а объем видеобуфера GDDR6X уменьшен до 10 ГБ при частоте 19000 МГц. Младшая видеокарта GeForce RTX 3070 работает с 8 ГБ памяти GDDR6 на 256-битной шине.
Характеристики видеокарт GeForce RTX 3090, GeForce RTX 3080 и GeForce RTX 3070
| Видеоадаптер | GeForce RTX 3090 | GeForce RTX 3080 | GeForce RTX 3070 | GeForce RTX 2080 Ti | GeForce RTX 2080 Super | GeForce RTX 2080 |
|---|---|---|---|---|---|---|
| Ядро | GA102 | GA102 | GA104 | TU102 | TU104 | TU104 |
| Количество транзисторов, млн. шт | 28000 | 28000 | 17000 | 18600 | 13600 | 13600 |
| Техпроцесс, нм | 8 | 8 | 8 | 12 | 12 | 12 |
| Площадь ядра, кв. мм | 627 | 627 | 450 | 754 | 545 | 545 |
| Количество потоковых процессоров CUDA | 10496 | 8704 | 5888 | 4352 | 3072 | 2944 |
| Количество тензорных ядер | 328 | 272 | 184 | 544 | 384 | 368 |
| Количество ядер RT | 82 | 68 | 46 | 68 | 46 | 46 |
| Количество текстурных блоков | 328 | 272 | 184 | 272 | 192 | 184 |
| Количество блоков рендеринга | 96 | 88 | 64 | 88 | 64 | 64 |
| Базовая частота ядра, МГц | 1395 | 1440 | 1500 | 1350 | 1650 | 1515 |
| Частота Boost, МГц | 1695 | 1710 | 1725 | 1545 | 1815 | 1710 |
| Шина памяти, бит | 384 | 320 | 256 | 352 | 256 | 256 |
| Тип памяти | GDDR6X | GDDR6X | GDDR6 | GDDR6 | GDDR6 | GDDR6 |
| Частота памяти, МГц | 19500 | 19000 | 16000 | 14000 | 15500 | 14000 |
| Объём памяти, ГБ | 24 | 10 | 8 | 11 | 8 | 8 |
| Поддерживаемая версия DirectX | 12 Ultimate (12_2) | 12 Ultimate (12_2) | 12 Ultimate (12_2) | 12 Ultimate (12_2) | 12 Ultimate (12_2) | 12 Ultimate (12_2) |
| Интерфейс | PCI-E 4.0 | PCI-E 4.0 | PCI-E 4.0 | PCI-E 3.0 | PCI-E 3.0 | PCI-E 3.0 |
| Мощность, Вт | 350 | 320 | 220 | 250 | 250 | 225 |
| Дата выхода | 17 сентября 2020 | 24 сентября 2020 | ? | 27 сентября 2018 | 23 июля 2019 | 20 сентября 2018 |
| Цена MSRP | $1499 | $699 | $499 | $999 | $699 | $799 |
И немного красивых цифр, характеризующих производительность. При прямом сравнении GeForce RTX 3080 с видеоадаптером-предшественником GeForce RTX 2080 Super имеем увеличение производительности шейдерных блоков в 2,7 раз, рост операций по расчету трассировки в 1,7 раз, а тензорная производительность выше в 2,7 раз.

Для наглядности можно привести еще одну таблицу с примерной пиковой производительностью новых и старых GeForce RTX.
| Видеоадаптер | GeForce RTX 3090 | GeForce RTX 3080 | GeForce RTX 3070 | GeForce RTX 2080 Ti | GeForce RTX 2080 Super |
|---|---|---|---|---|---|
| FP32 TFLOPS | 36 | 30 | 20 | 13,5 | 11 |
| RT-TFLOPS | 69 | 58 | 40 | 42 | 34 |
| Tensor RT-TFLOPS | 285 | 238 | 163 | 108 | 89 |
Дополнительно отметим, что ранее NVIDIA говорила о неких операциях RTX-OPS, а теперь оперирует немного иными данными производительности трассировки RT-TFLOPS. Поэтому цифры в новых слайдах отличаются от тех, что указывались ранее.
Все GPU Ampere производятся на заводах Samsung по специальному 8-нм техпроцессу, разработанному совместно с NVIDIA. Примечательно, что процессоры A100 выпускаются на TSMC 7-нм. При всех оптимизациях GA102 разросся до 28 млрд. транзисторов вместо 18,6 млрд. у TU102. И хотя площадь нового процессора меньше, его тепловыделение и энергопотребление серьезно возросло. Для GeForce RTX 3090 заявлен TGP (Total Graphics Power) на уровне 350 Вт, для GeForce RTX 3080 это 320 Вт, а GeForce RTX 3070 ограничится значением в 220 Вт.
Это новый вызов для проектировщиков систем охлаждения. И хотя большинство партнеров пошло традиционным путем, создавая «бутерброды» с толстым радиатором и вентиляторами над ним, сама NVIDIA представила оригинальные референсные решения с необычным кулером. Охлаждение старших видеоадаптеров использует конструкцию с крупными вентиляторами на лицевой и задней стороне. Все остальное пространство занимает радиатор с разнонаправленными ребрами, в отводе тепла от GPU задействовано несколько тепловых трубок.


Двухстороннее расположение вентиляторов не только улучшает продуваемость радиатора, но и правильно организует воздушные потоки внутри корпуса.
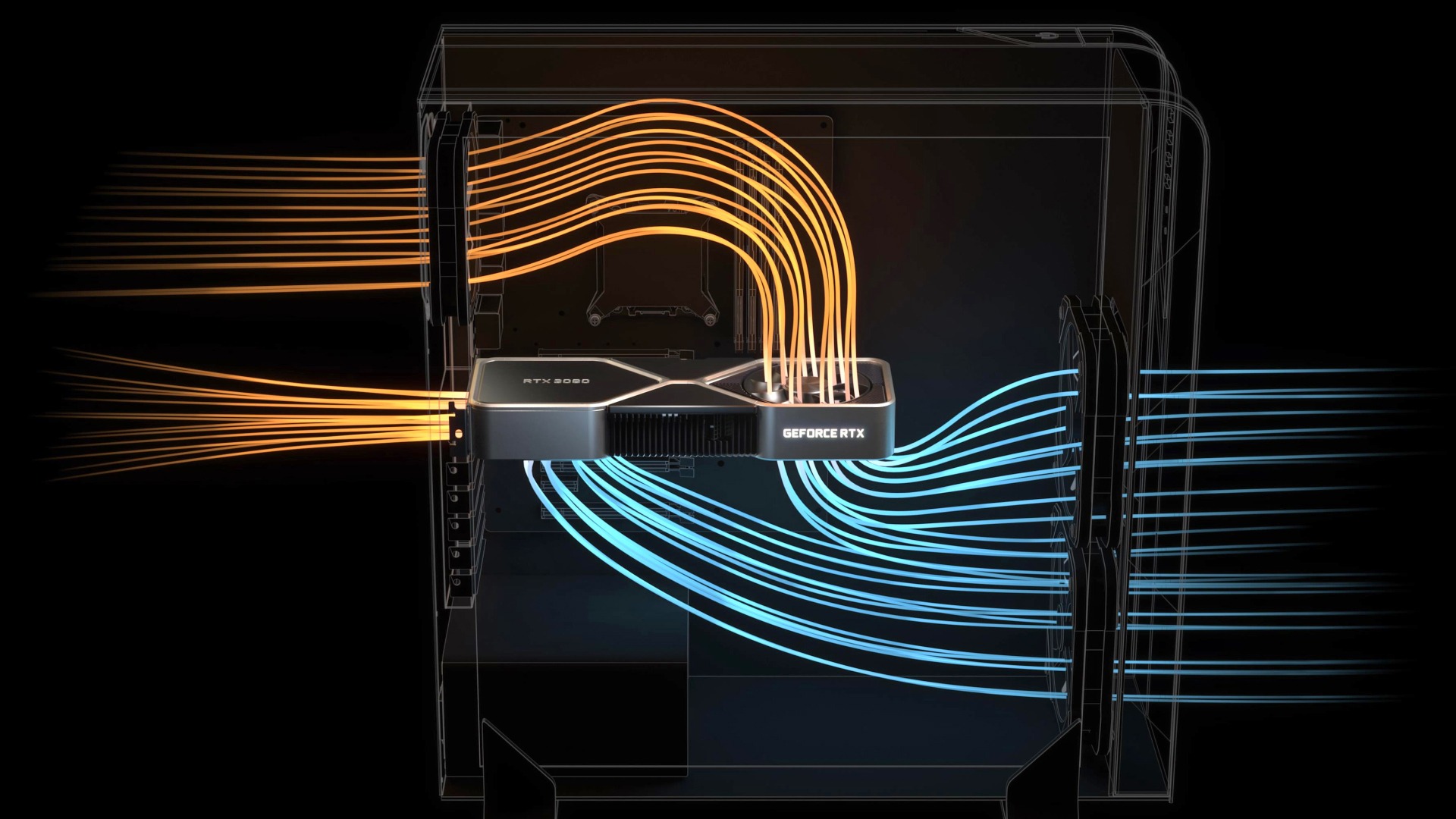
Наглядно конструкция охлаждения продемонстрирована в видеоролике:
Кулер референсной GeForce RTX 3090 занимает три слота расширения, остальные карты ограничены двухслотовым форматом. GeForce RTX 3070 меньше в размерах и предполагает одностороннее расположение вентиляторов.

NVIDIA реализовала новый компактный разъем питания на 12 контактов. В нереференсных продуктах распаяно два разъема по 8 контактов, что позволяет подключать видеокарты стандартными кабелями.
Если говорить о старших видеокартах от партнеров NVIDIA, то это зачастую трехслотовые варианты с тремя вентиляторами. В качестве примера можно взглянуть на ASUS TUF Gaming RTX 3090.

Все референсные видеокарты оснащены портом HDMI 2.1 и тремя разъемами DisplayPort 1.4a. Ampere получит новый блок обработки видео NVENC 7, на что намекает заявленная поддержка режима 8K для аппаратного захвата видео через ShadowPlay. То есть новые видеокарты могут не только выводить картинку в 8K, но и позволяют записывать игровой процесс в 8K HDR с аппаратным кодированием на GPU.








